
目录
1. 任务、算子链和资源组
- 1. 任务、算子链和资源组
- 2. ProcessFunction
- 3. 迭代运算
- 3.1 iterate
- 3.2 iterateWithTermination
- 3.3 iterateDelta
- 3.4 iterate(DataStream)

- Task Slot相当于线程
- Task Slot的数量等于最大parallelism
- 可以通过
-p参数进行指定Task Slot的数量
自定义算子链接关系
package devBase
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, createTypeInformation}
object TranformationOperatorTest {
def main(args: Array[String]): Unit = {
val senv = StreamExecutionEnvironment.getExecutionEnvironment
// senv.disableOperatorChaining() // 禁用链接Chain
val input = senv.fromElements(("key1", "value1"), ("key2", "value2"))
// source和filter位于一个slot, 第一个map、第二个map、print位于另一个slot
val output1 = input.filter(x => true)
.map(x => x).startNewChain().map(x => x)
output1.print("output1")
/*
output1:5> (key1,value1)
output1:6> (key2,value2)
*/
// source和filter位于一个slot, map、print位于另一个slot
val output2 = input.filter(x => true)
.map(x => x).disableChaining()
output2.print("output2")
/*
output2:5> (key2,value2)
output2:4> (key1,value1)
*/
// source、filter属于default group, parallelism为1,需要一个Task Slot
// map、print属于no_default group, parallelism为1,需要一个Task Slot
// 所以该application总共需要两个Task Slot
// (todo)IDEA中执行一直卡住,最后报Caused by: org.apache.flink.runtime.jobmanager.scheduler.NoResourceAvailableException: Could not acquire the minimum required resources
val output3 = input.filter(x => true)
.map(x => x).slotSharingGroup("no_default")
output3.print("output3")
senv.execute()
}
}
- 基础应用
package devBase
import org.apache.flink.streaming.api.functions.ProcessFunction
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, createTypeInformation}
import org.apache.flink.util.Collector
object TranformationOperatorTest {
def main(args: Array[String]): Unit = {
val senv = StreamExecutionEnvironment.getExecutionEnvironment
val input = senv.fromElements(
("key1", "value1"),
("key2", "value2"),
("key3", "value3")
)
val output = input.process(new ProcessFunction[(String,String), (String,String)] {
override def processElement(i: (String, String), context: ProcessFunction[(String, String), (String, String)]#Context, collector: Collector[(String, String)]): Unit = {
collector.collect(i)
}
})
output.print()
senv.execute()
}
}
执行结果
7> (key2,value2)
8> (key3,value3)
6> (key1,value1)
- ProcessFunction类
package org.apache.flink.streaming.api.functions;
import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.api.common.functions.AbstractRichFunction;
import org.apache.flink.streaming.api.TimeDomain;
import org.apache.flink.streaming.api.TimerService;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
@PublicEvolving
public abstract class ProcessFunction extends AbstractRichFunction {
private static final long serialVersionUID = 1L;
public abstract void processElement(I value, Context ctx, Collector out) throws Exception;
public void onTimer(long timestamp, OnTimerContext ctx, Collector out) throws Exception {}
public abstract class Context {
public abstract Long timestamp();
public abstract TimerService timerService();
public abstract void output(OutputTag outputTag, X value);
}
public abstract class OnTimerContext extends Context {
public abstract TimeDomain timeDomain();
}
}
- ProcessFunction类的函数和内部类都是新增的
- 可以通过getRuntimeContext函数获取RuntimeContext, RuntimeContext能获取到各种State状态
- 通过processElement函数的Context访问TimerService,为ProcessingTime或EventTime时间模式注册timestamp, 当Watermarks到达该timestamp,则触发onTimer函数的运行;为同一key注册多个相同的timestamp,则onTimer函数也只触发一次;onTimer函数和processElement函数不是异步执行的
- TimerService类
package org.apache.flink.streaming.api;
import org.apache.flink.annotation.PublicEvolving;
@PublicEvolving
public interface TimerService {
String UNSUPPORTED_REGISTER_TIMER_MSG = "Setting timers is only supported on a keyed streams.";
String UNSUPPORTED_DELETE_TIMER_MSG = "Deleting timers is only supported on a keyed streams.";
long currentProcessingTime();
long currentWatermark();
void registerProcessingTimeTimer(long time);
void registerEventTimeTimer(long time);
void deleteProcessingTimeTimer(long time);
void deleteEventTimeTimer(long time);
}
- checkpoint也会对注册timestamp的Timer进行保存
- 可以将timestamp进行转换为秒级别,再进行注册,减少Timer计时器的数量
- TimeDomain类
package org.apache.flink.streaming.api;
public enum TimeDomain {
EVENT_TIME,
PROCESSING_TIME
}
- AbstractRichFunction类
package org.apache.flink.api.common.functions;
import org.apache.flink.annotation.Public;
import org.apache.flink.configuration.Configuration;
import java.io.Serializable;
@Public
public abstract class AbstractRichFunction implements RichFunction, Serializable {
private static final long serialVersionUID = 1L;
private transient RuntimeContext runtimeContext;
@Override
public void setRuntimeContext(RuntimeContext t) {
this.runtimeContext = t;
}
@Override
public RuntimeContext getRuntimeContext() {
if (this.runtimeContext != null) {
return this.runtimeContext;
} else {
throw new IllegalStateException("The runtime context has not been initialized.");
}
}
@Override
public IterationRuntimeContext getIterationRuntimeContext() {
if (this.runtimeContext == null) {
throw new IllegalStateException("The runtime context has not been initialized.");
} else if (this.runtimeContext instanceof IterationRuntimeContext) {
return (IterationRuntimeContext) this.runtimeContext;
} else {
throw new IllegalStateException("This stub is not part of an iteration step function.");
}
}
@Override
public void open(Configuration parameters) throws Exception {}
@Override
public void close() throws Exception {}
}
- AbstractRichFunction类对RichFunction类的所以函数对进行了实现
- RuntimeContext
package org.apache.flink.api.common.functions;
import org.apache.flink.annotation.Public;
import org.apache.flink.annotation.PublicEvolving;
import org.apache.flink.api.common.ExecutionConfig;
import org.apache.flink.api.common.JobID;
import org.apache.flink.api.common.accumulators.Accumulator;
import org.apache.flink.api.common.accumulators.DoubleCounter;
import org.apache.flink.api.common.accumulators.Histogram;
import org.apache.flink.api.common.accumulators.IntCounter;
import org.apache.flink.api.common.accumulators.LongCounter;
import org.apache.flink.api.common.cache.DistributedCache;
import org.apache.flink.api.common.externalresource.ExternalResourceInfo;
import org.apache.flink.api.common.state.AggregatingState;
import org.apache.flink.api.common.state.AggregatingStateDescriptor;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.metrics.MetricGroup;
import java.io.Serializable;
import java.util.List;
import java.util.Set;
@Public
public interface RuntimeContext {
JobID getJobId();
String getTaskName();
@PublicEvolving
MetricGroup getMetricGroup();
int getNumberOfParallelSubtasks();
@PublicEvolving
int getMaxNumberOfParallelSubtasks();
int getIndexOfThisSubtask();
int getAttemptNumber();
String getTaskNameWithSubtasks();
ExecutionConfig getExecutionConfig();
ClassLoader getUserCodeClassLoader();
@PublicEvolving
void registerUserCodeClassLoaderReleaseHookIfAbsent(
String releaseHookName, Runnable releaseHook);
void addAccumulator(String name, Accumulator accumulator);
Accumulator getAccumulator(String name);
@PublicEvolving
IntCounter getIntCounter(String name);
@PublicEvolving
LongCounter getLongCounter(String name);
@PublicEvolving
DoubleCounter getDoubleCounter(String name);
@PublicEvolving
Histogram getHistogram(String name);
@PublicEvolving
Set getExternalResourceInfos(String resourceName);
@PublicEvolving
boolean hasBroadcastVariable(String name);
List getBroadcastVariable(String name);
C getBroadcastVariableWithInitializer(
String name, BroadcastVariableInitializer initializer);
DistributedCache getDistributedCache();
@PublicEvolving
ValueState getState(ValueStateDescriptor stateProperties);
@PublicEvolving
ListState getListState(ListStateDescriptor stateProperties);
@PublicEvolving
ReducingState getReducingState(ReducingStateDescriptor stateProperties);
@PublicEvolving
AggregatingState getAggregatingState(
AggregatingStateDescriptor stateProperties);
@PublicEvolving
MapState getMapState(MapStateDescriptor stateProperties);
}
- 全量迭代,达到最大迭代次数,则停止迭代
package devBase
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, createTypeInformation}
object TranformationOperatorTest {
def main(args: Array[String]): Unit = {
val test_sum = 1000000
val hit_sum = 0
val env = ExecutionEnvironment.getExecutionEnvironment
val input = env.fromElements(hit_sum)
val hit_sum_ds_final:DataSet[Int] = input.iterate(test_sum)(
// input传递给map函数返回的dataset, 再传递给map函数进行计算,共迭代test_sum次
hit_sum_ds => hit_sum_ds.map(hit_sum => {
val x:Double = math.random
val y:Double =math.random
hit_sum + (if((x * x + y * y) < 1) 1 else 0)
})
)
val pi_output = hit_sum_ds_final.map(hit_sum => hit_sum.toDouble / test_sum * 4)
pi_output.print()
}
}
执行结果
3.14442
- 全量迭代,term_ds没有数据, 或达到最大迭代次数,则停止迭代
package devBase
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, createTypeInformation}
object TranformationOperatorTest {
def main(args: Array[String]): Unit = {
val test_sum = 1000000
val hit_sum = 0
val env = ExecutionEnvironment.getExecutionEnvironment
val input = env.fromElements(hit_sum)
val hit_sum_ds_final:DataSet[Int] = input.iterateWithTermination(test_sum)(
// input传递给map函数返回的dataset, 再传递给map函数进行计算
hit_sum_ds => {
val next_ds = hit_sum_ds.map(hit_sum => {
val x:Double = math.random
val y:Double =math.random
hit_sum + (if((x * x + y * y) < 1) 1 else 0)
})
// term_ds没有数据,或达到最大迭代次数test_sum,迭代终止
val term_ds = next_ds.filter(hit_sum => hit_sum < 700000)
(next_ds, term_ds)
}
)
val pi_output = hit_sum_ds_final.map(hit_sum => hit_sum.toDouble / test_sum * 4)
pi_output.print()
}
}
执行结果
2.8
原理图: 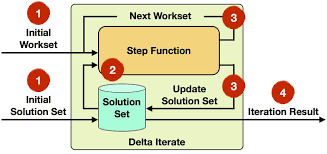
- 增量迭代,nextWorkSet没有数据, 或达到最大迭代次数,则停止迭代,输出initialSolutionSet
- iterateDelta函数第3个参数指定一个key, 用于solutionUpdate更新initialSolutionSet
- iterateDelta函数第4个参数默认为false, 表示将initialSolutionSet置于Flink管理的内存中;为true, 表示将initialSolutionSet置于java的object heap内存中,此时程序执行的结果为:(LiMing,20),(ZhaoSi,32),(ZhangSan,22)
- stepFunction函数的第一次输入为(initialSolutionSet, initialWorkSet), 输出为(solutionUpdate, nextWorkSet); solutionUpdate先更新(类似insert overwrite)initialSolutionSet, 再将initialSolutionSet传递给下一次迭代,nextWorkSet直接传递给下一次迭代(迭代后的nextWorkSet数据量可能会不断的减少)
- initialSolutionSet有多个相同的key, 只保留最后一条数据
package devBase
import org.apache.flink.api.scala.{DataSet, ExecutionEnvironment, createTypeInformation}
import org.apache.flink.util.Collector
object TranformationOperatorTest3 {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val initialSolutionSet:DataSet[(String, Int)] = env.fromElements(
("LiMing", 10),
("LiMing", 20),
("ZhangSan", 20),
("ZhaoSi", 30)
)
val initialWorkSet:DataSet[(String, Int)] = env.fromElements(
("ZhangSan", 0),
("ZhaoSi", 1),
("ZhaoSi", 2),
("WangWu", 0)
)
val output = initialSolutionSet.iterateDelta(initialWorkSet, 100, Array(0), false)(
(solutionSet, workSet) => {
val candidateUpdate:DataSet[(String,Int)] = workSet.map(
tuple => (tuple._1, tuple._2 + 2)
)
// 在iterateDelta函数中,join solutionSet时,只能使用inner join, 但又有leftOuterJoin的功能
val solutionUpdate:DataSet[(String,Int)] =
candidateUpdate.join(solutionSet)
.where(0).equalTo(0)
.apply((left:(String,Int), right:(String,Int), collector:Collector[(String,Int)]) =>{
if (right != null && left._2 > right._2) {
collector.collect(left)
}
})
val nextWorkSet:DataSet[(String,Int)] =
candidateUpdate.leftOuterJoin(solutionUpdate)
.where(0).equalTo(0)
.apply((left:(String,Int), right:(String,Int), collector:Collector[(String,Int)]) =>{
if(right == null) {
collector.collect(left)
}
})
(solutionUpdate, nextWorkSet)
}
)
output.print()
}
}
执行结果:
(LiMing,20)
(ZhaoSi,31)
(ZhangSan,22)
package devBase
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, createTypeInformation}
object TranformationOperatorTest {
def main(args: Array[String]): Unit = {
val senv = StreamExecutionEnvironment.getExecutionEnvironment
val input:DataStream[Long] = senv.fromSequence(0L, 5L) // 6个数
val output:DataStream[Long]=input.iterate(iter => {
val minusOne:DataStream[Long] = iter.map(_ - 1)
val gt0 = minusOne.filter(_ > 0)
val lt0 = minusOne.filter(_ 0
output:7> -1
output:6> 0
output:8> 0
output:4> 0
output:5> 0

