
部分电商平台为防止爬虫竟然这样做?
- 初步介绍 此次内容涉及到的电商平台:wish,它是一款国外电商网站,主要业务在移动端,类似于国内的拼XX; URL链接:www.wish.com;
- 爬取内容
- 产品信息:产品名称,店铺名称,价格,评论数,评分;
- 评论信息;
- 开始爬虫
- 先做一个URL解析
 主页面能看到的信息就只有价格,商品名称,店铺名称,评论数,没有评分;
主页面能看到的信息就只有价格,商品名称,店铺名称,评论数,没有评分;  评分在另一个二级页面,但是URL链接没变;用xpath定位也不行。好在我通过索引定位到了他的value值也就是评级,发现此处隐藏了一大串商品信息,真是煞费苦心
评分在另一个二级页面,但是URL链接没变;用xpath定位也不行。好在我通过索引定位到了他的value值也就是评级,发现此处隐藏了一大串商品信息,真是煞费苦心  问题来了,通过xpath虽说可以定位爬取这一串信息,但怎么截取自己想要的数据;没错,用正则;
问题来了,通过xpath虽说可以定位爬取这一串信息,但怎么截取自己想要的数据;没错,用正则;
def parge_page(url):
response = requests.get(url=url, headers=headers)
# print(response) #测试一下看看也没有请求到网页
text = response.text
html = etree.HTML(text)
value = html.xpath('.//script[@type="application/ld+json"]/text()') #定位匹配所有值
rating_value = re.findall("\d+\.\d+",value)[0] # 匹配评级
print(rating_value)
使用正则,出现如下错误:
 意思是不是字符串对象不能使用正则,那该怎么办呢?首先通过 type来判断此内容的数据类型;
意思是不是字符串对象不能使用正则,那该怎么办呢?首先通过 type来判断此内容的数据类型;
value = html.xpath('.//script[@type="application/ld+json"]/text()') #定位匹配所有值
print(type(value))
然后通过json包转换数据类型;
str_value = json.dumps(value)
字符串类型转换成功;
value = html.xpath('.//script[@type="application/ld+json"]/text()') #定位匹配所有值
str_value = json.dumps(value)
rating_value = re.findall("\d+\.\d+",str_value)[0] # 匹配评级
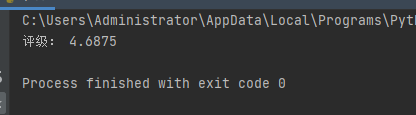
print("评级:",rating_value)
这样就能得到评级内容了,如下图;
 其他信息以此类推,使用正则来匹配想要的数据;
其他信息以此类推,使用正则来匹配想要的数据;

