本课程共五个章节,课程地址:
【Python爬虫教程】花9888买的Python爬虫全套教程2021完整版现分享给大家!(已更新项目)——附赠课程与资料_哔哩哔哩_bilibili
第四章- 本章内容梗概
- 多线程
- 多进程
- 线程池和进程池
- 抓取广州江南果菜批发市场菜价
- 协程
- 多任务异步协程
- aiohttp模块
- 异步爬虫实战:扒光一本电子书
- 综合训练:抓取一部电影
目录
第四章
(六)协程
(七)多任务异步协程
python编写协程的程序
官方推荐写法
在爬虫领域的应用
(八)aiohttp模块
安装
代码框架
例子
(九)异步爬虫实战:扒光一本电子书
思路
第一步:同步操作
第二步:异步操作
(六)协程协程能够更加高效的利用CPU
其实,我们能够高效的利用多线程来完成爬虫已经很厉害了。但是,从某种角度讲,线程的执行效率真的就无敌了吗?我们真的充分利用CPU资源了吗?非也
比如,我们来看下面这个例子。我们单独的用一个线程来完成某一个操作,看看它的效率是否真的能把CPU完全利用起来
import time
def func():
print("我爱黎明")
time.sleep(3) # 让当前的线程处于阻塞状态,CPU是不为我工作的
print("我真的爱黎明")
if __name__ == '__main__':
func()
# 其他能让线程处于阻塞状态的语句(一般情况下,当程序处于IO操作的时候,线程都会处于阻塞状态)
# input() 输入
# requests.get() 发送请求(在网络请求返回数据之前,程序也是处于阻塞状态的)在该程序中,我们的func()实际在执行的时候至少需要3s的时间来完成操作,中间的3s需要让我当前的线程处于阻塞状态,阻塞状态的线程CPU是不会来执行你的,那么此时CPU很可能会切换到其他程序上去执行。此时,对于你来说,在这3s内CPU并没有为你工作。那么我们能不能通过某种手段,让CPU一直为我工作,尽量不要去管其他人
我们知道CPU一般抛开执行周期不谈,如果一个线程遇到了IO操作,CPU就会自动地切换到其他线程进行执行。那么,如果我想办法让我的线程遇到了IO操作就挂起,留下的都是运算操作,那CPU是不是就会长时间的来照顾我
以此为目的,程序员就发明了一个新的执行过程:当线程中遇到了IO操作的时候,将线程中的任务进行切换,切换成非IO操作,等原来的IO执行完了,再恢复到原来的任务中
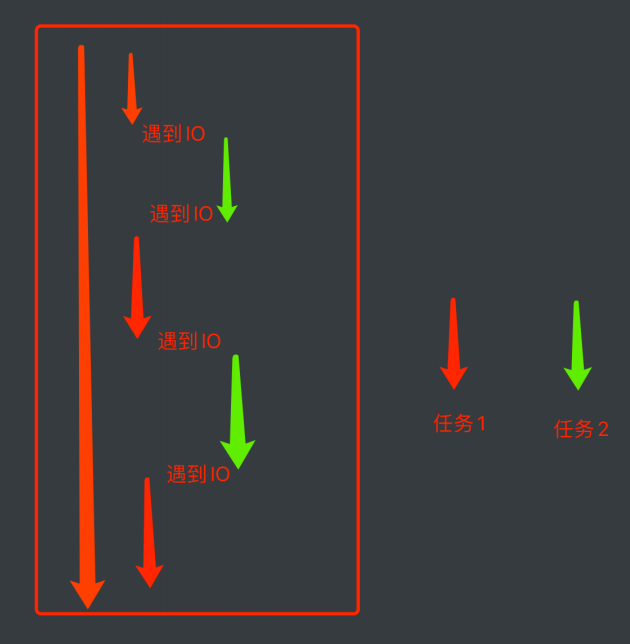
协程:当程序遇见了IO操作(费时不费力的操作)的时候,可以选择性的切换到其他任务上(程序完成的,不是操作系统完成的)
- 在微观上是一个任务一个任务的进行切换,切换条件一般就是IO操作
- 在宏观上,我们能看到的其实是多个任务一起在执行(多任务异步操作)
上方所讲的一切,都是在单线程的条件下
(七)多任务异步协程 python编写协程的程序import asyncio
async def func():
print("你好啊,我叫赛利亚")
if __name__ == '__main__':
# print(func()) 此时拿到的是一个协程对象,和生成器差不多,该函数默认是不会这样执行的
g = func() # 此时的函数是异步协程函数,函数执行得到的是一个协程对象
asyncio.run(g) # 协程程序运行需要asyncio模块的支持
但上面这个代码是单任务的,下面写一个多任务的:
import asyncio
import time
async def func1():
print("你好啊,我叫潘金莲")
time.sleep(3)
print("你好啊,我叫潘金莲")
async def func2():
print("你好啊,我叫王建国")
time.sleep(2)
print("你好啊,我叫王建国")
async def func3():
print("你好啊,我叫李雪琴")
time.sleep(4)
print("你好啊,我叫李雪琴")
if __name__ == '__main__':
f1 = func1() # 此时的函数是异步协程函数,函数执行得到的是一个协程对象
f2 = func2()
f3 = func3()
# 把三个任务统一放到列表里去
tasks = [
f1,f2,f3
]
t1 = time.time() # 执行之前记录一下时间
# 一次性启动多个任务(协程)
asyncio.run(asyncio.wait(tasks)) # 协程程序运行需要asyncio模块的支持
t2 = time.time() # 执行之后记录一下时间
print(t2-t1) 异步操作,但跑出来的是同步效果
异步操作,但跑出来的是同步效果
异步效果的:
await:当该任务被挂起后,CPU会自动切换到其他任务中
import asyncio
import time
async def func1():
print("你好啊,我叫潘金莲")
# time.sleep(3) # 当程序出现了同步操作的时候,异步就中断了 还有如requests.get()也会造成阻塞,碰到的时候也要换成对应的异步操作的代码
await asyncio.sleep(3) # 异步操作的代码
print("你好啊,我叫潘金莲")
async def func2():
print("你好啊,我叫王建国")
# time.sleep(2)
await asyncio.sleep(2)
print("你好啊,我叫王建国")
async def func3():
print("你好啊,我叫李雪琴")
# time.sleep(4)
await asyncio.sleep(4)
print("你好啊,我叫李雪琴")
if __name__ == '__main__':
f1 = func1() # 此时的函数是异步协程函数,函数执行得到的是一个协程对象
f2 = func2()
f3 = func3()
# 把三个任务统一放到列表里去
tasks = [ # 协程任务列表
f1,f2,f3 # 创建协程任务
]
t1 = time.time() # 执行之前记录一下时间
# 一次性启动多个任务(协程)
asyncio.run(asyncio.wait(tasks)) # 协程程序运行需要asyncio模块的支持
t2 = time.time() # 执行之后记录一下时间
print(t2-t1)
import asyncio
import time
async def func1():
print("你好啊,我叫潘金莲")
await asyncio.sleep(3) # 异步操作的代码
print("你好啊,我叫潘金莲")
async def func2():
print("你好啊,我叫王建国")
await asyncio.sleep(2)
print("你好啊,我叫王建国")
async def func3():
print("你好啊,我叫李雪琴")
await asyncio.sleep(4)
print("你好啊,我叫李雪琴")
async def main(): # 协程函数
# 第一种写法
# f1 = func1()
# await f1 # 一般await挂起操作放在协程对象前面
# 第二种写法(推荐)
tasks = [ # 组成列表
func1(),
func2(),
func3()
]
await asyncio.wait(tasks) # 一次性把所有任务都执行
if __name__ == '__main__':
t1 = time.time()
asyncio.run(main()) # run协程对象
t2 = time.time()
print(t2-t1)
python3.8之后的版本运行上述代码时可能会有警告,将代码稍作修改:
# py3.8之后需要我们手动将协程对象包装成task对象
tasks = [
asyncio.create_task(func1()), # py3.8以后加上asyncio.create_task()
asyncio.create_task(func2()),
asyncio.create_task(func3())
]
await asyncio.wait(tasks)import asyncio
# 在爬虫领域的应用
async def download(url):
print("准备开始下载")
await asyncio.sleep(2) # 模拟网络请求 不能写requests.get()
print("下载完成")
async def main():
urls = [
"http://www.baidu.com",
"http://www.bilibili.com",
"http://www.163.com"
]
tasks = []
for url in urls:
d = download(url) # 协程对象
tasks.append(d)
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())
python3.8之后的版本运行上述代码时可能会有警告,将代码稍作修改:
# 准备异步协程对象列表
tasks = []
for url in urls:
d = asycio.create_task(download(url))
tasks.append(d)
tasks = [asyncio.create_task(download(url)) for url in urls] # 这么干也行哦~多线程和异步一个是程序执行模式,一个是IO模式。协程是单线程,事实上只是节省了CPU切栈的时间
(八)aiohttp模块requests.get() 是同步的代码,如何换成异步的操作? 借助 模块aiohttp(第三方库,需安装)
aiohttp是python的一个非常优秀的第三方异步http请求库,我们可以用aiohttp来编写异步爬虫(协程)
安装:pip install aiohttp --trusted-host pypi.tuna.tsinghua.edu.cnimport asyncio
import aiohttp
urls = [
"",
""
]
# 异步下载
async def aiodownload(url):
pass
async def main():
tasks = [] # 添加下载任务
for url in urls:
tasks.append(aiodownload(url))
await asyncio.wait(tasks) # 等待所有任务下载完成
if __name__ == '__main__':
asyncio.run(main())【唯美壁纸】桌面壁纸唯美小清新_唯美手机壁纸_电脑桌面壁纸高清唯美大全 - 优美图库
import asyncio # 异步协程
import aiohttp # 异步协程的http请求
urls = [ # 复制图片地址
"http://kr.shanghai-jiuxin.com/file/2020/1031/191468637cab2f0206f7d1d9b175ac81.jpg",
"http://kr.shanghai-jiuxin.com/file/2020/1031/563337d07af599a9ea64e620729f367e.jpg",
"http://kr.shanghai-jiuxin.com/file/2020/1031/774218be86d832f359637ab120eba52d.jpg"
]
async def aiodownload(url):
# 发送请求 ——> 得到图片内容 ——> 保存到文件
'''
s = aiohttp.ClientSession() 等价于 requests
requests.get() .post()
s.get() .post()
'''
name = url.rsplit("/", 1)[1] # 从右边切, 切一次. 得到[1]位置的内容
# 有了with会自动close
async with aiohttp.ClientSession() as session: # session对象相当于requests对象
async with session.get(url) as resp: # 发送请求,相当于resp = requests.get()
# 请求回来了. 写入文件
# 写入文件可以自己去学习一个模块aiofiles
with open(name, mode="wb") as f: # 创建文件
# resp.content.read() 等价于 resp.content 读取图片
# resp.text() 等价于 resp.text 读取文本,如页面源代码
# resp.json() 等价于 resp.json() 读取json
f.write(await resp.content.read()) # 读取内容是异步的. 需要await挂起
print(name, "搞定")
async def main():
tasks = []
for url in urls:
tasks.append(aiodownload(url))
await asyncio.wait(tasks)
if __name__ == '__main__':
asyncio.run(main())运行后能爬下图片,但是代码会报错:
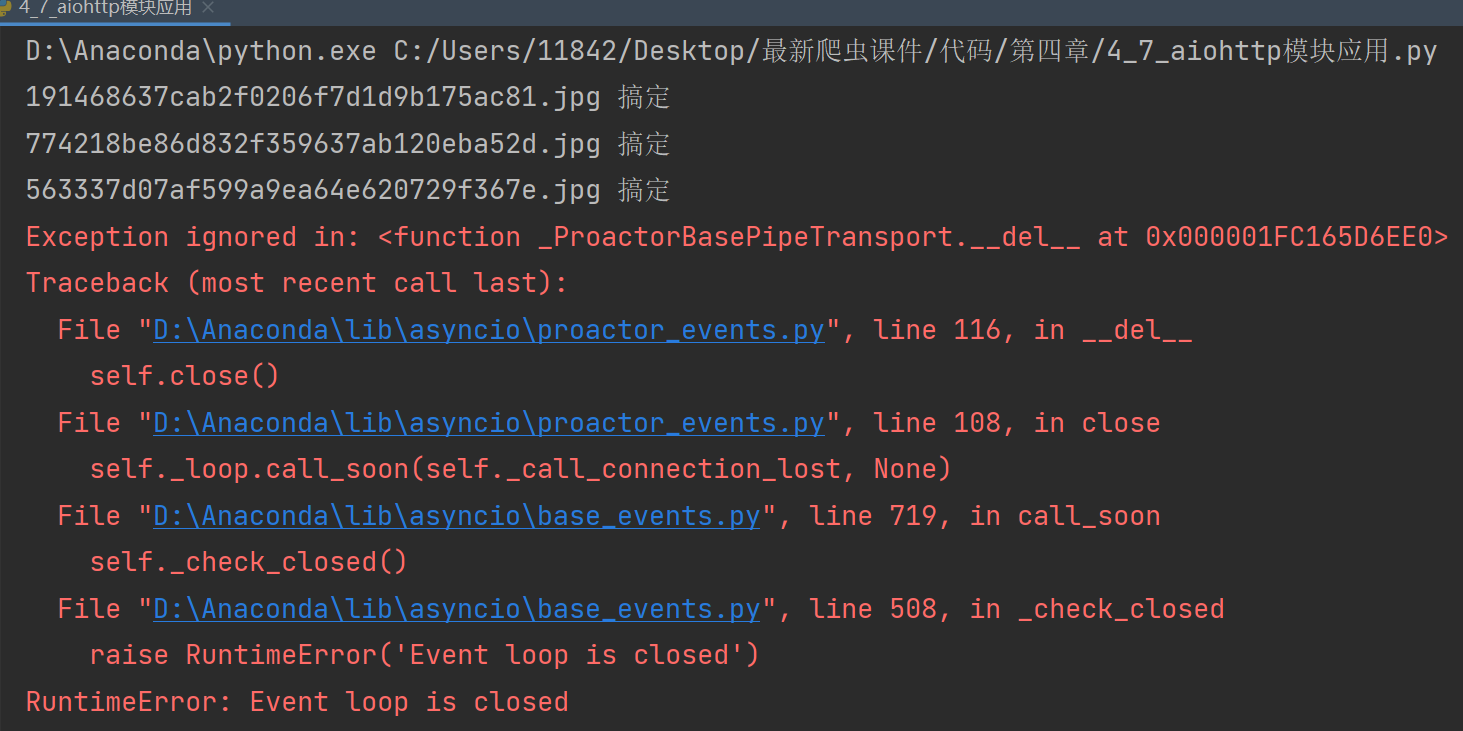
将 asyncio.run() 改为 asyncio.get_event_loop().run_until_complete(main()) 即可。具体可参考下面这个帖子:
【Python自学笔记】asyncio.run()报错RuntimeError:Event loop is closed的原因以及解决办法_xiaoqiangclub的博客-CSDN博客_asyncio.run
if __name__ == '__main__':
asyncio.get_event_loop().run_until_complete(main())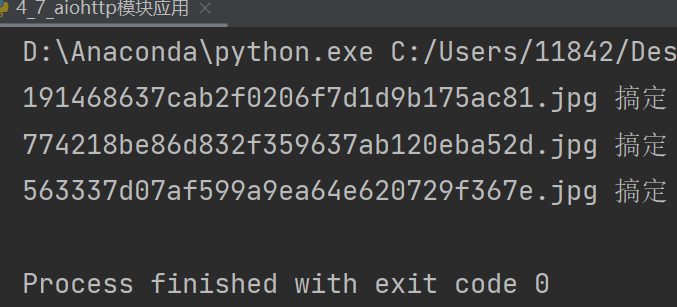
从最终运行的结果中能非常直观地看到用异步IO完成爬虫的效率明显高了很多
(九)异步爬虫实战:扒光一本电子书百度小说
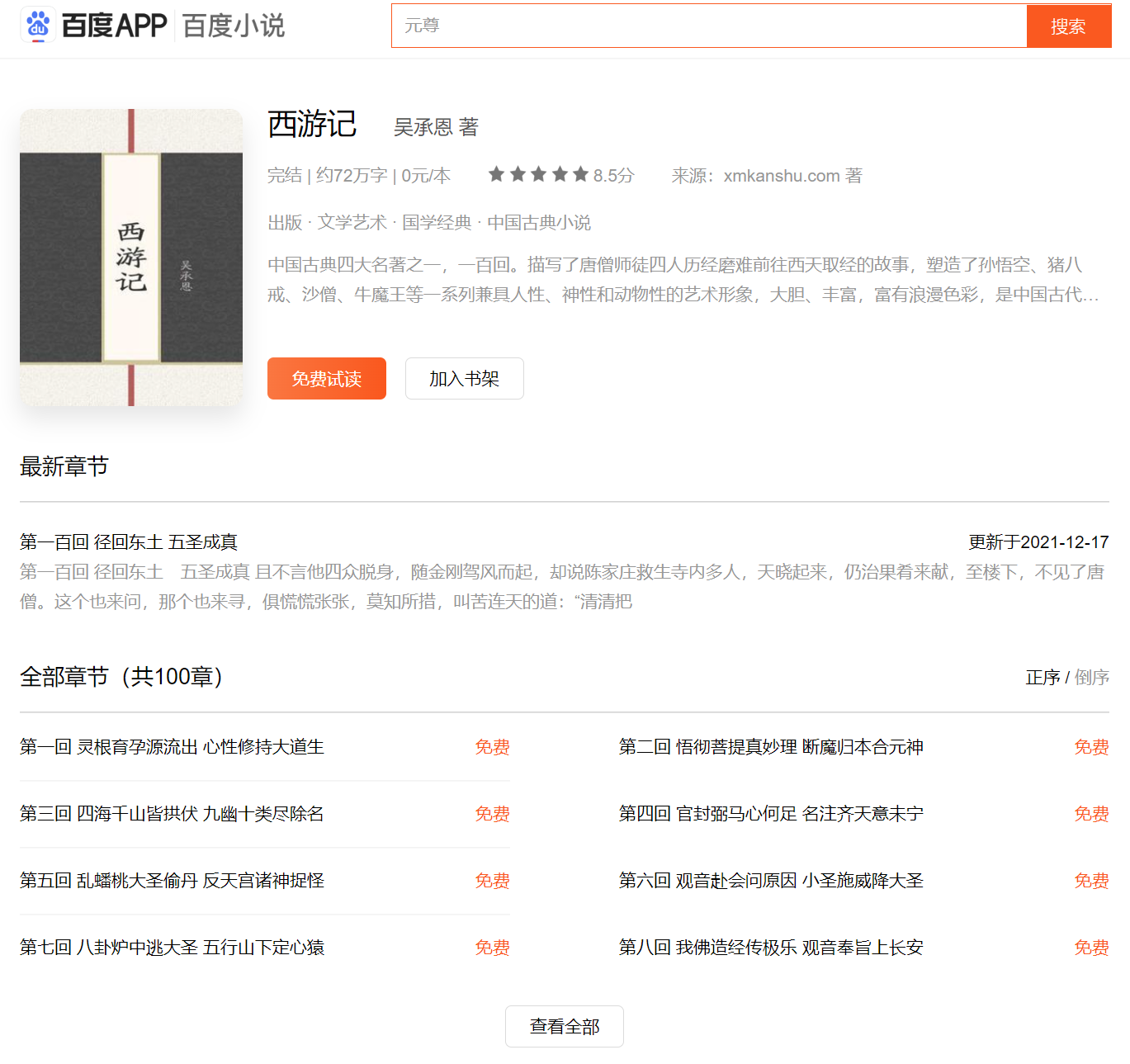
右键 ——> 查看网页源代码,如图:
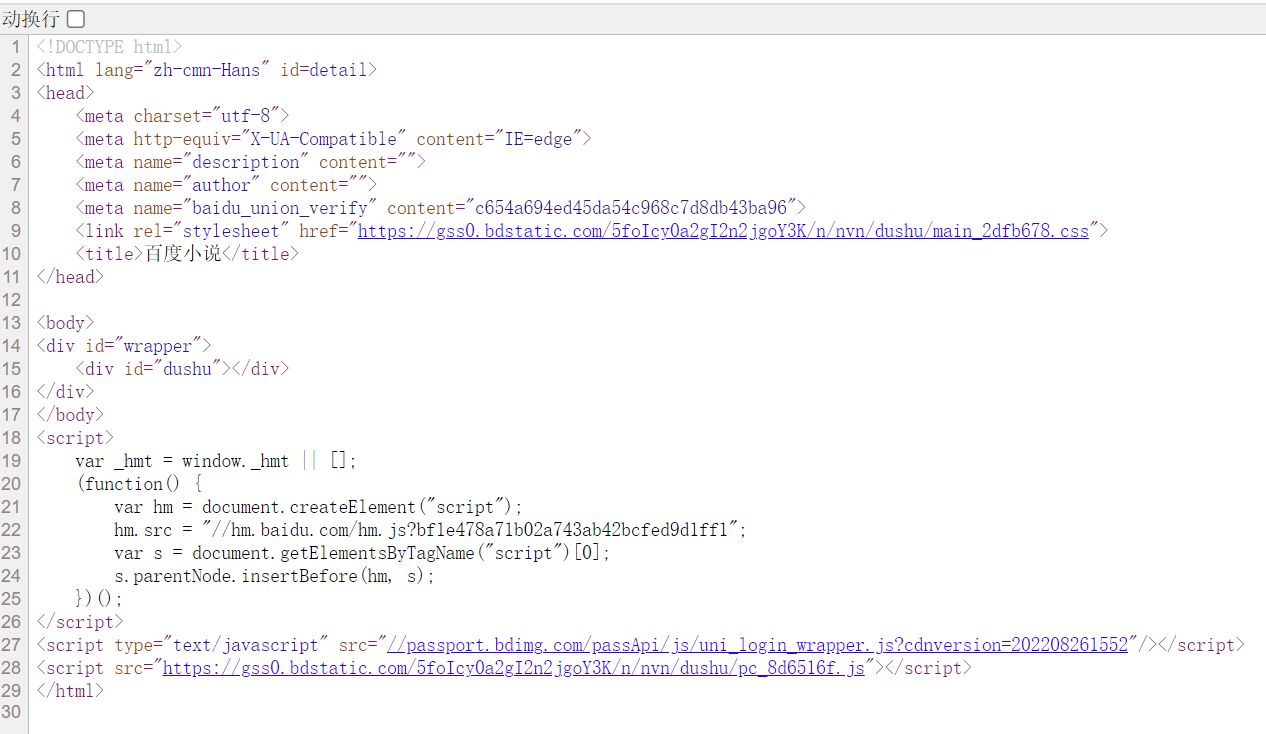
说明页面的数据是通过 ajax 异步操作返回的数据(第二次加载的),故 f12 ,点击页面上 “全部章节(共100章)” 后的 “查看全部”
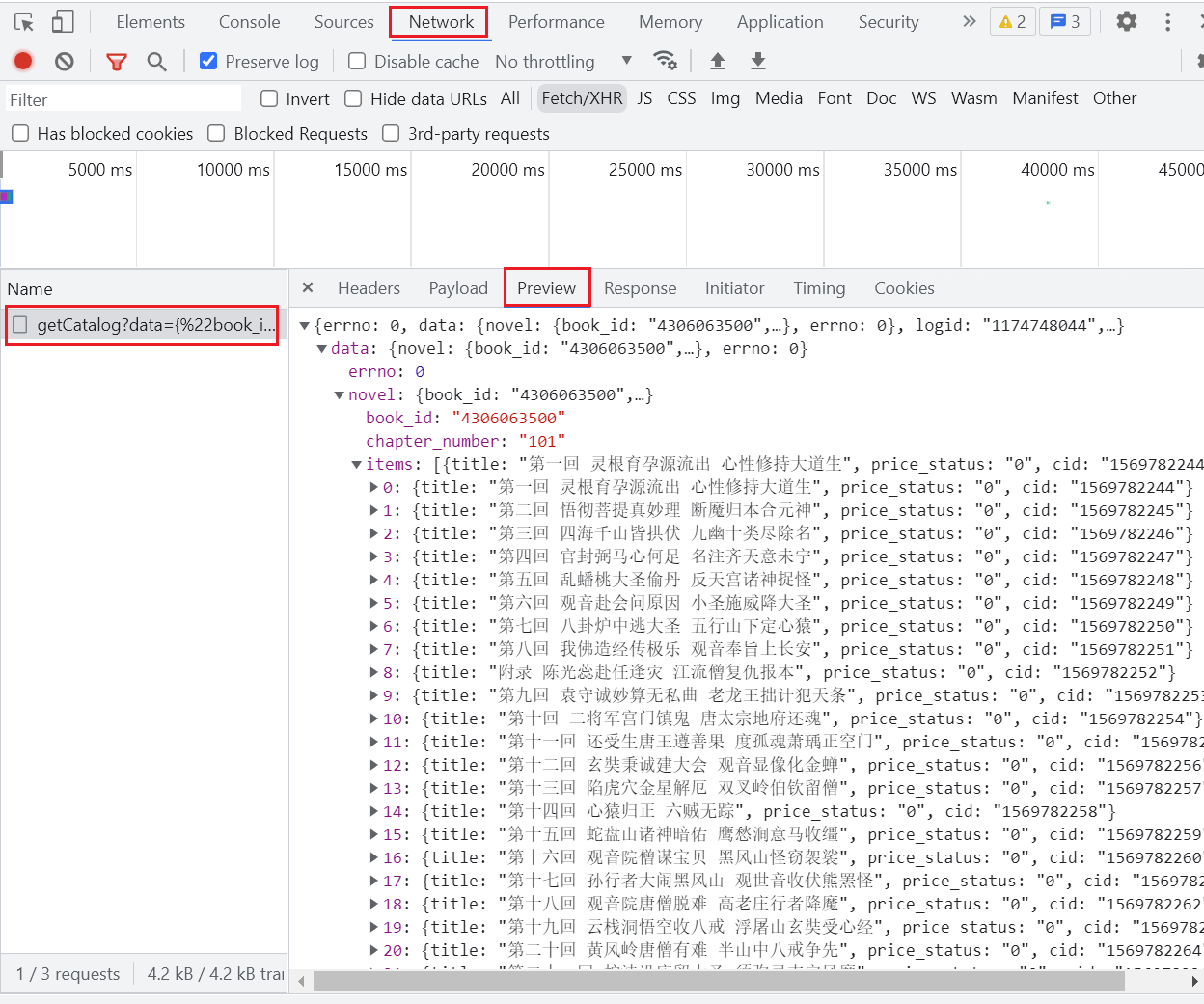
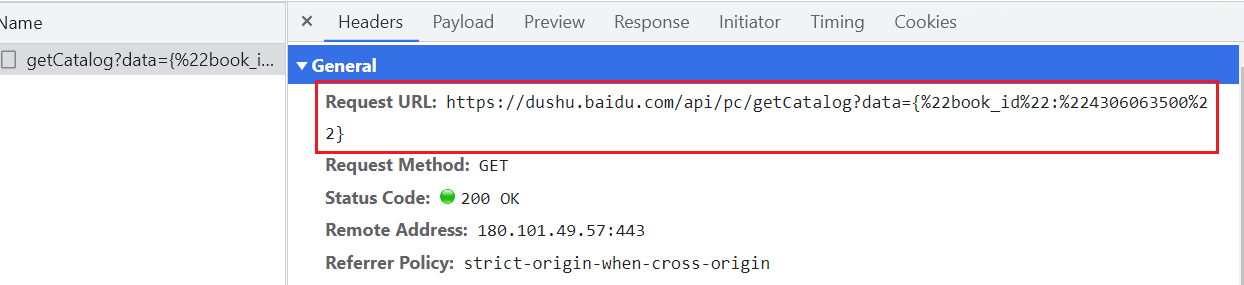
# 所有章节的内容(名称、cid)
# 同步的方式即可
https://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"4306063500"}随便点进某一回的链接,如图:
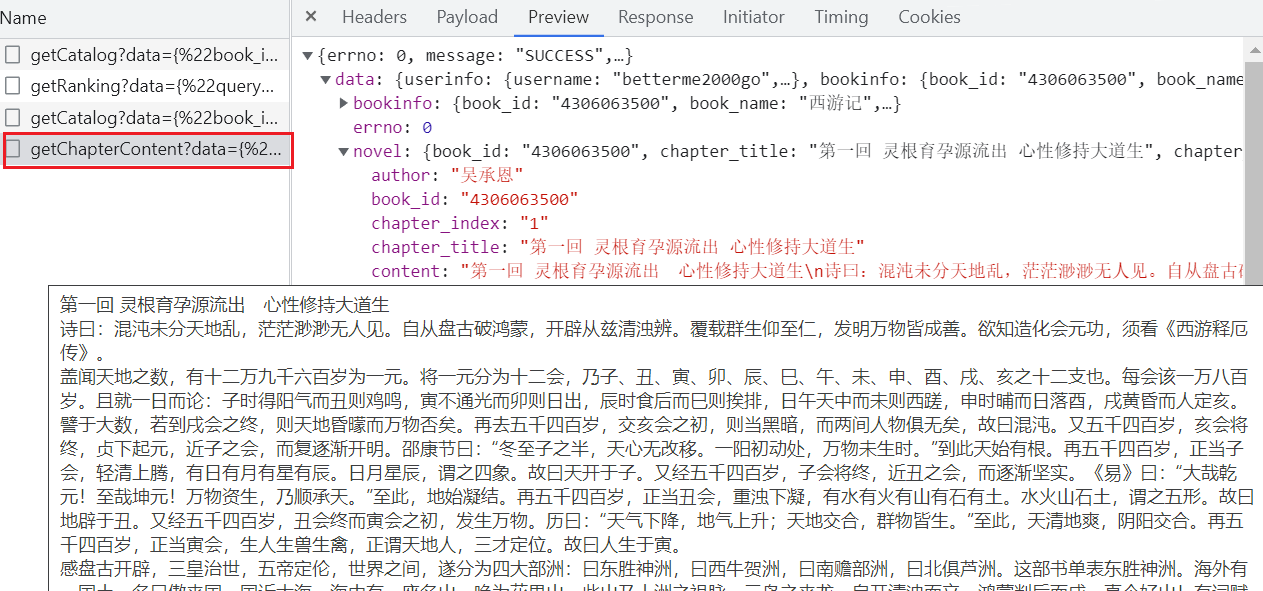
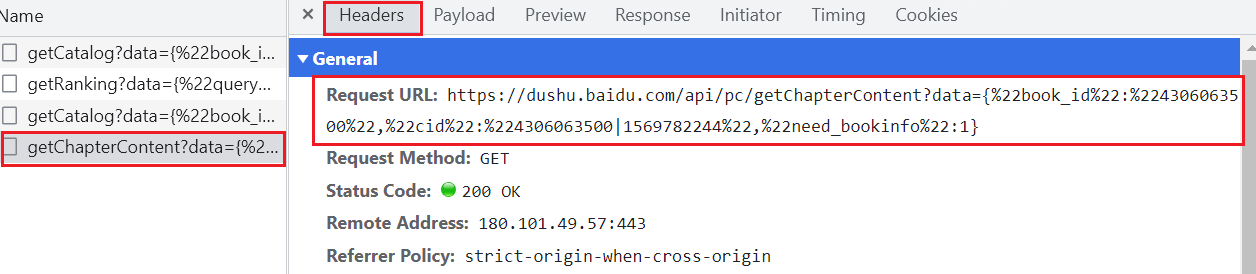
# 章节内部的内容
# 需要异步(100个章节即100个任务)
https://dushu.baidu.com/api/pc/getChapterContent?data={"book_id":"4306063500","cid":"4306063500|1569782244","need_bookinfo":1}- 同步操作:访问getCatolog 拿到所有章节的cid和名称
- 异步操作:访问getChapterContent 下载所有的文章内容
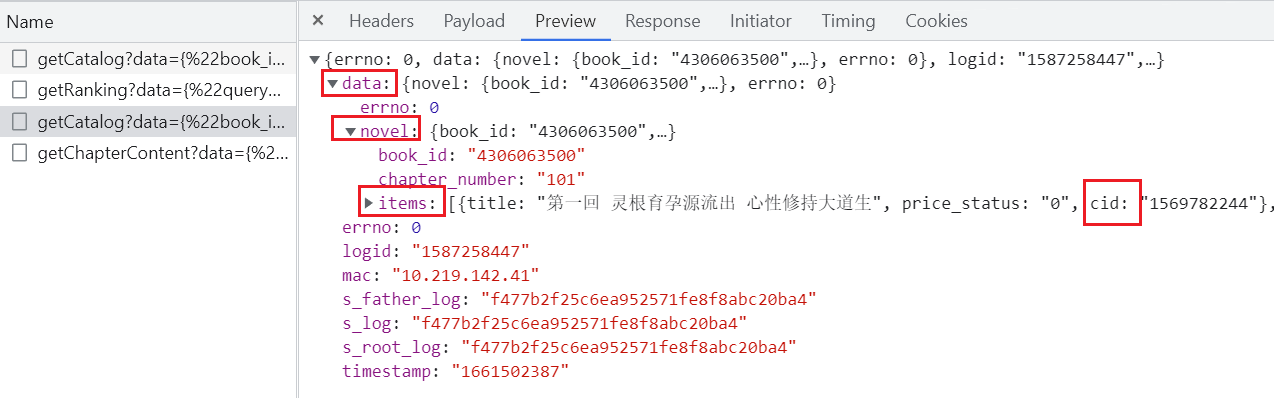
怎么拿cid?
import requests
def getCatalog(url):
resp = requests.get(url)
dic = resp.json()
for item in dic['data']['novel']['items']: # item就是对应每一个章节的名称和cid
title = item['title']
cid = item['cid']
print(title,cid)
if __name__ == '__main__':
b_id = "4306063500"
url = 'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"' + b_id + '"}'
getCatalog(url)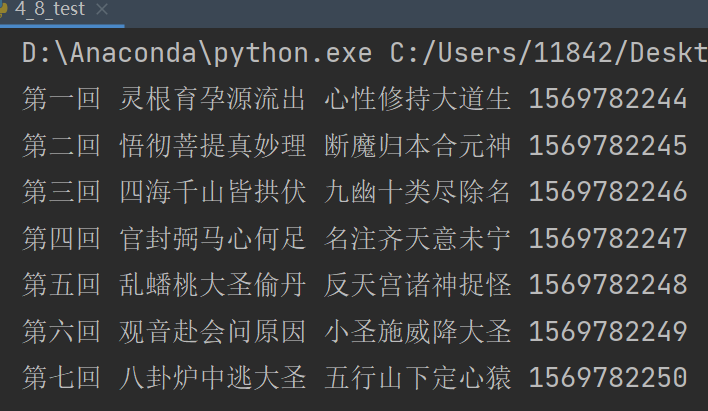
每一个cid就是一个异步任务
如何获取章节内容?

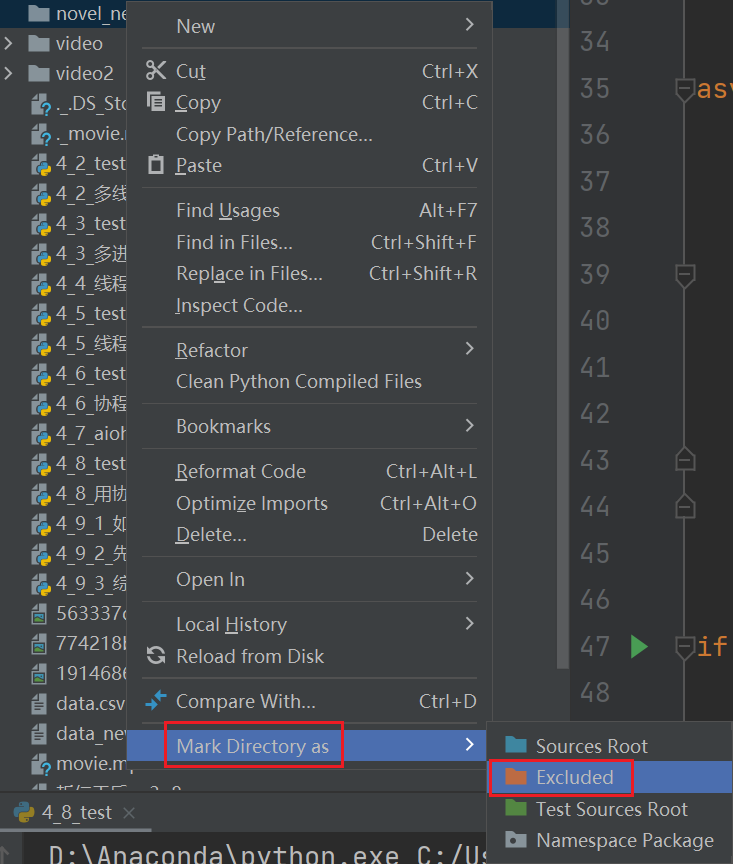
代码运行前,先创建一个文件夹,并把文件夹标记成 Excluded
# http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"4306063500"} => 所有章节的内容(名称, cid)
# http://dushu.baidu.com/api/pc/getChapterContent?data={"book_id":"4306063500","cid":"4306063500|11348571","need_bookinfo":1} => 章节内部的内容
import requests
import asyncio
import aiohttp
import aiofiles # 异步的文件读写
import json
"""
1. 同步操作: 访问getCatalog 拿到所有章节的cid和名称
2. 异步操作: 访问getChapterContent 下载所有的文章内容
"""
async def aiodownload(cid, b_id, title):
data = {
"book_id":b_id,
"cid":f"{b_id}|{cid}",
"need_bookinfo":1
}
data = json.dumps(data) # 将对象变为json字符串
url = f"http://dushu.baidu.com/api/pc/getChapterContent?data={data}"
async with aiohttp.ClientSession() as session: # 准备好session
async with session.get(url) as resp: # session发送请求
dic = await resp.json() # 从发送的请求里读取json
async with aiofiles.open(title, mode="w", encoding="utf-8") as f:
await f.write(dic['data']['novel']['content']) # 把小说内容写出
async def getCatalog(url):
# 同步(此时还没有其他任务会和该任务一起并行执行,所以完全没必要用异步)
resp = requests.get(url)
dic = resp.json()
# 得到要的内容之后,再异步
tasks = []
for item in dic['data']['novel']['items']: # item就是对应每一个章节的名称和cid
title = item['title']
cid = item['cid']
# 准备异步任务
tasks.append(aiodownload(cid, b_id, title))
await asyncio.wait(tasks)
if __name__ == '__main__':
b_id = "4306063500" # 百度小说的书籍id
url = 'http://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"' + b_id + '"}' # 首页url
asyncio.get_event_loop().run_until_complete(getCatalog(url))运行后,将产生的文件全部移入之前建立好的文件夹里
怎么一次性选中多个文件?
左键选中一个文件,按住Ctrl+Shift,选中想要范围内的文件