
本文目录
🚁前言
- 🚁前言
- 🚁目的
- 🚁准备
- 🚁数据解析
- 🚁获取网页
- 🚁数据展示(pyecharts)
- 🚁完整源码
- 🚁成果
本人没事喜欢研究下理财,毕竟那点工资想实现经济自由,不太现实!基金也好,股票也罢,都具有一定的风险程序,稍有不慎,血本无归😖,大家不要轻易冒险,赚钱不易,通过此篇文章,分享一下自己平时一些研究方法
🚁目的目的:爬取的数据要达到什么效果?能帮助我们解决什么问题?首先需要了解一些基本的股票知识:成交量,当前成交价,换手率,涨跌幅…等等一些基本的股票数据名词,我们了解这些数据之后,是不是就明白要爬什么了,这些数据能够帮助我们快速了解一支股票的近期形式。
🚁准备-
数据平台(爬取的网站) 找了很久,也是通过一些朋友推荐的一款PC也能看股票的平台
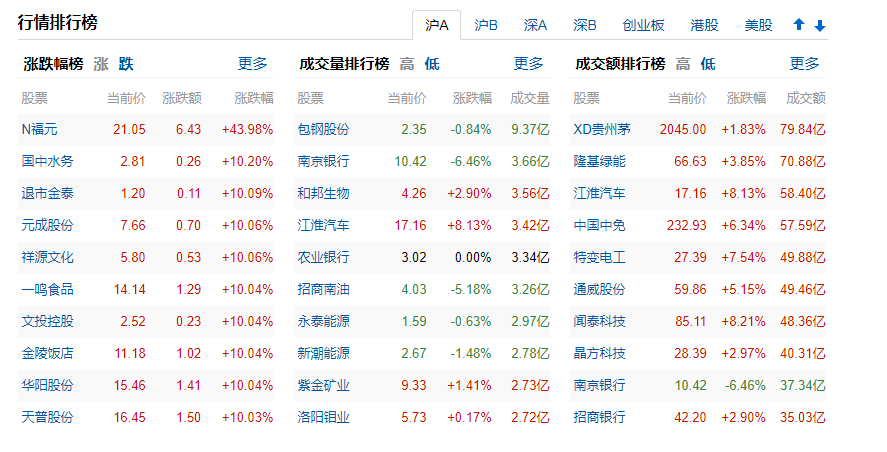
-
爬虫手段(工具) request: 具我检测,好像没有发现反爬手段,所以这里就可以放心使用request
-
可视化展示(pyecharts)
官方说明 Echarts是一个由百度开源的数据可视化,凭借着良好的交互性,精巧的图表设计,得到了众多开发者的认可。而Python 是一门富有表达力的语言,很适合用于数据处理。当数据分析遇上数据可视化时,pyecharts诞生了。Echarts是用JS来写的,而我们使用pyecharts则可以使用Python来调用里面的API。 安装
pip install pyecharts
- 老样子,调式!点击沪深一览,跳出来一个网页信息,点进去一看,发现
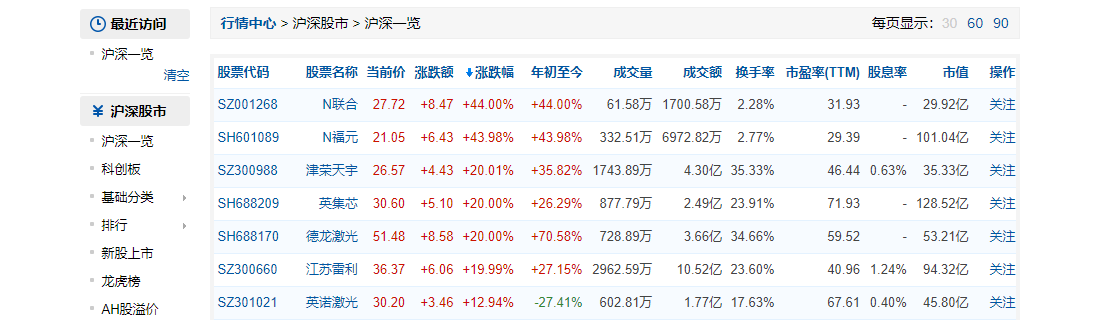
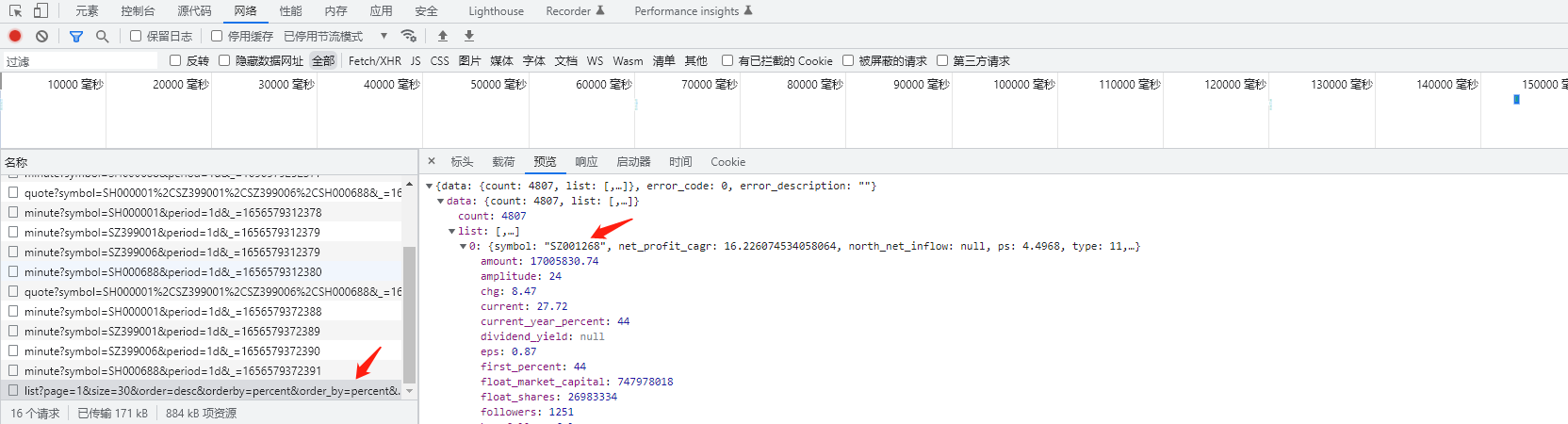
大家有没有发现呢?下面json数据与上面排行数据一致,是不是又帮我省了提取的步骤,真是良心平台,我们请求这个网页,看看是什么样子  哈哈,看来还真是,这样我们就能直接提取了,不错不错。上代码:
哈哈,看来还真是,这样我们就能直接提取了,不错不错。上代码:
def parse(res):
for data in res['data']['list']:
# 股票代码
symbol = data['symbol']
# 股票名称
name = data['name']
# 当前价
current = data['current']
# 涨跌额
chg = data['chg']
if chg:
if float(chg) > 0:
chg = "+" + str(chg)
else:
chg = str(chg)
# 涨跌幅
percent = str(data['percent']) + "%"
# 年初至今
current_year_percent = str(data['current_year_percent']) + "%"
# 成交量
volume = data["volume"]
# 成交额
amount = data['amount']
# 换手率
turnover_rate = str(data['turnover_rate']) + "%"
# 市盈(TTM)
pe_ttm = data['pe_ttm']
# 股息率
dividend_yield = data['dividend_yield']
if dividend_yield:
dividend_yield = str(dividend_yield) + "%"
else:
dividend_yield = None
# 市值
market_capital = data['market_capital']
def spider():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
}
for i in range(1, 10):
print("=========正在爬取第" + str(i) + "页数据==========")
# 拼接url,注意要使用 str
url = "https://xueqiu.com/service/v5/stock/screener/quote/list?page=" + str(
i) + "&size=30&order=desc&order_by=amount&exchange=CN&market=CN&type=sha&_=1601168743543"
# 数据返回格式为json,所以要使用.json(),方便之后的数据获取
response = requests.get(url=url, headers=headers).json()
parse(response)
def echarts():
# 读取csv文件
data_df = pd.read_csv(path)
df = data_df.dropna()
df1 = df[['股票名称', '涨跌额']]
# print(df1)
# 取前30条数据
df2 = df1.iloc[:30]
# print(list(df2['成交量'].values))
html = (
Bar(init_opts=opts.InitOpts(width='100%', height="720px", page_title="股票数据可视化")).add_xaxis(
list(df2['股票名称'].values))
.add_yaxis('今日趋势', list(df2['涨跌额'].values))
.set_global_opts(
title_opts=opts.TitleOpts(title="今日涨跌幅"),
datazoom_opts=opts.DataZoomOpts()
)
.render("股票数据图.html")
)
return html
import requests
import csv
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar
# 保存csv
path = '今日股票趋势.csv'
file = open(path, mode="w", encoding='utf-8', newline="")
csv_f = csv.DictWriter(file, fieldnames=['股票代码', '股票名称', '当前价', '涨跌额', '涨跌幅', '年初至今', '成交量', '成交额', '换手率',
'市盈(TTM)', '股息率', '市值'])
# 写入表头
csv_f.writeheader()
def parse(res):
for data in res['data']['list']:
# 股票代码
symbol = data['symbol']
# 股票名称
name = data['name']
# 当前价
current = data['current']
# 涨跌额
chg = data['chg']
if chg:
if float(chg) > 0:
chg = "+" + str(chg)
else:
chg = str(chg)
# 涨跌幅
percent = str(data['percent']) + "%"
# 年初至今
current_year_percent = str(data['current_year_percent']) + "%"
# 成交量
volume = data["volume"]
# 成交额
amount = data['amount']
# 换手率
turnover_rate = str(data['turnover_rate']) + "%"
# 市盈(TTM)
pe_ttm = data['pe_ttm']
# 股息率
dividend_yield = data['dividend_yield']
if dividend_yield:
dividend_yield = str(dividend_yield) + "%"
else:
dividend_yield = None
# 市值
market_capital = data['market_capital']
shares_dict = {'股票代码': symbol, '股票名称': name, '当前价': current,
'涨跌额': chg, '涨跌幅': percent, '年初至今': current_year_percent,
'成交量': volume, '成交额': amount, '换手率': turnover_rate,
'市盈(TTM)': pe_ttm, '股息率': dividend_yield,
'市值': market_capital}
csv_f.writerow(shares_dict)
def spider():
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.0.0 Safari/537.36"
}
for i in range(1, 10):
print("=========正在爬取第" + str(i) + "页数据==========")
# 拼接url,注意要使用 str
url = "https://xueqiu.com/service/v5/stock/screener/quote/list?page=" + str(
i) + "&size=30&order=desc&order_by=amount&exchange=CN&market=CN&type=sha&_=1601168743543"
# 数据返回格式为json,所以要使用.json(),方便之后的数据获取
response = requests.get(url=url, headers=headers).json()
parse(response)
def echarts():
# 读取csv文件
data_df = pd.read_csv(path)
df = data_df.dropna()
df1 = df[['股票名称', '涨跌额']]
# print(df1)
# 取前30条数据
df2 = df1.iloc[:30]
# print(list(df2['成交量'].values))
html = (
Bar(init_opts=opts.InitOpts(width='100%', height="720px", page_title="股票数据可视化")).add_xaxis(
list(df2['股票名称'].values))
.add_yaxis('今日趋势', list(df2['涨跌额'].values))
.set_global_opts(
title_opts=opts.TitleOpts(title="今日涨跌幅"),
datazoom_opts=opts.DataZoomOpts()
)
.render("股票数据图.html")
)
return html
if __name__ == '__main__':
spider()
echarts()
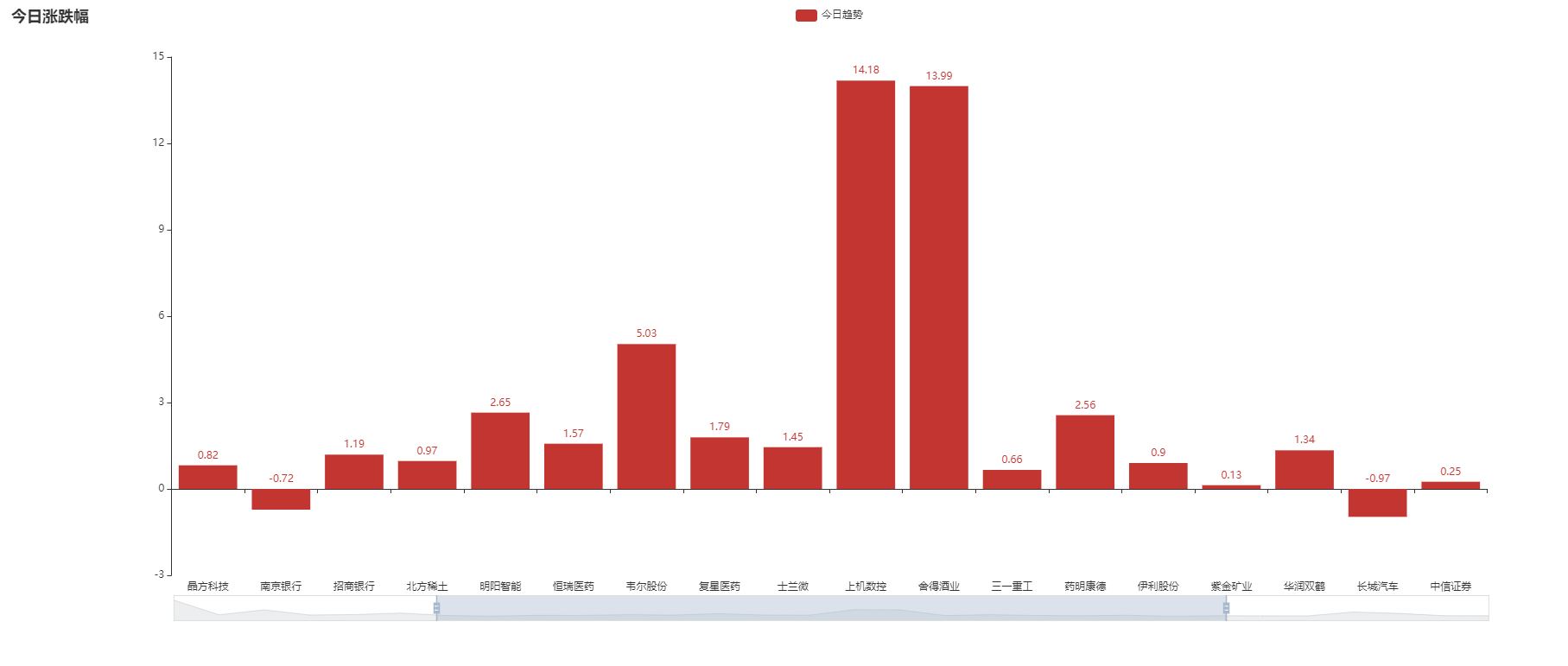 大功告成,大家可以练手玩玩!!!
大功告成,大家可以练手玩玩!!!
点关注不迷路,本文章若对你有帮助,烦请三连支持一下 ❤️❤️❤️ 各位的支持和认可就是我最大的动力❤️❤️❤️


