
Python爬虫实战
本节目标:完整的进行一个小说内容爬取的任务.
本节内容:网站数据的爬取,处理,存储 本节技术点:requests,xpath
本节阅读需要(20)min。 本节实操需要(30)min。
需要请提前阅读: Python爬虫实例(1)–requests的应用 也就是专栏里面实例(1)-(4)的内容.
文章目录
前言
- Python爬虫实战
- 前言
- 一、目标分析
- 二、内容的爬取
- 三、内容的处理
- 总结
前面已经完成了几个爬虫的小目标. 但实际上我们爬取小说网站,一般都是为了小说内容. 之前爬取的可以认为是细节信息.但也很重要比如说具体页面的url. 有了它才能重定位到具体的每一章节的具体网页.
一、目标分析我们已经从目录页完成了每个章节的url的提取. 我们先看看章节网页的具体结构.
F12,选中文字部分,观察一下内容的排布方式.
发现都是属于如下的div中. 但是很奇怪内容并没有标签,都是笼统的存在于块之下的。
然后还要很多换行。
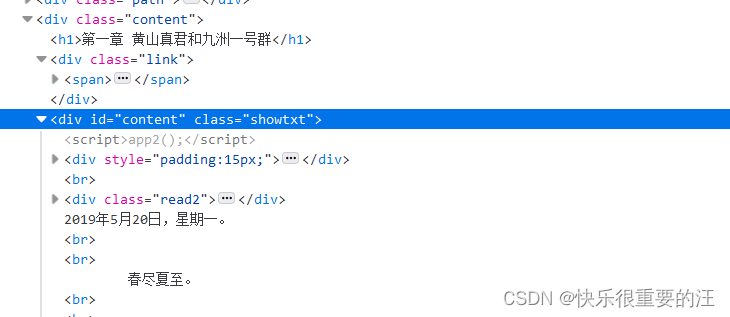
看来还是比较简单…
二、内容的爬取新的网页首先要判断的是编码的类型,尤其是中文比较多的网页。  他说是gbk,但是呢。。。不是啊,起码我们的目标内容不是。
他说是gbk,但是呢。。。不是啊,起码我们的目标内容不是。
gb2312 # 实际编码
gbk # apparent_encoding
Traceback (most recent call last):
File "c:\Users\asus\Desktop\python\everyday\08\xiuzhen_spider.py", line 132, in
page_html = page_rep.text.encode('gbk').decode('gbk')
UnicodeEncodeError: 'gbk' codec can't encode character '\ufffd' in position 5503: illegal multibyte sequence
我们可以先运行一个实例,看看一个网页能不能成功
page_rep = requests.get('https://www.zhhbq.com/1_1852/835564.html') # 可以挑一个
print(page_rep.encoding)
print(page_rep.apparent_encoding)
page_rep.encoding = page_rep.apparent_encoding # 编码转化一下使用gbk编码
xpath操作以来很方便。
page_html.xpath('//div[@id="content"]/text()')
不过记住返回的是一个列表。
三、内容的处理我们希望能保存这些文本以后本地阅读,不是吗?
base_dir = "xiaoshuo" # 保存的文件夹
import os
os.system('mkdir xiaoshuo') # 创建目录
for i in range(len(href_list[:10])): # 跑一个小规模的实例,前十章
save_handle = open(base_dir+"/"+filter_list[i]+".txt","w",encoding='utf-8') # 为了允许更多非中文格式的字符输出用utf-8
txt_list = []
page_rep = requests.get(href_list[i])
print(page_rep.encoding)
print(page_rep.apparent_encoding)
page_rep.encoding = page_rep.apparent_encoding # 编码转化一下
page_html = page_rep.text# .encode('gbk').decode('gbk')
page_html = etree.HTML(page_html)
for line in page_html.xpath('//div[@id="content"]/text()'): # 实际只有一个text不要循环,不过无所谓,反正返回的是列表
txt_list.append(line)
txt_str = "\n".join(txt_list)
save_handle.write(txt_str)
因为有三千多章,所以只运行一个小规模的Demo。 filter_list是前面文章得到的章节名称。
章节目录的爬取
成功!!! 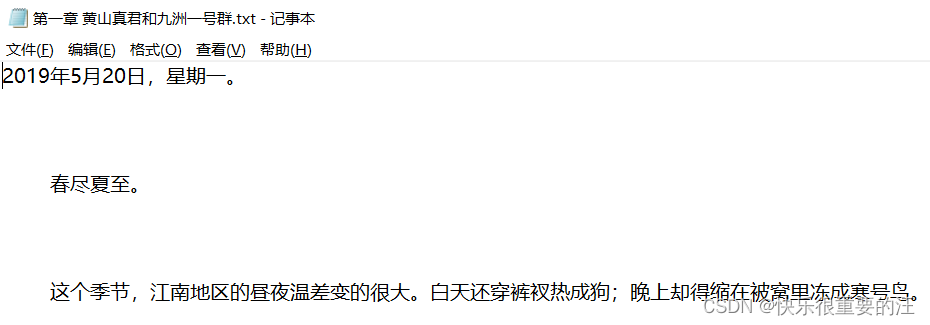
整体的过程还是比较简单的。
但是我们代码都是流的形式。
我们可以封装成函数。然后不同的小说也能去复用!!!
这就交给各位了。
另外呢,爬取下来的文件格式不够好看,比较宽松。最后也有广告信息,可以通过文件处理去除。
延伸阅读:

