
本文目录
🔍scrapy-redis简介
- 🔍scrapy-redis简介
- 🚁scrapy-redis核心思想
- 🚁scrapy-redis安装
- 🚁创建爬虫项目
- 🚁创建爬虫文件
- 🚁数据解析
- 🚁爬取数据
- 🚁封装数据
- 🚁存储数据
- 🚁添加爬虫任务
- 🚁设置
- 🚁成果
-
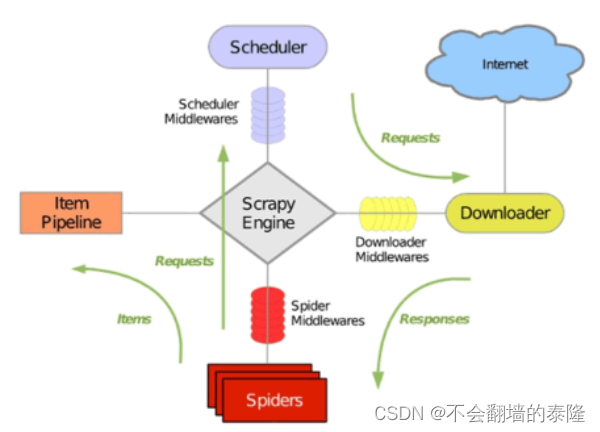
官方架构
-
Slaver(从)从Master(主)拿到爬取任务(Request、url)进行数据抓取,Slaver抓取数据的同时,产生新任务的Request便提交给 Master(主) 处理
-
Master(主)负责将未处理的Request去重和任务分配,将处理后的Request加入待爬队列,并且存储爬取的数据。
说白了,就是利用redis机制,实现 request 的去重,多个爬虫分享一个 request 队列,将 scrapy 从单台机器扩展为多台机器
🚁scrapy-redis安装pip install scarpy-redis
🚁创建爬虫项目scrapy startproject amazon
🚁创建爬虫文件scrapy genspider -t crawl amazon_spider
🚁数据解析-
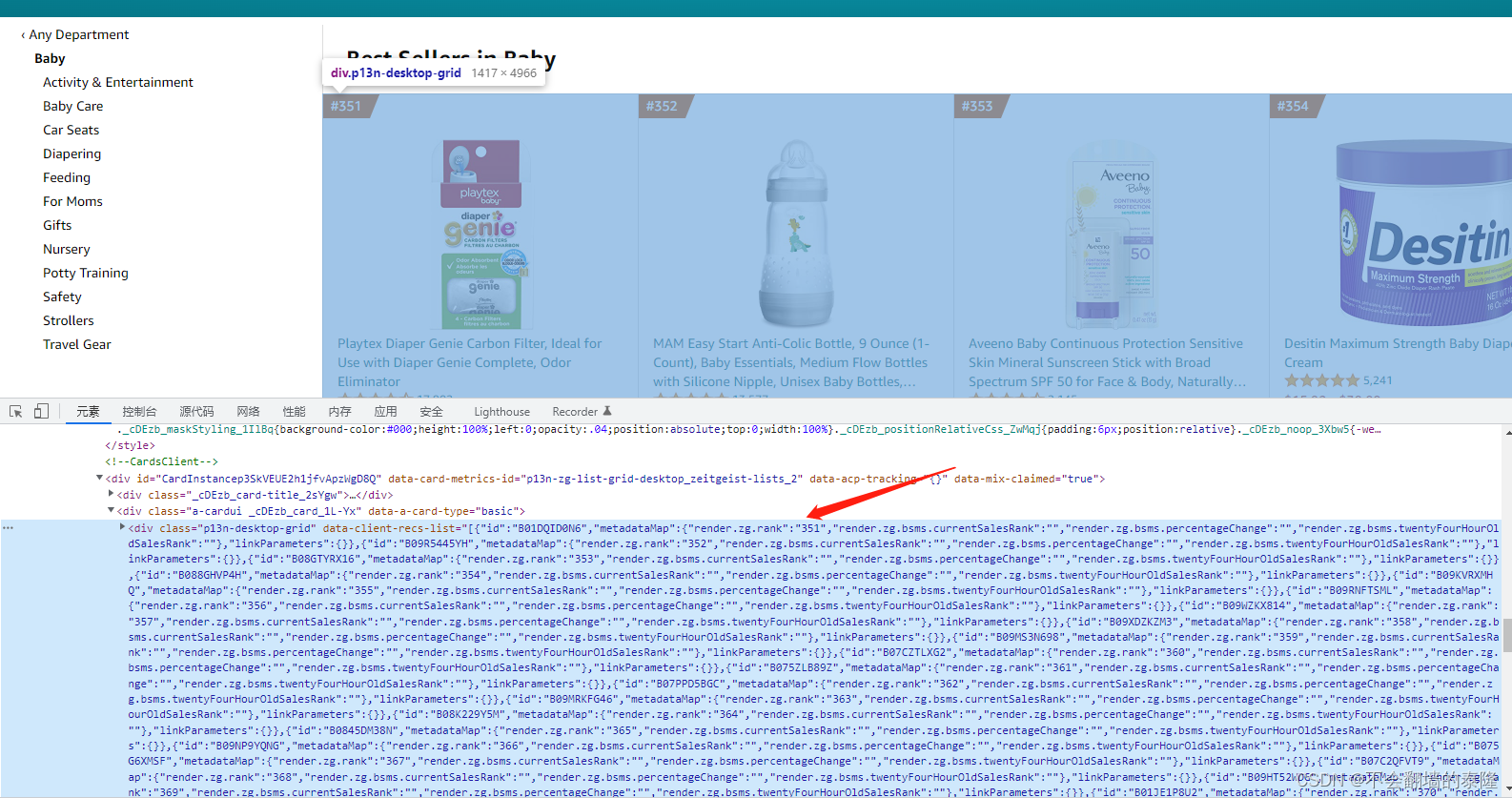
据我分析,爬取的页面是通过js加载的,通过下拉才能获取到全部listing,需要借助selenium,效率不高,如果爬取量较大,不推荐使用
-
我们仔细看,标签中有存放所有的ASIN,只不过转换成了json格式,我们通过转换来得到所有asin,后续通过拼接url来爬取,好在亚马逊所有链接规则都一样
amazon_spider.py
import re
from scrapy_redis import spiders
import json
import datetime
from ..items import AmazonItem
class Amazon_SpiderSpider(spiders.RedisSpider):
name = 'amazon_spider'
redis_key = 'amazon:start_urls' #指定redis_key
def parse(self, response):
asin = response.xpath('//div[@class="p13n-desktop-grid"]/@data-client-recs-list').extract() # 获取所有asin
category = response.xpath('//span[@class="_p13n-zg-nav-tree-all_style_zg-selected__1SfhQ"]/text()').extract() #获取类目
data = json.loads(asin[0])
for ca in category:
for da in data:
#1、解析
asin = da['id']
rank = da['metadataMap']['render.zg.rank'] # 排名
url = f'https://www.amazon.com/dp/{asin}?th=1' # 构造完整链接
item = TaocheItem()
item['asin'] = asin
item['rank'] = rank #排名
item['url'] = url # 链接
item['cat'] = ca # 类目
yield scrapy.Request(url=url, callback=self.parse_detail, meta={'item': item})
详情页
def parse_detail(self, response):
meta = response.meta # 接收上面传过来的meta字典
item = meta['item']
title = \
re.findall('(.*?)', response.text)[
0].strip(" ") \
if re.findall('(.*?)',
response.text) else ''
# 价格
if response.xpath('.//span[@class="a-offscreen"]/text()'):
price = response.xpath('.//span[@class="a-offscreen"]/text()').extract()[0].strip('$')
elif response.xpath('//span[@class="_p13n-desktop-sims-fbt_price_p13n-sc-price__bCZQt"]/text()'):
price = response.xpath('//span[@class="_p13n-desktop-sims-fbt_price_p13n-sc-price__bCZQt"]/text()').extract()[0].strip('$')
else:
price = ''
# 星级
stars = response.xpath('//*[@id="acrPopover"]/span[1]/a/i[1]/span[1]/text()').extract()[0].split(" ")[0] \
if response.xpath('//*[@id="acrPopover"]/span[1]/a/i[1]/span[1]/text()') else ''
# 评论数
rating_value = response.xpath('//*[@id="acrCustomerReviewText"]/text()').extract()[0].split(" ")[0].replace(',', '') \
if response.xpath('//*[@id="acrCustomerReviewText"]/text()') else ''
# 主图
if response.xpath('.//div[@id="imgTagWrapperId"]/img/@src'):
zhu_img = response.xpath('.//div[@id="imgTagWrapperId"]/img/@src').extract()
elif response.xpath('//*[@id="landingImage"]/@src'):
zhu_img = response.xpath('//*[@id="landingImage"]/@src').extract()
else:
zhu_img = ''
item['title'] = title
item['img'] = zhu_img
item['price'] = price
item['start'] = stars
item['rating_value'] = rating_value
yield item
item.py
import scrapy
class AmazonItem(scrapy.Item):
# define the fields for your item here like:
asin = scrapy.Field() #
rank = scrapy.Field() #大类
title = scrapy.Field() #标题
price = scrapy.Field() # 价格
stars = scrapy.Field() # 星级
rating_value = scrapy.Field() #评论数
cat = scrapy.Field() # 类目
url = scrapy.Field() #aisn链接
img = scrapy.Field() #主图
pipenlines.py
from scrapy.utils.project import get_project_settings
import pymysql.cursors
class MongoPipeline:
def __init__(self):
settings = get_project_settings() #mysql配置
self.connect = pymysql.Connect(
host=settings["HOST"],
port=settings["PORT"],
user=settings["USER"],
passwd=settings["PASSWD"],
db=settings["DB"],
charset='utf8mb4'
)
# 获取游标
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
data = dict(item)
sql = "REPLACE INTO boss_data.bo_all_best(asin,url,主图,title,price,星级,评论数,类目,排名)values(%s,%s,%s,%s,%s,%s,%s,%s,%s)"
value = (,data['asin'],data['url'],data['img'],data['title'],data['price'],data['stars'],data['rating_value'],data['cat'],
data['rank'])
self.cursor.execute(sql,value)
self.connect.commit()
return item
redis派发任务
import redis
import pandas as pd
CATEGORY_CODE = ['Best-Sellers-Automotive','Best-Sellers-Baby']
CATEGORY = ['automotive','baby-products']
#创建一个redis连接
redis_ = redis.Redis()
print('redis创建成功')
for caco,ca in zip(CATEGORY_CODE,TWO_CODE):
for i in range(1,9): #排行榜一个类目有8页
base_url = f'https://www.amazon.com/{caco}/zgbs/{ca}/ref=zg_bs_pg_?{i}_encoding=UTF8&pg={i}' # 构造类目链接
redis_.lpush('amazon:start_urls',base_url) # 添加数据
settings.py 特别强调:请求头中一定要带有Cookie,请求参数能全部加上就尽量加上,亚马逊很邪门,不然有些数据爬不到,会返回一些错误的数据
# 关闭协议
ROBOTSTXT_OBEY = False
#请求头
'DEFAULT_REQUEST_HEADERS': {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36',
'Cookie':'session-id=132-7820908-5512636; ubid-main=131-0969171-3937435; aws-target-data={"support":"1"}; aws-target-visitor-id=1640066826889-327584.38_0; aws-ubid-main=250-7108114-4482887; aws-session-id=000-0000000-0000000; aws-analysis-id=000-0000000-0000000; aws-session-id-time=1640067363l; i18n-prefs=USD; lc-main=en_US; s_nr=1650441678941-Repeat; s_vnum=2078274252676&vn=2; s_dslv=1650441678942; session-id-time=2082787201l; appstore-devportal-locale=zh_CN; _mkto_trk=id:365-EFI-026&token:_mch-aws.amazon.com-1640066827077-37141; aws-mkto-trk=id:112-TZM-766&token:_mch-aws.amazon.com-1640066827077-37141; aws_lang=cn; AMCVS_7742037254C95E840A4C98A6@AdobeOrg=1; s_cc=true; AMCV_7742037254C95E840A4C98A6@AdobeOrg=1585540135|MCIDTS|19151|MCMID|25398098771975688903309274459050119441|MCAAMLH-1655193582|3|MCAAMB-1655193582|RKhpRz8krg2tLO6pguXWp5olkAcUniQYPHaMWWgdJ3xzPWQmdj0y|MCOPTOUT-1654595982s|NONE|MCAID|NONE|vVersion|4.4.0; aws-userInfo-signed=eyJ0eXAiOiJKV1MiLCJrZXlSZWdpb24iOiJ1cy1lYXN0LTEiLCJhbGciOiJFUzM4NCIsImtpZCI6ImFhNDFkZjRjLTMxMzgtNGVkOC04YmU5LWYyMzUzYzNkOTEzYiJ9.eyJzdWIiOiIiLCJzaWduaW5UeXBlIjoiUFVCTElDIiwiaXNzIjoiaHR0cDpcL1wvc2lnbmluLmF3cy5hbWF6b24uY29tXC9zaWduaW4iLCJrZXliYXNlIjoidWVhVW11TnlIVG02am42TXZOTzhPajZOQ3hzMzVJVnp2dk0zaGQwaGNZQT0iLCJhcm4iOiJhcm46YXdzOmlhbTo6MTczMjg3OTA4ODk2OnJvb3QiLCJ1c2VybmFtZSI6Imd1b2xpeWluZyJ9.J_Pxsq-oHIwwEk23j86zM6OjWEu7Y_xe1SVigbVY3GVM9Ri7U30jkkQbMK0XZj4w3dudA4nJutx_QoMfvPyaSrq-z-abZA0i7Enlc9lOk2hj8tWmXCIP8HM6KSXQnYTl; aws-userInfo={"arn":"arn:aws:iam::173287908896:root","alias":"","username":"guoliying","keybase":"ueaUmuNyHTm6jn6MvNO8Oj6NCxs35IVzvvM3hd0hcYA\u003d","issuer":"http://signin.aws.amazon.com/signin","signinType":"PUBLIC"}; regStatus=registered; awsc-color-theme=light; awsc-uh-opt-in=optedOut; noflush_awsccs_sid=44efc26057037bfb3a76afb21553f47bd88a10ee4396ef03fb2a0725609e487e; aws-signer-token_us-east-1=eyJrZXlWZXJzaW9uIjoia0lYaHRyWi5POFhvLjFneThKS251dnVOMkdmLnNaekYiLCJ2YWx1ZSI6Ik5pcWFBcnR2RFpaK1dtSCtnb3gvZWZNNXFNWVNEcFBQVXU1NFZoaXdNMUU9IiwidmVyc2lvbiI6MX0=; aws-signer-token_us-west-2=eyJrZXlWZXJzaW9uIjoiTm5jSVdFQ0gubzYuMGlFS3VEZk9HbmdHVTZWX2JHU3IiLCJ2YWx1ZSI6IlMyK2NqOHU1SWRxdThOUityUGhQWklTSTBtVTdTSTRzQUN0Unp0VTdBbTg9IiwidmVyc2lvbiI6MX0=; s_sq=[[B]]; session-id-eu=259-5325582-3849510; ubid-acbuk=257-5013527-1544704; session-id-time-eu=2285315333l; x-amz-captcha-1=1654619359947279; x-amz-captcha-2=kdK+pRacBvV0/C2ON8VoCQ==; session-token="IjG7lRcnVW+CVUclLZ0yZFV9JFIco2e4bM7QLQoXVkn6Hhvm+Katu2747zcP93hofXpkcHHNQZIl4BPm1yoRhTildooVOy/uImskrmCJ0QbH0ORn1fDaJvydwrSapUmmHkoH23DI5rt2Uo8eFFfEQ3zrUsYDrw4di4qqF+b51SJwp65LjQcWFkJLWNQQkczZYu6QQYYRmTtwLSoXxJWWUA=="; csm-hit=tb:EJ3BAFMM9JN993D6ACQF+s-4ARBRR7G7XBJSYK1VHPS|1654616613057&t:1654616613057&adb:adblk_no'
},
#配置scrapy-redis调度器
'SCHEDULER' : "scrapy_redis.scheduler.Scheduler",
#配置url去重
'DUPEFILTER_CLASS' : "scrapy_redis.dupefilter.RFPDupeFilter",
#配置优先级队列
'SCHEDULER_QUEUE_CLASS' : 'scrapy_redis.queue.PriorityQueue',
#暂停爬虫
'SCHEDULER_PERSIST': True,
# reids链接
'REDIS_PORT' : 6379,
'REDIS_HOST':'localhost'#Master 从机需要更改为主机的ip,
ITEM_PIPELINES = {
'amazon.pipelines.AmazonPipeline': 300, #管道
}
'CONCURRENT_REQUESTS': 5, # 限制请求数 可加可不加,加了速度会变慢,不加有利于持续爬虫
'DOWNLOAD_DELAY': 0.5, #延迟0.5秒,防止爬虫过快被识别
// mysql配置
HOST = 'localhost'
PORT = 3306
USER = '****'
PASSWD = '***'
DB = '****'
启动爬虫
scrapy crawl amazon_spider

点关注不迷路,本文章若对你有帮助,烦请三连支持一下 ❤️❤️❤️ 各位的支持和认可就是我最大的动力 ❤️❤️❤️


