K最近邻 (k-Nearest Neighbors,KNN) 算法是一种分类算法,也是最简单 易懂的机器学习算法,没有之一。1968年由 Cover 和 Hart 提出,应用场景有 字符识别、文本分类、图像识别等领域。 算法思想:一个样本与数据集 中的k个样本最相似,如果这k个样本中的大多数属于某一个类别,则该样本也 属于这个类别 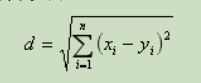 其中x,y为2个样本,n为维度,xi,yi为x,y第i个维度上的特征值。
其中x,y为2个样本,n为维度,xi,yi为x,y第i个维度上的特征值。
案例说明:上面数据集中序号1-12为已知的电影分类,分为喜剧片、动作 片、爱情片三个种类,使用的特征值分别为搞笑镜头、打斗镜头、拥抱镜头的数 量。那么来了一部新电影《唐人街探案》,它属于上述3个电影分类中的哪个类型?用KNN是怎么做的呢? 
import math
# 第一步:使用Python的字典dict构造数据集
movie_data = {"宝贝当家": [45, 2, 9, "喜剧片"],
"美人鱼": [21, 17, 5, "喜剧片"],
"澳门风云3": [54, 9, 11, "喜剧片"],
"功夫熊猫3": [39, 0, 31, "喜剧片"],
"谍影重重": [5, 2, 57, "动作片"],
"叶问3": [3, 2, 65, "动作片"],
"伦敦陷落": [2, 3, 55, "动作片"],
"我的特工爷爷": [6, 4, 21, "动作片"],
"奔爱": [7, 46, 4, "爱情片"],
"夜孔雀": [9, 39, 8, "爱情片"],
"代理情人": [9, 38, 2, "爱情片"],
"新步步惊心": [8, 34, 17, "爱情片"]}
# 第二步:计算一个新样本与数据集中所有数据的距离
x = [23, 3, 17]
KNN = []
for k, v in movie_data.items():
distance = math.sqrt((v[0] - x[0]) ** 2 + (v[1] - x[1]) ** 2 + (v[2] - x[2]) ** 2)
KNN.append([distance, v[3]])
# 第三步:排序后的KNN,并取出前五个
KNN = sorted(KNN, key=lambda x: x[0])[:5]
# 第四步:取出前五个的电影类型
tp_list = [v[1] for v in KNN]
# 第五步:求出列表中每个元素出现的次数
tp_dict = {}
for i in tp_list:
tp_dict[i] = tp_dict.get(i, 0) + 1
# 第六步:求出字典的最大值
result = max(tp_dict, key=lambda key: tp_dict[key])
print('唐人街探案的电影类型为:', result)

(1)KNN属于惰性学习(lazy-learning) 这是与急切学习(eager learning)相对应的,因为KNN没有显式的学习过 程!也就是说没有训练阶段,从上面的例子就可以看出,数据集事先已有了分类 和特征值,待收到新样本后直接进行处理。 (2)KNN的计算复杂度较高 我们从上面的例子可以看到,新样本需要与数据集中每个数据进行距离计 算,计算复杂度和数据集中的数据数目n成正比,也就是说,KNN的时间复杂度为 O(n),因此KNN一般适用于样本数较少的数据集。 (3)k取不同值时,分类结果可能会有显著不同。 k值选择中,如果设置较小的k值,说明在较小的范围内进行训练和统计,误 差较大且容易产生过拟合的情况;k值较大时意味着在较大的范围中学习,可以 减少学习的误差,但是在其统计范围变大了,说明模型变简单了,容易在预测的 时候发生分类错误。 上例中,如果k取值为k=1,那么分类就是动作片,而不是喜剧片。一般k的 取值不超过20,上限是n的开方。 KNN算法的主要缺点:在各分类样本数量不平衡时误差较大;由于其每次比较 都要遍历整个训练样本集来计算相似度,所以分类的效率较低,时间和空间的复 杂度较高;k值的选择不合理,可能导致结果的误差较大;在原始KNN模型中没有 权重概念,所有特征采用相同的权重参数,这样计算出来的相似度易产生误差


