
我们首先打开网页做分析
 按下F12点击Network找到headers,将Cookie和User-agent复制下来,留着备用!
按下F12点击Network找到headers,将Cookie和User-agent复制下来,留着备用!
- 下面用requets做调式,能否获取到网页信息
import requests
def get_html(url):
cookie = 'ali_apache_id=11.134.216.25.1620641275908.387521.9; cna=hyANGQQpnwUCAXFZBo1X/gL1; _bl_uid=eekXnoe0ihCgpa1FCqstxaXlIdkv; _gcl_au=1.1.1881464747.1620641406; ali_apache_track=; _fbp=fb.1.1621326157853.591747728; aep_usuc_f=site=bra&c_tp=USD®ion=FR&b_locale=pt_BR; xman_t=d3qKco3s8ICw0nzaQKKtoS0U3oTdStKANNGzQcVE34kW5GawHBvg/8Wm4LzqG4xI; xman_f=fnzcTB4lMyXcsSfeOLZLF5TbjbvZnCw91SwcXqHWKK7CkNjRWPpgKzvfCNZ9xbOsS/SPDnilWQxS893RyPst+aDmE9cIkUu1pvV2cEdRTCqbr63Zf8uKfA==; _gid=GA1.2.2062164804.1627263915; xman_us_f=x_locale=pt_BR&x_l=1&x_c_chg=0&x_as_i=%7B%22cookieCacheEffectTime%22%3A1627270529699%2C%22isCookieCache%22%3A%22Y%22%2C%22ms%22%3A%220%22%7D&acs_rt=baf2bdbceea74f888cbbdd265264b7ab; xlly_s=1; acs_usuc_t=x_csrf=55vc73s5jut0&acs_rt=38423a3343ad45c8b2fd8041c440e02e; x5sec=7b2261652d676c6f64657461696c2d7765623b32223a223838373335363436356566383139623064376432343632616538356431663837434c4b6569496747454c6a4672704b346c71376833674577752f4f353950722f2f2f2f2f41513d3d227d; intl_locale=pt_BR; intl_common_forever=EZ/MhgYRW2l3kU7xfsuyidNeG/9B8oNGqiGWzG457Ix5vegmIyy/9A==; _m_h5_tk=ccb5c1ef7baef073e284453a0d30a16d_1627532837402; _m_h5_tk_enc=431c18c4496c660d8cea1a9ad4f23af5; XSRF-TOKEN=b6eae551-3789-4a09-8b34-2546192807c2; JSESSIONID=C750362F52F72C63AA239A47647FA8B3; tfstk=cJ5OB7qRUkqM33TdzOe3hCO1qyBOZK09mVtxMPzpowP8BHlAi-5lw1eYCEo99yC..; l=eBLVX5SPjAzjolMsBOfwnurza77OsIRAguPzaNbMiOCPOVC958yAB6hqONLpCnGVh6jMR3Rj4pR2BeYBqIvQ_uwxKn-yLLMmn; isg=BPX1p04g-Lbs4x2R4ctyrIJPBHGvcqmEz8EwaXcavGy7ThVAP8bFVZXMnBL4DsE8; _gat=1; _ga_VED1YSGNC7=GS1.1.1627524917.100.0.1627524917.0; _ga=GA1.1.1029832363.1620641406; aep_history=keywords%5E%0Akeywords%09%0A%0Aproduct_selloffer%5E%0Aproduct_selloffer%091005002282064002%0932854594058%091005002218370904%091005002061509198%094000771944644%094000801498680%0933035249510%094000771944644'
headers = {
'headers': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'Cookie': cookie
}
# 请求headers头
c = requests.get(url, headers=headers).content.decode('UTF-8') # 获取网页链接
print(c)
return c
if __name__ == '__main__':
url = 'https://pt.aliexpress.com/item/1005002278750230.html'
get_html(url)
结果我们是能获取到数据的! 
- 接下来我们用xpath截取我们想要的数据
 继续调式,简单抓下价格的xpath:
继续调式,简单抓下价格的xpath:  发现没有数据,我们用xpath插件验证一下,是否xpath写错了!
发现没有数据,我们用xpath插件验证一下,是否xpath写错了!  验证是有数据的,那就是爬取的网页信息与显示的不一样!
验证是有数据的,那就是爬取的网页信息与显示的不一样!
 从我们获取的网页源码中,他是有把数据都存放在data中,转换成了josn格式,我们只需要把这段数据提取出来,使用正则匹配!
从我们获取的网页源码中,他是有把数据都存放在data中,转换成了josn格式,我们只需要把这段数据提取出来,使用正则匹配!
import requests,re,json
def get_html(url):
cookie = 'ali_apache_id=11.134.216.25.1620641275908.387521.9; cna=hyANGQQpnwUCAXFZBo1X/gL1; _bl_uid=eekXnoe0ihCgpa1FCqstxaXlIdkv; _gcl_au=1.1.1881464747.1620641406; ali_apache_track=; _fbp=fb.1.1621326157853.591747728; aep_usuc_f=site=bra&c_tp=USD®ion=FR&b_locale=pt_BR; xman_t=d3qKco3s8ICw0nzaQKKtoS0U3oTdStKANNGzQcVE34kW5GawHBvg/8Wm4LzqG4xI; xman_f=fnzcTB4lMyXcsSfeOLZLF5TbjbvZnCw91SwcXqHWKK7CkNjRWPpgKzvfCNZ9xbOsS/SPDnilWQxS893RyPst+aDmE9cIkUu1pvV2cEdRTCqbr63Zf8uKfA==; _gid=GA1.2.2062164804.1627263915; xman_us_f=x_locale=pt_BR&x_l=1&x_c_chg=0&x_as_i=%7B%22cookieCacheEffectTime%22%3A1627270529699%2C%22isCookieCache%22%3A%22Y%22%2C%22ms%22%3A%220%22%7D&acs_rt=baf2bdbceea74f888cbbdd265264b7ab; xlly_s=1; acs_usuc_t=x_csrf=55vc73s5jut0&acs_rt=38423a3343ad45c8b2fd8041c440e02e; x5sec=7b2261652d676c6f64657461696c2d7765623b32223a223838373335363436356566383139623064376432343632616538356431663837434c4b6569496747454c6a4672704b346c71376833674577752f4f353950722f2f2f2f2f41513d3d227d; intl_locale=pt_BR; intl_common_forever=EZ/MhgYRW2l3kU7xfsuyidNeG/9B8oNGqiGWzG457Ix5vegmIyy/9A==; _m_h5_tk=ccb5c1ef7baef073e284453a0d30a16d_1627532837402; _m_h5_tk_enc=431c18c4496c660d8cea1a9ad4f23af5; XSRF-TOKEN=b6eae551-3789-4a09-8b34-2546192807c2; JSESSIONID=C750362F52F72C63AA239A47647FA8B3; tfstk=cJ5OB7qRUkqM33TdzOe3hCO1qyBOZK09mVtxMPzpowP8BHlAi-5lw1eYCEo99yC..; l=eBLVX5SPjAzjolMsBOfwnurza77OsIRAguPzaNbMiOCPOVC958yAB6hqONLpCnGVh6jMR3Rj4pR2BeYBqIvQ_uwxKn-yLLMmn; isg=BPX1p04g-Lbs4x2R4ctyrIJPBHGvcqmEz8EwaXcavGy7ThVAP8bFVZXMnBL4DsE8; _gat=1; _ga_VED1YSGNC7=GS1.1.1627524917.100.0.1627524917.0; _ga=GA1.1.1029832363.1620641406; aep_history=keywords%5E%0Akeywords%09%0A%0Aproduct_selloffer%5E%0Aproduct_selloffer%091005002282064002%0932854594058%091005002218370904%091005002061509198%094000771944644%094000801498680%0933035249510%094000771944644'
headers = {
'headers': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'Cookie': cookie
}
# 请求headers头
c = requests.get(url, headers=headers).text# 获取网页链接
html = c
# re匹配data数据
state = re.findall('data(.+)b',html,re.S)
str_data = json.dumps(state[0], indent=2) # 使用json转换字符串格式
states = re.sub(r'[/\\"]', "", str_data) # 剔除特殊符号
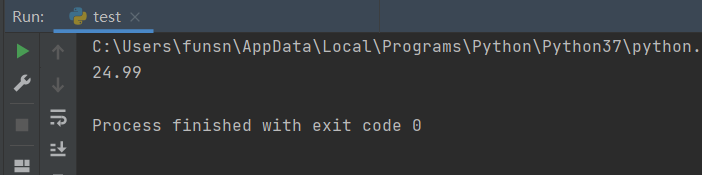
price = re.findall('\d+\.\d+', states)[0]
print(price)
return c
if __name__ == '__main__':
url = 'https://pt.aliexpress.com/item/1005002278750230.html'
get_html(url)

- 本文章若对你有帮助,烦请点赞,收藏,关注支持一下!
- 各位的支持和认可就是我最大的动力!

