本课程共五个章节,课程地址:
【Python爬虫教程】花9888买的Python爬虫全套教程2021完整版现分享给大家!(已更新项目)——附赠课程与资料_哔哩哔哩_bilibili
第二章- 数据解析概述
- 正则表达式
- re模块
- 手刃豆瓣TOP250电影信息
- bs4解析-HTML语法
- bs4解析-bs4模块安装和使用
- 抓取让你睡不着觉的图片
- xpath解析
- 抓取猪八戒数据
目录
第二章
(五)bs4解析-HTML语法
标签
属性
例子
(六)bs4解析-bs4模块安装和使用
安装
爬取新发地菜价
爬取广州江南果菜批发市场菜价(bs4)
(五)bs4解析-HTML语法首先需要了解一些 html 知识,再使用 bs4 去提取
HTML(Hyper Text Markup Language,超文本标记语言)是编写网页最基本也最核心的一种语言,其语法规则就是用不同的标签对网页上的内容进行标记,从而使网页显示出不同的展示效果
标签 不同标签表现出来的效果是不一样的
属性
不同标签表现出来的效果是不一样的
属性
在标签中还可以给出 xxx=xxx 这样的东西,通过 xxx=xxx 这种形式对标签进一步说明,这种语法在 html 中被称为标签的属性,且属性可以有很多个
You see my color
i love you
i don't love you
# h1:标签
# align:属性
# center:属性值
被标记的内容
如:周杰伦
# 想在网页里引入一张图片,这种标签自带闭合,即
![]() 同样的还有
同样的还有周杰伦
林俊杰
麻花藤
天老鸭
李多海
厉害多
xxxxx
# 通过标签名称来拿到数据
# div -> id:3 => 麻花藤
# div -> class:h4 => 李多海
# bs4:通过标签的特征来定位到我们想要的内容bs4 就是通过标签和属性去定位页面上的内容的
(六)bs4解析-bs4模块安装和使用 安装在 Terminal 里输入
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple bs4
bs4在使用的时候需要参照一些 html 的基本语法来进行使用
爬取新发地菜价http://www.xinfadi.com.cn/priceDetail.html
右键查看网页源代码,发现数据不在html里(跟教学视频有出入,网页改版了,这里不需要用到 bs4 模块)

参考这篇帖子:python获取新发地菜价信息_PGEva的博客-CSDN博客_爬取新发地菜价
打开抓包工具,可以在 Preview 里看到我们想要的数据都在这里:

从 Headers 里获取其 url 和 请求方式(为post):
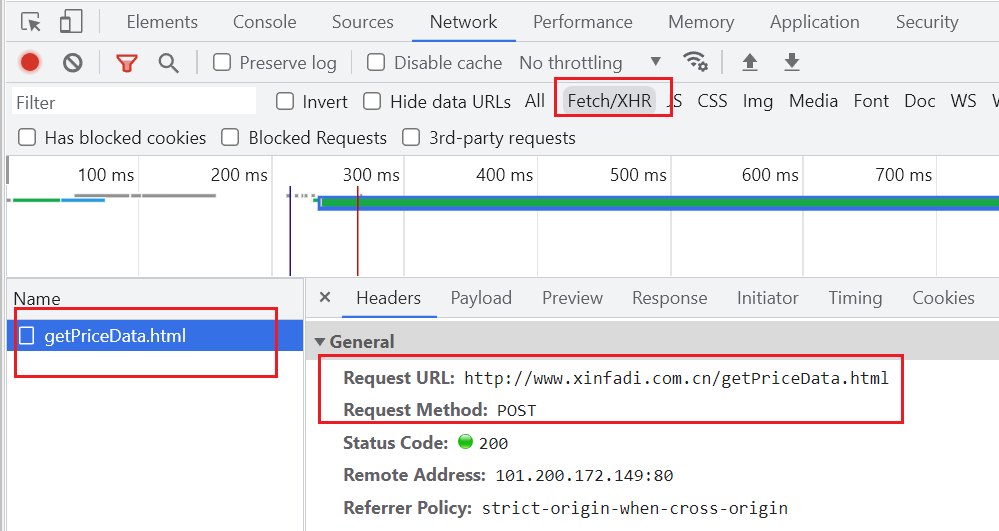
post 请求的话就找 Form Data 里的参数,构建字典:
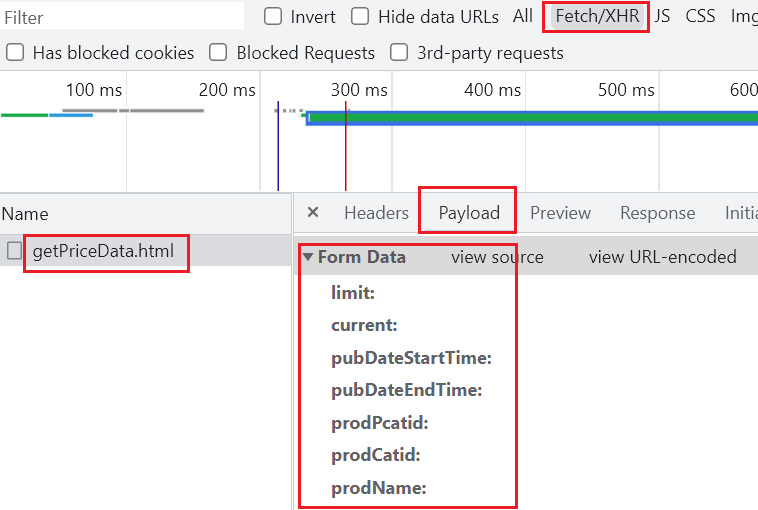
import requests
url = 'http://www.xinfadi.com.cn/getPriceData.html'
dat = {
"limit":"",
"current":"",
"pubDateStartTime":"",
"pubDateEndTime":"",
"prodPcatid":"",
"prodCatid":"",
"prodName":""
}
resp = requests.post(url,data=dat)
print(resp.json())
将爬取的内容保存到 csv 文件里:
all_count = int(resp.json()["count"])
limit = int(resp.json()["limit"])
all_page_number = int(all_count / limit)
with open("新发地菜价.csv", mode="a+", newline='',encoding="utf-8") as f:
csvwriter = csv.writer(f)
for i in range(1, all_page_number):
dat1 = {
"limit": limit,
"current": i,
"pubDateStartTime": "",
"pubDateEndTime": "",
"prodPcatid": "",
"prodCatid": "",
"prodName": "",
}
r1 = requests.post(url, data=dat)
list = resp.json()["list"]
count = list
for iter in list:
prodName = iter["prodName"] # 品名
avgPrice = iter["avgPrice"] # 平均价
highPrice = iter["highPrice"] # 最高价
lowPrice = iter["lowPrice"] # 最低价
place = iter["place"] # 产地
prodCat = iter["prodCat"] # 一级分类
pubDate = iter["pubDate"] # 发布日期
unitInfo = iter["unitInfo"] # 单位
csvwriter.writerow([prodName, avgPrice, highPrice, lowPrice, place, prodCat, pubDate, unitInfo])
f.close()
print("Over")
resp.close()完整代码:
import requests
import csv
url = 'http://www.xinfadi.com.cn/getPriceData.html'
dat = {
"limit":"",
"current":"",
"pubDateStartTime":"",
"pubDateEndTime":"",
"prodPcatid":"",
"prodCatid":"",
"prodName":""
}
resp = requests.post(url,data=dat)
# print(resp.json())
all_count = int(resp.json()["count"])
limit = int(resp.json()["limit"])
all_page_number = int(all_count / limit)
with open("新发地菜价.csv", mode="a+", newline='',encoding="utf-8") as f:
csvwriter = csv.writer(f)
for i in range(1, all_page_number):
dat1 = {
"limit": limit,
"current": i,
"pubDateStartTime": "",
"pubDateEndTime": "",
"prodPcatid": "",
"prodCatid": "",
"prodName": "",
}
r1 = requests.post(url, data=dat)
list = resp.json()["list"]
count = list
for iter in list:
prodName = iter["prodName"] # 品名
avgPrice = iter["avgPrice"] # 平均价
highPrice = iter["highPrice"] # 最高价
lowPrice = iter["lowPrice"] # 最低价
place = iter["place"] # 产地
prodCat = iter["prodCat"] # 一级分类
pubDate = iter["pubDate"] # 发布日期
unitInfo = iter["unitInfo"] # 单位
csvwriter.writerow([prodName, avgPrice, highPrice, lowPrice, place, prodCat, pubDate, unitInfo])
f.close()
print("Over")
resp.close()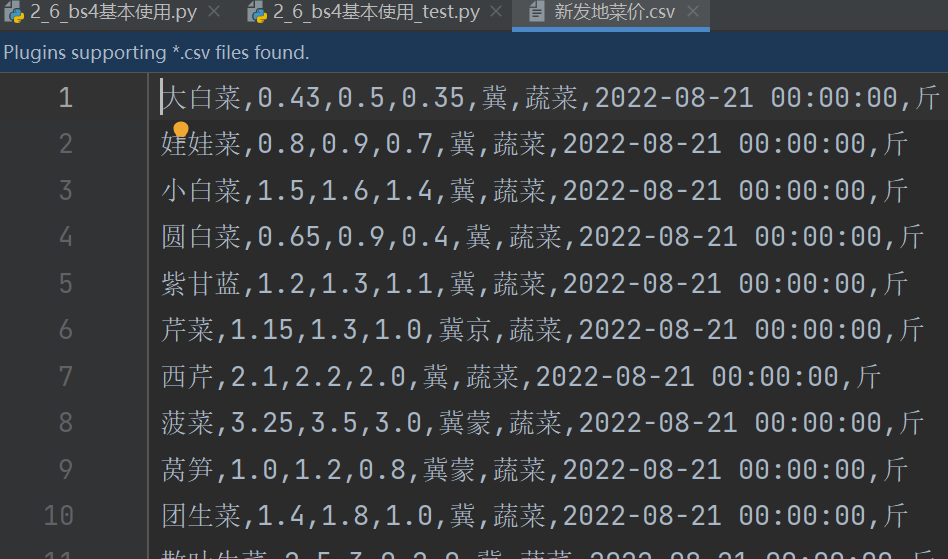
由于新发地网站改版了,数据不在页面源代码中了,不需要使用bs4模块。所以我另外找了一个相似的网站,该网站的数据嵌入在html中,以此网站作为案例来使用bs4模块爬取数据
爬取广州江南果菜批发市场菜价(bs4)广州江南果菜批发市场 批发市场 最大的水果批发市场 蔬菜批发市场 江南市场
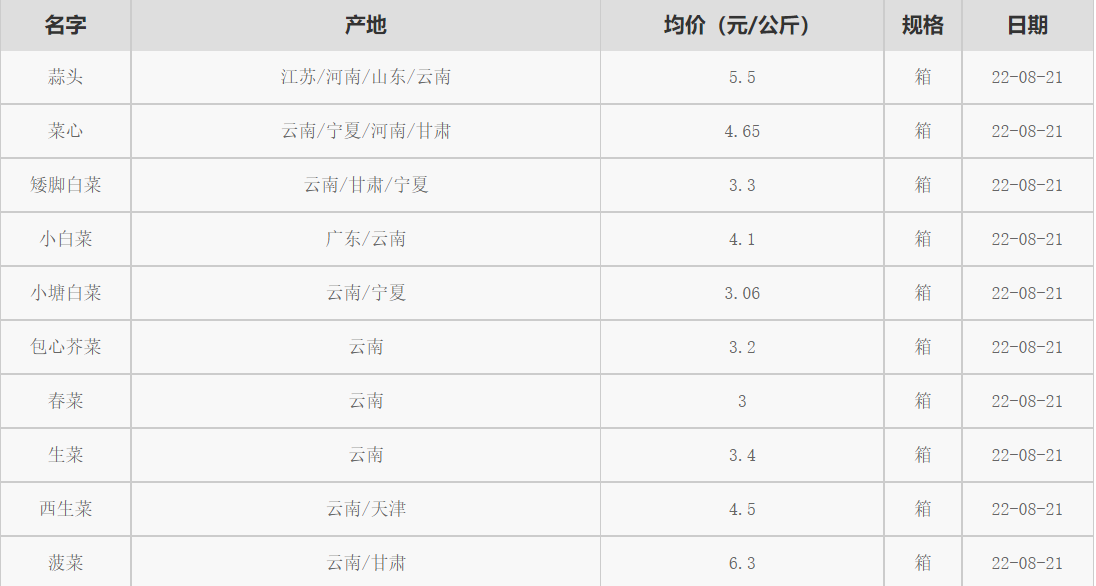
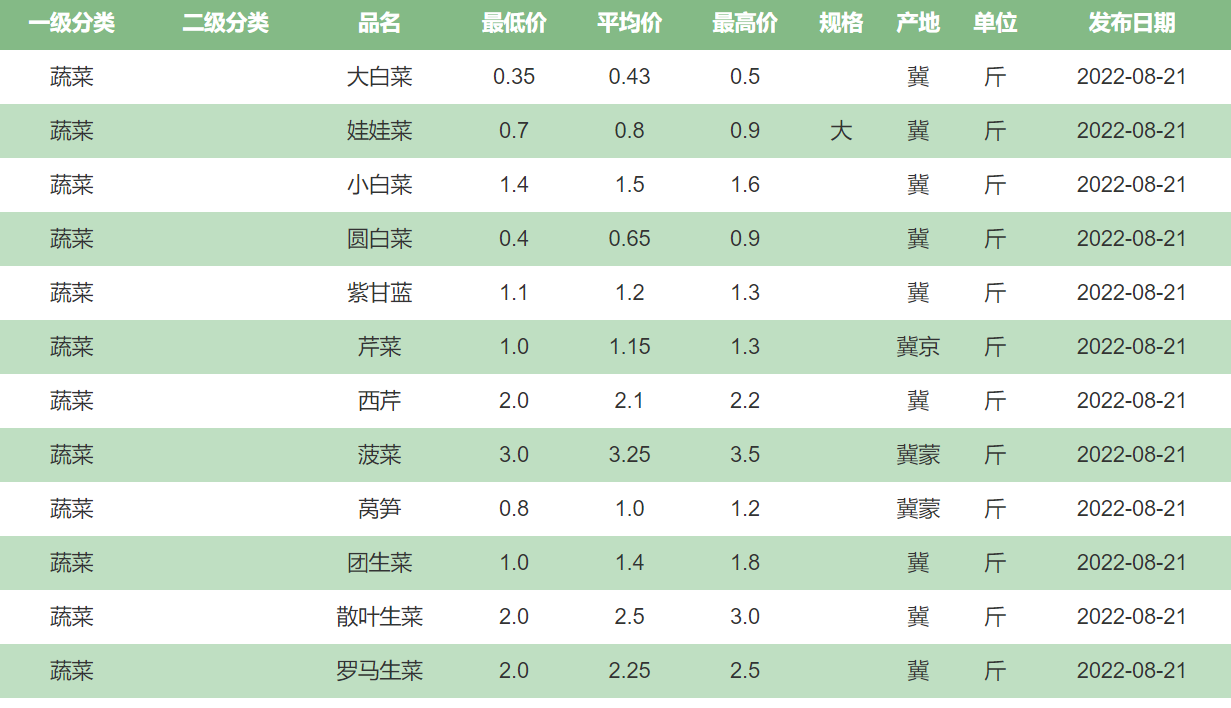
右键,查看网页源代码,可以看到数据是嵌入在 html 里的

故接下来的工作可以分为两步:
- 拿到页面源代码 见第一步
- 使用bs4进行解析,拿到数据 见第二步 ~ 第四步
第一步:拿到页面源代码
import requests
url = "http://www.jnmarket.net/import/list-1.html"
resp = requests.get(url)
print(resp.text)第二步:把页面源代码交给BeautifulSoup进行处理,生成bs对象
from bs4 import BeautifulSoup
# 使用bs4解析数据(两步)
# 1. 生成bs对象
page = BeautifulSoup(resp.text, "html.parser") # 指定html解析器第三步:从bs对象中查找数据(通过bs对象去检索页面源代码中的html标签)
BeautifulSoup对象获取html中的内容主要通过两个方法来完成:
- find()
- find_all()
 不论是 find 还是 find_all,参数几乎是一致的
不论是 find 还是 find_all,参数几乎是一致的
语法:find(标签, 属性=值) 意思是在页面中查找xxx标签,并且标签的xxx属性必须是xxx值
- 例如,find('div' , age=18) 含义就是在页面中查找div标签,并且属性age必须是18的这个标签
find_all() 用法和 find() 几乎一致。find() 查找一个,find_all() 查找页面中所有的
但是这种写法会有些问题,比如 html 标签中的 class 属性
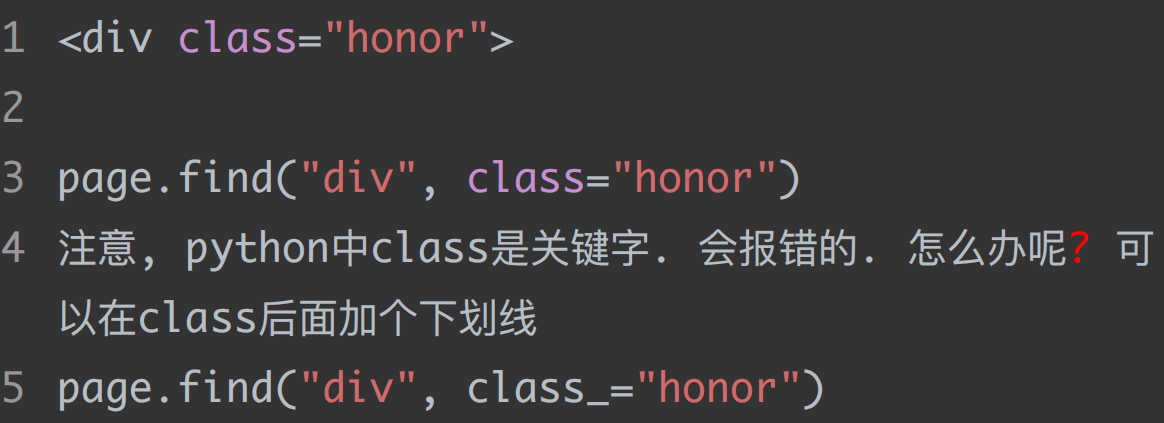
若属性名称与python中的关键字一样,可以在属性名称后面加上下划线_以区别
我们还可以使用第二种写法来避免出现此类问题:

继续回到正题:
- 数据都在这个table表格里,怎么提取呢? page.find("table")
- 可是页面中如果有多个table呢? 没错,还有一个特殊的class呢。通过 ctrl+f 搜索发现页面中只有这一个 price-table,也就是说,如果用 page.find("table",class_="price-table") 就一定能定位到这个表格

# 2. 从bs对象中查找数据
# find(标签, 属性=值):找第一个
# find_all(标签, 属性=值):找全部
# table = page.find("table",class_="price-table") # class是python中的关键字,加_以示区别
# 另一种写法:
table = page.find("table",attrs={"class":"price-table"}) # 和上一行是一个意思,此时可以避免class
# print(table)
# 不想要列名那一行(表头),只想要底下的数据,即拿到所有数据行
trs = table.find_all("tr")[1:] # tr是行的意思
for tr in trs: # 每一行
tds = tr.find_all("td") # td表示单元格。拿到每行中的所有td
# print(tds[0])
# 名字、产地、均价(元/公斤)、规格、日期
name = tds[0].text # .text表示拿到被标签标记的内容
place = tds[1].text
avg_price = tds[2].text
guige = tds[3].text
date = tds[4].text
print(name,place,avg_price,guige,date) 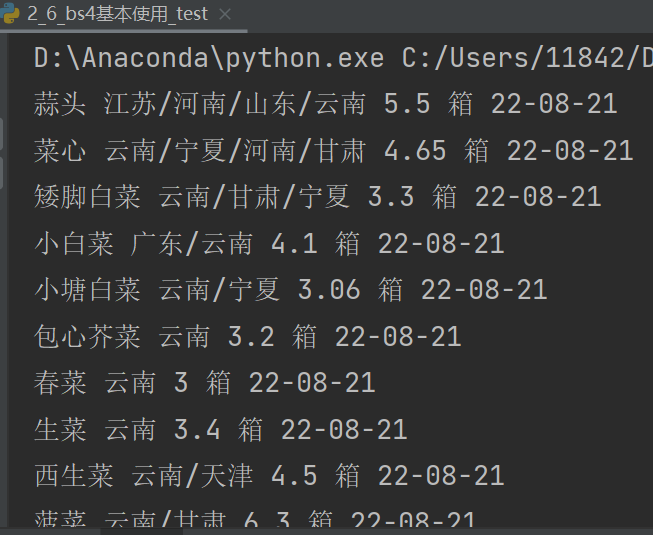
第四步: 将数据保存为csv文件
import csv
f = open("广州江南菜价.csv",mode="w",newline="",encoding="utf-8")
csvwriter = csv.writer(f)
table = page.find("table",attrs={"class":"price-table"})
trs = table.find_all("tr")[1:] # tr是行的意思
for tr in trs: # 每一行
tds = tr.find_all("td") # td表示单元格。拿到每行中的所有td
# print(tds[0])
# 名字、产地、均价(元/公斤)、规格、日期
name = tds[0].text # .text表示拿到被标签标记的内容
place = tds[1].text
avg_price = tds[2].text
guige = tds[3].text
date = tds[4].text
csvwriter.writerow([name,place,avg_price,guige,date])
f.close()
print("over")
resp.close()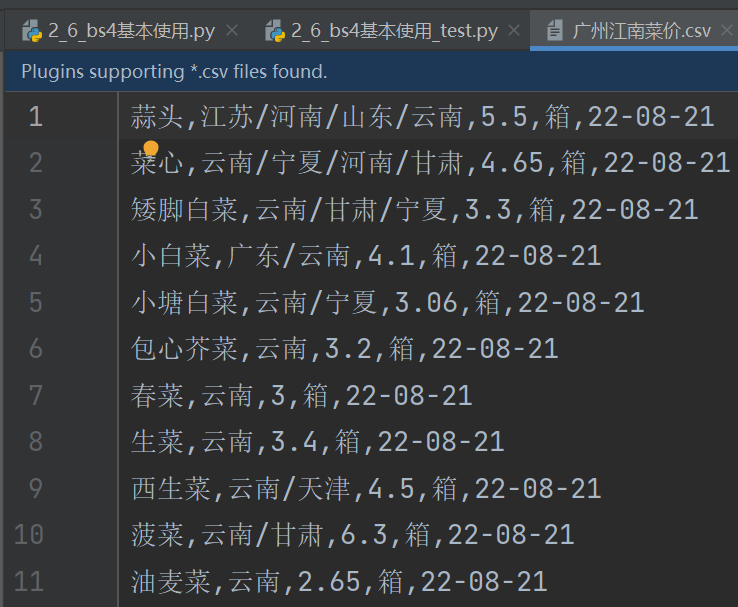
完整代码:
import requests
from bs4 import BeautifulSoup
import csv
# 拿到页面源代码
url = "http://www.jnmarket.net/import/list-1.html"
resp = requests.get(url)
# print(resp.text)
f = open("广州江南菜价.csv",mode="w",newline="",encoding="utf-8")
csvwriter = csv.writer(f)
# 使用bs4解析数据(两步)
# 1. 生成bs对象
page = BeautifulSoup(resp.text, "html.parser") # 指定html解析器
# 2. 从bs对象中查找数据
# find(标签, 属性=值):找第一个
# find_all(标签, 属性=值):找全部
# table = page.find("table",class_="price-table") # class是python中的关键字,加_以示区别
# 另一种写法:
table = page.find("table",attrs={"class":"price-table"}) # 和上一行是一个意思,此时可以避免class
# print(table)
# 不想要列名那一行(表头),只想要底下的数据,即拿到所有数据行
trs = table.find_all("tr")[1:] # tr是行的意思
for tr in trs: # 每一行
tds = tr.find_all("td") # td表示单元格。拿到每行中的所有td
# print(tds[0])
# 名字、产地、均价(元/公斤)、规格、日期
name = tds[0].text # .text表示拿到被标签标记的内容
place = tds[1].text
avg_price = tds[2].text
guige = tds[3].text
date = tds[4].text
# print(name,place,avg_price,guige,date)
csvwriter.writerow([name,place,avg_price,guige,date])
f.close()
print("over")
resp.close()同理,该代码只爬取了第一页的20条数据,还有优化的空间。翻页的时候注意 url 的变化