- 一、XML和HTML的对比
- 二、XPATH
- 1.xpath的介绍
- 2.etree中的其他内容
- 三、使用xpath过程中遇到的常见问题总结
- 1.对于xpath中含有命名空间的xml文件解析
- 2.使用xpath获取标签内容包含指定字的标签
- 3.删除标签中的多余子标签
W3School官方文档:http://www.w3school.com.cn/xml/index.asp
1.什么是xml?
- xml称为可拓展性标记语言
- xml具有自描述特性,是一种半结构化数据
- XML 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
- XML 的标签需要我们自行定义。
- XML 是 W3C 的推荐标准
2.XML 和 HTML 的区别
他们两者都是用于操作数据或者结构数据,在结构上大致相同的,但他们在本质上却存在着明显的区别。
- 在html中不区分大小写,在xml中严格区分
- 在html中,有时不严格,如果上下文清楚地显示出段落或者列表键在何处结尾,那么你可以省略右半部分闭合标签。在xml中,是严格的树状结构,绝对不能省略任何标记。
- 在xml中,拥有单个标记二没有匹配的结束标记的元素必须用一个/字符作为结尾。
- 在xml中,属性值必须分装在引号中。在html中,引号可用可不用。
- 在html中属性名可以不带属性值,xml必须带
- xml文档中,空白部分不会被解析器自动删除,但是html是过滤掉空格的
- html使用固有的标记,xml没有固有标记
- xml主要用来传输数据, html主要用来显示数据,以及更好的显示数据
W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
1.xpath的介绍1.什么是XPath?
Xath (XML Path Language) 是一种语法,用来提取xml或者html内容的语法。
2.python安装的模块
pip install lxml
3.html转变为文档树
from lxml import etree
doc='''
- 1
- 2
- 3
- 4
- 5 # 注意,此处缺少一个
闭合标签
'''
html = etree.HTML(doc)#相当于将doc套入了 doc之中
html2=etree.XML(doc)# 原doc内容
result = etree.tostring(html)
print(str(result,'utf-8'))
4. 外部文件转换为文档树
index.html
1
2
3
4
5 # 注意,此处缺少一个 闭合标签
test.py
from lxml import etree
# 读取外部文件 index.html
html = etree.parse('./index.html')
result = etree.tostring(html, pretty_print=True) #pretty_print=True 会格式化输出
print(result)
1.路径表达式
表达式描述nodename选取此节点的所有子节点/从根节点选取//从匹配选择的当前节点选择文档中的节点,而不考虑他们的位置.选取当前节点…选取当前节点的父节点@选取属性2. 通配符(匹配任意节点)
通配符描述*任意元素@*任意属性node()任意子节点(元素,属性,内容)3.谓语
使用中括号来限定元素,称为谓语
表达式描述//a[3]代表子元素排在第3个位置的元素//a[last()]last() 代表子元素排在最后个位置的元素//a[last()-1]和上面同理,代表倒数第二个//a[position() < 3]位置序号小于3,也就是前两个,这里我们可以看出xpath中的序列是从1开始//a[@href]拥有href的元素//a[@href=‘www’]href属性值为’www’的元素//book[@price>2]price值大于2的元素4.多个路径
用 | 连接两个表达式,可以进行 或 匹配
//book/title | //book/price
5.常用函数举例
函数举例描述contains()//a[contains(@class,‘a’)] 或 //a[contains(text(),‘b’)]a标签类名包含a字符 或 a标签文字中有包含b的start-with()//a[starts-with(@class,‘a’)]a标签类名开头是a字符的,注意没有ends-withtext()//span/text()span标签下的文字last()//span[last()]取最后一个span标签position()//span[position()❤️] 或 //li[position()=2]取前两个位置的span标签 或 li中第二个位置node()//ul/node()返回ul的所有子节点,不管这个子节点是什么类型(熟悉,元素,内容)6.获取文本内容的两种方式( text() 和.text)
from lxml import etree
doc = '''
- 1
- 2
- 4
wwwww
'''
html = etree.XML(doc)
print(html.xpath("//a/text()")) # ['1', '2' ]
print(html.xpath("//a")[0].text) # 1
print(html.xpath("//ul")[0].text) # 一堆空格
print(html.xpath("//ul/text()")) # ['\n ', '\n ', '\n ', '\n wwwww\n ']

7.etree.tostring()将对象转为字符串
from lxml import etree
doc = '''
- 1
- 2
- 4
wwwww
'''
html = etree.HTML(doc)
ele = etree.tostring(html.xpath('//li[1]')[0])
print ele
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GzInqSTv-1602229835206)(C:\Users\qinfan\AppData\Roaming\Typora\typora-user-images\1602229783554.png)]](https://img-blog.csdnimg.cn/2020100915505664.png#pic_center) 8.xpath中的轴
8.xpath中的轴
总共有八个轴关键字,parent,child,ancestor祖先,descendant后裔,following,following-sibling兄弟姐妹,preceding,preceding-sibling。具体含义如下:
表达式描述parent::div上层父节点,你那叫div的亲生爸爸,最多有一个;child::div下层所有子节点,你的所有亲儿子中叫div的;ancestor::div上面所有直系节点,是你亲生爸爸或者你亲爹或者你亲爹的爸爸中叫div的;descendant::div下面所有节点,你的后代中叫div的,不包括你弟弟的后代;following::div自你以下页面中所有节点叫div的;following-sibling::div同层下节点,你所有的亲弟弟中叫div的;preceding::div同层上节点,你所有的亲哥哥以及他们的后代中叫div的;preceding-sibling::div同层上节点,你所有的亲哥哥中叫div的;轴参考文章:https://www.bbsmax.com/A/kvJ33W3nJg/
三、使用xpath过程中遇到的常见问题总结 1.对于xpath中含有命名空间的xml文件解析有以下xml文件,当我想提取< itunes:episode >标签内容
姑苏城里写代码
58
Tue, 31 Dec 2019 06:55:00 CDT
本期由 Galway 主持,请到了一位在苏州工作的朋友,聊聊为什么离开大城市,以及苏州的工作生活。
哈哈哈
嘻嘻嘻
嘿嘿嘿
当我使用常用的xpath方法提取的时候
from lxml import etree
html = etree.HTML(a)
num = html.xpath('//itunes:episode')
print(num)
结果: 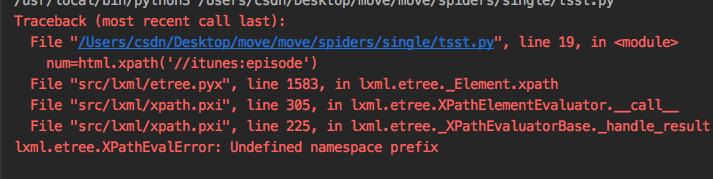 对于此类问题,经过查询是命名空间问题,详情见文章:xpath的命名空间
对于此类问题,经过查询是命名空间问题,详情见文章:xpath的命名空间
解决方案1:
from lxml import etree
a = '''
姑苏城里写代码
58
Tue, 31 Dec 2019 06:55:00 CDT
本期由 Galway 主持,请到了一位在苏州工作的朋友,聊聊为什么离开大城市,以及苏州的工作生活。
- 哈哈哈
- 嘻嘻嘻
- 嘿嘿嘿
'''
html = etree.HTML(a)
num = html.xpath('//episode/text()')
print(num)
解决方案2:
在scrapy中使用
num = html.xpath("*[contains(name(), 'itunes:episode/text()")
解决方案3:
在scrapy中,xml为获取的response.text
from lxml import etree
dom = etree.XML(xml)
aid = dom.xpath('//itunes:episode/text()', namespaces=dom.nsmap)
print(aid)
结果:
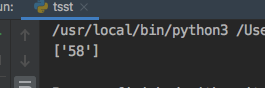
# 标签中只包含文字
卷期号:
取包含 卷期号 三个字的节点:
//ul[@id=‘side-menu’]/li/a[contains(text(),“卷期号”)]
取其内容
//ul[@id=‘side-menu’]/li/a[contains(text(), ‘卷期号’)]/text()
例如我们使用爬虫爬取到一篇文章,但是该文章有一些影响标签(例如打赏),那么我们可以使用如下方法删除该标签:
解决方案1:字符串的strip
# 使用xpath寻找需要删除的div,如果该标签存在,那么在原文章理使用strip方法删除
del_div = response.xpath(del_xpath).extract_first()
if del_div:
article = article.strip(del_div)
解决方案2:清除xpath中无用的标签
from lxml import etree
def remove_div(content, del_xpath):
try:
dom = etree.HTML(content) # 将字符串内容转为etree对象
reward_node = dom.xpath(del_xpath)[0] # 寻找删除的xpath对象
reward_node.xpath('..')[0].remove(reward_node) # 寻找删除xpath对象的上级,将该标签删除
return etree.tostring(dom[0], encoding='utf-8').decode('utf-8')
except Exception as e:
print(e)
return content


