文章目录
爬取网站的流程
- 爬取网站的流程
- 案例一:使用xpath爬取扇贝英语单词
- 案例二:爬取网易云音乐的所有歌手名字
- 案例三:爬取酷狗音乐的歌手和歌单
- 确定网站的哪个url是数据的来源
- 简要分析一下网站结构,查看数据存放在哪里
- 查看是否有分页,并解决分页的问题
- 发送请求,查看response.text是否有我们所需要的数据
- 筛选数据
需求:爬取三页单词 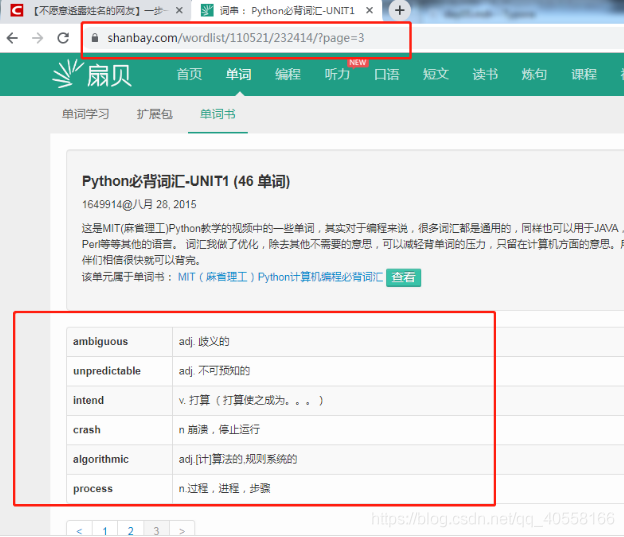
import json
import requests
from lxml import etree
base_url = 'https://www.shanbay.com/wordlist/110521/232414/?page=%s'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
def get_text(value):
if value:
return value[0]
return ''
word_list = []
for i in range(1, 4):
# 发送请求
response = requests.get(base_url % i, headers=headers)
# print(response.text)
html = etree.HTML(response.text)
tr_list = html.xpath('//tbody/tr')
# print(tr_list)
for tr in tr_list:
item = {}#构造单词列表
en = get_text(tr.xpath('.//td[@class="span2"]/strong/text()'))
tra = get_text(tr.xpath('.//td[@class="span10"]/text()'))
print(en, tra)
if en:
item[en] = tra
word_list.append(item)
面向对象:
import requests
from lxml import etree
class Shanbei(object):
def __init__(self):
self.base_url = 'https://www.shanbay.com/wordlist/110521/232414/?page=%s'
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
self.word_list = []
self.parse()
def get_text(self, value):
# 防止为空报错
if value:
return value[0]
return ''
def parse(self):
for i in range(1, 4):
# 发送请求
response = requests.get(self.base_url % i, headers=self.headers)
# print(response.text)
html = etree.HTML(response.text)
tr_list = html.xpath('//tbody/tr')
# print(tr_list)
for tr in tr_list:
item = {} # 构造单词列表
en = self.get_text(tr.xpath('.//td[@class="span2"]/strong/text()'))
tra = self.get_text(tr.xpath('.//td[@class="span10"]/text()'))
print(en, tra)
if en:
item[en] = tra
self.word_list.append(item)
shanbei = Shanbei()
import requests,json
from lxml import etree
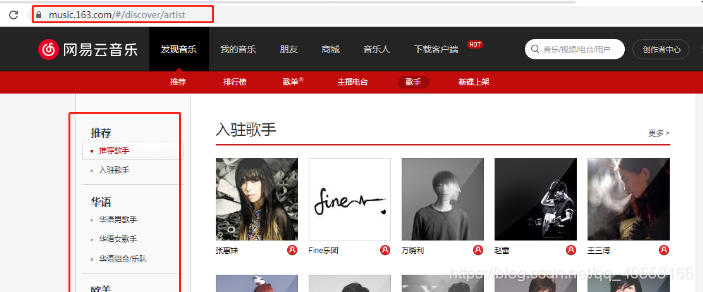
url = 'https://music.163.com/discover/artist'
singer_infos = []
# ---------------通过url获取该页面的内容,返回xpath对象
def get_xpath(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
response = requests.get(url, headers=headers)
return etree.HTML(response.text)
# --------------通过get_xpath爬取到页面后,我们获取华宇,华宇男等分类
def parse():
html = get_xpath(url)
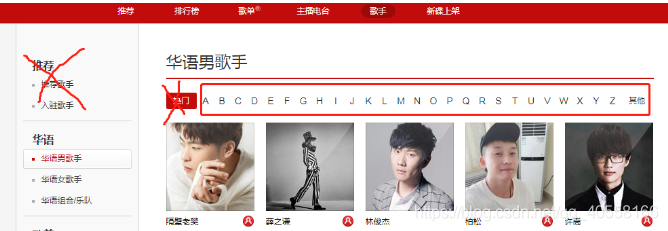
fenlei_url_list = html.xpath('//ul[@class="nav f-cb"]/li/a/@href') # 获取华宇等分类的url
# print(fenlei_url_list)
# --------将热门和推荐两栏去掉筛选
new_list = [i for i in fenlei_url_list if 'id' in i]
for i in new_list:
fenlei_url = 'https://music.163.com' + i
parse_fenlei(fenlei_url)
# print(fenlei_url)
# -------------通过传入的分类url,获取A,B,C页面内容
def parse_fenlei(url):
html = get_xpath(url)
# 获得字母排序,每个字母的链接
zimu_url_list = html.xpath('//ul[@id="initial-selector"]/li[position()>1]/a/@href')
for i in zimu_url_list:
zimu_url = 'https://music.163.com' + i
parse_singer(zimu_url)
# ---------------------传入获得的字母链接,开始爬取歌手内容
def parse_singer(url):
html = get_xpath(url)
item = {}
singer_names = html.xpath('//ul[@id="m-artist-box"]/li/p/a/text()')
# --详情页看到页面结构会有两个a标签,所以取第一个
singer_href = html.xpath('//ul[@id="m-artist-box"]/li/p/a[1]/@href')
# print(singer_names,singer_href)
for i, name in enumerate(singer_names):
item['歌手名'] = name
item['音乐链接'] = 'https://music.163.com' + singer_href[i].strip()
# 获取歌手详情页的链接
url = item['音乐链接'].replace(r'?id', '/desc?id')
# print(url)
parse_detail(url, item)
print(item)
# ---------获取详情页url和存着歌手名字和音乐列表的字典,在字典中添加详情页数据
def parse_detail(url, item):
html = get_xpath(url)
desc_list = html.xpath('//div[@class="n-artdesc"]/p/text()')
item['歌手信息'] = desc_list
singer_infos.append(item)
write_singer(item)
# ----------------将数据字典写入歌手文件
def write_singer(item):
with open('singer.json', 'a+', encoding='utf-8') as file:
json.dump(item,file)
if __name__ == '__main__':
parse()
面向对象
import json, requests
from lxml import etree
class Wangyiyun(object):
def __init__(self):
self.url = 'https://music.163.com/discover/artist'
self.singer_infos = []
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
self.parse()
# ---------------通过url获取该页面的内容,返回xpath对象
def get_xpath(self, url):
response = requests.get(url, headers=self.headers)
return etree.HTML(response.text)
# --------------通过get_xpath爬取到页面后,我们获取华宇,华宇男等分类
def parse(self):
html = self.get_xpath(self.url)
fenlei_url_list = html.xpath('//ul[@class="nav f-cb"]/li/a/@href') # 获取华宇等分类的url
# print(fenlei_url_list)
# --------将热门和推荐两栏去掉筛选
new_list = [i for i in fenlei_url_list if 'id' in i]
for i in new_list:
fenlei_url = 'https://music.163.com' + i
self.parse_fenlei(fenlei_url)
# print(fenlei_url)
# -------------通过传入的分类url,获取A,B,C页面内容
def parse_fenlei(self, url):
html = self.get_xpath(url)
# 获得字母排序,每个字母的链接
zimu_url_list = html.xpath('//ul[@id="initial-selector"]/li[position()>1]/a/@href')
for i in zimu_url_list:
zimu_url = 'https://music.163.com' + i
self.parse_singer(zimu_url)
# ---------------------传入获得的字母链接,开始爬取歌手内容
def parse_singer(self, url):
html = self.get_xpath(url)
item = {}
singer_names = html.xpath('//ul[@id="m-artist-box"]/li/p/a/text()')
# --详情页看到页面结构会有两个a标签,所以取第一个
singer_href = html.xpath('//ul[@id="m-artist-box"]/li/p/a[1]/@href')
# print(singer_names,singer_href)
for i, name in enumerate(singer_names):
item['歌手名'] = name
item['音乐链接'] = 'https://music.163.com' + singer_href[i].strip()
# 获取歌手详情页的链接
url = item['音乐链接'].replace(r'?id', '/desc?id')
# print(url)
self.parse_detail(url, item)
print(item)
# ---------获取详情页url和存着歌手名字和音乐列表的字典,在字典中添加详情页数据
def parse_detail(self, url, item):
html = self.get_xpath(url)
desc_list = html.xpath('//div[@class="n-artdesc"]/p/text()')[0]
item['歌手信息'] = desc_list
self.singer_infos.append(item)
self.write_singer(item)
# ----------------将数据字典写入歌手文件
def write_singer(self, item):
with open('sing.json', 'a+', encoding='utf-8') as file:
json.dump(item, file)
music = Wangyiyun()
需求:爬取酷狗音乐的歌手和歌单和歌手简介 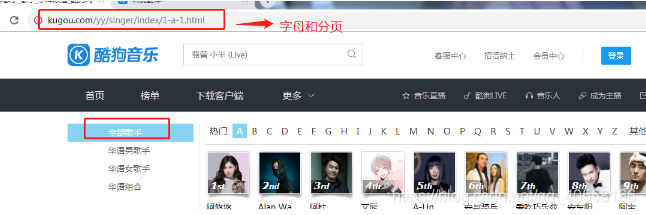
import json, requests
from lxml import etree
base_url = 'https://www.kugou.com/yy/singer/index/%s-%s-1.html'
# ---------------通过url获取该页面的内容,返回xpath对象
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36'
}
# ---------------通过url获取该页面的内容,返回xpath对象
def get_xpath(url, headers):
try:
response = requests.get(url, headers=headers)
return etree.HTML(response.text)
except Exception:
print(url, '该页面没有相应!')
return ''
# --------------------通过歌手详情页获取歌手简介
def parse_info(url):
html = get_xpath(url, headers)
info = html.xpath('//div[@class="intro"]/p/text()')
return info
# --------------------------写入方法
def write_json(value):
with open('kugou.json', 'a+', encoding='utf-8') as file:
json.dump(value, file)
# -----------------------------用ASCII码值来变换abcd...
for j in range(97, 124):
# 小写字母为97-122,当等于123的时候我们按歌手名单的其他算,路由为null
if j
关注
打赏


