
- 引言
- 回顾:一维高斯分布
- 多维高斯分布
- 高斯分布的局限性(2022/11/18)
- 回顾:协方差矩阵,马氏距离
- 局限性的具体体现
- 总结
在使用极大似然估计计算高斯分布最优参数一节中介绍了一维高斯分布。具体表示如下: x ∼ N ( μ , σ 2 ) = 1 2 π σ exp { − ( x − μ ) 2 2 σ 2 } x \sim \mathcal N(\mu,\sigma^2) = \frac{1}{\sqrt{2\pi}\sigma} \exp \left\{-\frac{(x - \mu)^2}{2\sigma^2} \right\} x∼N(μ,σ2)=2π σ1exp{−2σ2(x−μ)2}
其中 x , μ , σ x,\mu,\sigma x,μ,σ均属于一维矩阵,即标量。
多维高斯分布多维高斯分布与一维高斯分布的明显区别是:随机变量 x x x,期望 μ \mu μ以多维向量的形式出现,方差以多维矩阵的形式出现(方阵)。 随机变量定义: 数据集合 X \mathcal X X包含 N N N个样本: X = { x ( 1 ) , x ( 2 ) , ⋯ , x ( N ) } \mathcal X = \left\{x^{(1)},x^{(2)},\cdots,x^{(N)} \right\} X={x(1),x(2),⋯,x(N)} 其中, X \mathcal X X中 任意样本 x ( i ) ( i ∈ { 1 , 2 , ⋯ , N } ) x^{(i)}(i \in \{1,2,\cdots,N\}) x(i)(i∈{1,2,⋯,N})均属于 p p p维随机变量,记作 x ( i ) ∈ R p x^{(i)} \in \mathbb R^{p} x(i)∈Rp; 以样本 x ( i ) x^{(i)} x(i)为例,其向量表示如下: x ( i ) = ( x 1 ( i ) , x 2 ( i ) , ⋯ , x p ( i ) ) p × 1 T x^{(i)} = \left(x_1^{(i)},x_2^{(i)},\cdots,x_p^{(i)} \right)_{p \times 1}^{T} x(i)=(x1(i),x2(i),⋯,xp(i))p×1T 期望 μ \mu μ同样属于 p p p维随机变量。每一维度值表示数据集合中所有样本对应该维度值的期望结果。 μ \mu μ的向量表示如下: μ = ( μ 1 , μ 2 , ⋯ , μ p ) \mu = (\mu_1,\mu_2,\cdots,\mu_p) μ=(μ1,μ2,⋯,μp)
Σ
\Sigma
Σ表示协方差矩阵。它的定义表示如下:
x
x
x表示‘宏观意义’上的样本;任意样本。
Σ
=
E
[
(
x
−
μ
)
(
x
−
μ
)
T
]
\Sigma = \mathbb E[(x - \mu)(x - \mu)^{T}]
Σ=E[(x−μ)(x−μ)T] 由于多维高斯分布中
x
,
μ
x,\mu
x,μ均为
p
p
p维向量。因此,将
x
=
(
x
1
,
x
2
,
⋯
,
x
p
)
,
μ
=
(
μ
1
,
μ
2
,
⋯
,
μ
p
)
x = (x_1,x_2,\cdots,x_p),\mu = (\mu_1,\mu_2,\cdots,\mu_p)
x=(x1,x2,⋯,xp),μ=(μ1,μ2,⋯,μp)带入上式:
Σ
=
E
[
(
x
1
−
μ
1
)
2
,
(
x
1
−
μ
1
)
(
x
2
−
μ
2
)
,
⋯
,
(
x
1
−
μ
1
)
(
x
p
−
μ
p
)
(
x
2
−
μ
2
)
(
x
1
−
μ
1
)
,
(
x
2
−
μ
2
)
2
,
⋯
,
(
x
2
−
μ
2
)
(
x
p
−
μ
p
)
⋮
(
x
p
−
μ
p
)
(
x
1
−
μ
1
)
,
(
x
p
−
μ
p
)
(
x
2
−
μ
2
)
,
⋯
,
(
x
p
−
μ
p
)
2
]
=
(
σ
11
,
σ
12
,
⋯
,
σ
1
p
σ
21
,
σ
22
,
⋯
,
σ
2
p
⋮
σ
p
1
,
σ
p
2
,
⋯
,
σ
p
p
)
p
×
p
\Sigma = \mathbb E \begin{bmatrix} (x_1 - \mu_1)^2,(x_1 - \mu_1)(x_2 - \mu_2),\cdots,(x_1 - \mu_1)(x_p - \mu_p) \\ (x_2 - \mu_2)(x_1 - \mu_1),(x_2 - \mu_2)^2,\cdots,(x_2 - \mu_2)(x_p - \mu_p) \\ \vdots \\ (x_p - \mu_p)(x_1 - \mu_1),(x_p - \mu_p)(x_2 - \mu_2),\cdots,(x_p - \mu_p)^2 \end{bmatrix}= \begin{pmatrix} \sigma_{11},\sigma_{12},\cdots,\sigma_{1p} \\ \sigma_{21},\sigma_{22},\cdots,\sigma_{2p} \\ \vdots \\ \sigma_{p1},\sigma_{p2},\cdots,\sigma_{pp} \end{pmatrix}_{p \times p}
Σ=E
(x1−μ1)2,(x1−μ1)(x2−μ2),⋯,(x1−μ1)(xp−μp)(x2−μ2)(x1−μ1),(x2−μ2)2,⋯,(x2−μ2)(xp−μp)⋮(xp−μp)(x1−μ1),(xp−μp)(x2−μ2),⋯,(xp−μp)2
=
σ11,σ12,⋯,σ1pσ21,σ22,⋯,σ2p⋮σp1,σp2,⋯,σpp
p×p 观察上述矩阵,发现
σ
i
j
=
σ
j
i
=
E
[
(
x
i
−
μ
i
)
(
x
j
−
μ
j
)
]
\sigma_{ij} = \sigma_{ji} = \mathbb E[(x_i - \mu_i)(x_j - \mu_j)]
σij=σji=E[(xi−μi)(xj−μj)]。因此,协方差矩阵
Σ
\Sigma
Σ是 实对称矩阵。并且
σ
i
i
=
(
x
i
−
μ
i
)
2
≥
0
(
i
=
1
,
2
,
⋯
,
p
)
\sigma_{ii} = (x_i - \mu_i)^2 \geq0(i = 1,2,\cdots,p)
σii=(xi−μi)2≥0(i=1,2,⋯,p)恒成立。因此
Σ
\Sigma
Σ至少是半正定矩阵。 不排除
σ
i
i
=
0
\sigma_{ii}=0
σii=0的情况发生,因此这个协方差矩阵不一定是‘正定矩阵’。但在推导过程中暂时设定为‘正定矩阵’。
多维高斯分布的概率密度函数表示如下: 从‘概率模型’角度将高斯分布表示为
P
(
x
∣
μ
,
Σ
)
P(x \mid \mu,\Sigma)
P(x∣μ,Σ)
x
∼
N
(
μ
,
Σ
)
=
P
(
x
∣
μ
,
Σ
)
=
1
(
2
π
)
p
2
⋅
∣
Σ
∣
1
2
exp
{
−
1
2
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
}
x \sim \mathcal N(\mu,\Sigma) = P(x \mid \mu,\Sigma) = \frac{1}{(2\pi)^{\frac{p}{2}}\cdot|\Sigma|^{\frac{1}{2}}} \exp \left\{-\frac{1}{2}(x - \mu)^{T} \Sigma^{-1} (x -\mu) \right\}
x∼N(μ,Σ)=P(x∣μ,Σ)=(2π)2p⋅∣Σ∣211exp{−21(x−μ)TΣ−1(x−μ)} 其中,
∣
Σ
∣
|\Sigma|
∣Σ∣表示协方差矩阵的行列式结果;
Σ
−
1
\Sigma^{-1}
Σ−1表示协方差矩阵的逆矩阵。
观察:如果将 x x x看作自变量/需要求解的量, μ , Σ \mu,\Sigma μ,Σ看作多维高斯分布 N ( μ , Σ ) \mathcal N(\mu,\Sigma) N(μ,Σ)的参数,则整个概率密度函数公式中和 x x x有关的部分只有: ( x − μ ) T Σ − 1 ( x − μ ) (x - \mu)^{T} \Sigma^{-1}(x - \mu) (x−μ)TΣ−1(x−μ) 首先观察它的维度: ( x − μ ) (x - \mu) (x−μ)是 p × 1 p\times 1 p×1维向量, ( x − μ ) T (x - \mu)^{T} (x−μ)T自然是 1 × p 1\times p 1×p维向量;协方差矩阵的逆不改变维度: Σ − 1 → p × p \Sigma^{-1} \to p \times p Σ−1→p×p;因此, ( x − μ ) T Σ − 1 ( x − μ ) (x - \mu)^{T} \Sigma^{-1}(x - \mu) (x−μ)TΣ−1(x−μ)本质上是一个一维矩阵,是个标量,是一个具体数值。
这里引进一个概念:马氏距离( Mahalanobis distance \text{Mahalanobis distance} Mahalanobis distance)。它描述的是两个向量(高维空间内两个数据点)之间的距离描述。马氏距离传送门 例如 p p p维空间的两个数据点: x = ( x 1 , x 2 , ⋯ , x p ) T y = ( y 1 , y 2 , ⋯ , y p ) T x = (x_1,x_2,\cdots,x_p)^{T} \\ y=(y_1,y_2,\cdots,y_p)^{T} x=(x1,x2,⋯,xp)Ty=(y1,y2,⋯,yp)T 它们的马氏距离表示如下: D M ( x , y ) = ( x − y ) T Σ − 1 ( x − y ) {\mathcal D}_{M}(x,y) = \sqrt{(x - y)^{T}\Sigma^{-1}(x - y)} DM(x,y)=(x−y)TΣ−1(x−y)
在这里可以将 ( x − μ ) T Σ − 1 ( x − μ ) (x - \mu)^{T} \Sigma^{-1}(x - \mu) (x−μ)TΣ−1(x−μ)视作样本点 x x x与样本均值向量 μ \mu μ之间的马氏距离。
如果 Σ − 1 \Sigma^{-1} Σ−1是单位矩阵,马氏距离将退化为欧式距离( Euclidean Distance \text{Euclidean Distance} Euclidean Distance)
假设协方差矩阵是正定矩阵,对协方差矩阵进行特征值分解: 如果协方差矩阵是一般情况下的‘半正定’,那么
Σ
\Sigma
Σ自然是不能求逆的,
Σ
−
1
\Sigma^{-1}
Σ−1是不存在的。
Σ
=
U
Λ
U
T
\Sigma = U \Lambda U^{T}
Σ=UΛUT 根据特征值分解定义,
U
U
U是一个正交矩阵,即:
U
U
T
=
U
T
U
=
I
UU^{T} = U^{T}U = I
UUT=UTU=I 其中
I
\mathcal I
I表示单位矩阵,
U
,
I
U,I
U,I矩阵格式均为
p
×
p
p\times p
p×p。将正交矩阵
U
U
U定义为
(
u
1
,
u
2
,
⋯
,
u
p
)
(u_1,u_2,\cdots,u_p)
(u1,u2,⋯,up);其中
u
i
(
i
=
1
,
2
,
⋯
,
p
)
u_i(i=1,2,\cdots,p)
ui(i=1,2,⋯,p)看作
p
×
1
p \times 1
p×1维向量。
Λ
\Lambda
Λ表示特征值向量,对角线上元素为
Σ
\Sigma
Σ矩阵的特征值。 根据上式则有:
Σ
=
U
Λ
U
T
=
(
u
1
,
u
2
,
⋯
,
u
p
)
(
λ
0
,
0
,
⋯
,
0
0
,
λ
1
,
⋯
,
0
⋮
0
,
0
,
⋯
,
λ
p
)
(
u
1
T
u
2
T
⋮
u
p
T
)
=
(
u
1
λ
1
,
u
2
λ
2
,
⋯
,
u
p
λ
p
)
(
u
1
T
u
2
T
⋮
u
p
T
)
=
u
1
λ
1
u
1
T
+
u
2
λ
2
u
2
T
+
⋯
+
u
p
λ
p
u
p
T
\begin{aligned} \Sigma & = U \Lambda U^{T} \\ & = (u_1,u_2,\cdots,u_p)\begin{pmatrix}\lambda_0 ,0,\cdots,0 \\ 0,\lambda_1,\cdots,0 \\ \vdots \\ 0,0,\cdots ,\lambda_p\end{pmatrix}\begin{pmatrix}u_1^{T} \\u_2^{T}\\ \vdots \\ u_p^{T}\end{pmatrix}\\ & = (u_1\lambda_1,u_2\lambda_2,\cdots,u_p\lambda_p) \begin{pmatrix}u_1^{T} \\u_2^{T}\\ \vdots \\ u_p^{T}\end{pmatrix} \\ & = u_1 \lambda_1 u_1^{T} + u_2 \lambda_2 u_2^{T} + \cdots +u_p \lambda_p u_p^{T} \end{aligned}
Σ=UΛUT=(u1,u2,⋯,up)
λ0,0,⋯,00,λ1,⋯,0⋮0,0,⋯,λp
u1Tu2T⋮upT
=(u1λ1,u2λ2,⋯,upλp)
u1Tu2T⋮upT
=u1λ1u1T+u2λ2u2T+⋯+upλpupT 由于
λ
1
,
λ
2
,
⋯
,
λ
p
\lambda_1,\lambda_2,\cdots,\lambda_p
λ1,λ2,⋯,λp是特征值,是常数,因此可以提到前面,
u
i
u
i
T
u_iu_i^{T}
uiuiT结果是
p
×
p
p \times p
p×p的方阵;
Σ
=
∑
i
=
1
p
λ
i
u
i
u
i
T
\Sigma = \sum_{i=1}^p\lambda_iu_iu_i^{T}
Σ=i=1∑pλiuiuiT 基于上式,通过
Σ
\Sigma
Σ求解
Σ
−
1
\Sigma^{-1}
Σ−1: 正交阵的性质,正交阵的转置等于该正交阵的逆。即:
U
T
=
U
−
1
U^{T} = U^{-1}
UT=U−1
Σ
−
1
=
(
U
Λ
U
T
)
−
1
=
(
U
T
)
−
1
Λ
−
1
U
−
1
=
U
Λ
−
1
U
T
=
∑
i
=
1
p
1
λ
i
u
i
u
i
T
\begin{aligned} \Sigma^{-1} & = (U \Lambda U^{T})^{-1} \\ & = (U^{T})^{-1} \Lambda^{-1}U^{-1} \\ & = U \Lambda^{-1}U^{T} \\ & = \sum_{i=1}^p \frac{1}{\lambda_i}u_iu_i^{T} \end{aligned}
Σ−1=(UΛUT)−1=(UT)−1Λ−1U−1=UΛ−1UT=i=1∑pλi1uiuiT 将
Σ
−
1
\Sigma^{-1}
Σ−1带入
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
(x - \mu)^{T} \Sigma^{-1}(x - \mu)
(x−μ)TΣ−1(x−μ),则有:
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
=
(
x
−
μ
)
T
[
∑
i
=
1
p
1
λ
i
u
i
u
i
T
]
(
x
−
μ
)
\begin{aligned} (x - \mu)^{T} \Sigma^{-1}(x - \mu) & = (x - \mu)^{T} \left[\sum_{i=1}^p \frac{1}{\lambda_i}u_iu_i^{T}\right](x - \mu) \end{aligned}
(x−μ)TΣ−1(x−μ)=(x−μ)T[i=1∑pλi1uiuiT](x−μ)
观察, ( x − μ ) T (x -\mu)^{T} (x−μ)T是 1 × p 1 \times p 1×p的向量; ∑ i = 1 p 1 λ i u i u i T \begin{aligned}\sum_{i=1}^p \frac{1}{\lambda_i}u_iu_i^{T} \end{aligned} i=1∑pλi1uiuiT是 p × p p \times p p×p维向量; ( x − μ ) (x - \mu) (x−μ)是 p × 1 p \times 1 p×1维向量。 因此, ( x − μ ) T [ ∑ i = 1 p 1 λ i u i u i T ] ( x − μ ) \begin{aligned}(x - \mu)^{T} \left[\sum_{i=1}^p \frac{1}{\lambda_i}u_iu_i^{T}\right](x - \mu) \end{aligned} (x−μ)T[i=1∑pλi1uiuiT](x−μ)仍然是一个标量、一个数值。 将 ( x − μ ) T , ( x − μ ) (x -\mu)^T,(x - \mu) (x−μ)T,(x−μ)两个向量看成整体,不执行任何拆分,将 ∑ i = 1 p 1 λ i \begin{aligned}\sum_{i=1}^p \frac{1}{\lambda_i}\end{aligned} i=1∑pλi1提出来: ∑ i = 1 p 1 λ i ( x − μ ) T [ u i u i T ] ( x − μ ) \sum_{i=1}^p \frac{1}{\lambda_i}(x - \mu)^{T} \left[u_iu_i^{T}\right] (x - \mu) i=1∑pλi1(x−μ)T[uiuiT](x−μ) 令向量 k = ( k 1 k 2 ⋮ k p ) p × 1 k = \begin{pmatrix}k_1 \\k_2\\\vdots \\k_p\end{pmatrix}_{p \times 1} k= k1k2⋮kp p×1, k i ( i = 1 , 2 , ⋯ , p ) = ( x − μ ) T u i k_i(i=1,2,\cdots,p) = (x - \mu)^{T}u_i ki(i=1,2,⋯,p)=(x−μ)Tui
上式可转化为: I = ∑ i = 1 p 1 λ i ( x − μ ) T u i ⋅ [ ( x − μ ) T u i ] T = ∑ i = 1 p 1 λ i k i k i T \begin{aligned} \mathcal I & = \sum_{i=1}^p \frac{1}{\lambda_i} (x - \mu)^Tu_i \cdot \left[(x - \mu)^Tu_i\right]^T \\ & = \sum_{i=1}^p \frac{1}{\lambda_i}k_ik_i^{T} \end{aligned} I=i=1∑pλi1(x−μ)Tui⋅[(x−μ)Tui]T=i=1∑pλi1kikiT
由于 k k k的定义,因此, k i ( i = 1 , 2 , ⋯ , p ) k_i(i=1,2,\cdots,p) ki(i=1,2,⋯,p)是标量、数值。即: k i T = k i k_i^{T} = k_i kiT=ki 则有: ( x − μ ) T Σ − 1 ( x − μ ) = ∑ i = 1 p 1 λ i k i k i T = ∑ i = 1 p k i 2 λ i ( i = 1 , 2 , ⋯ , p ) \begin{aligned} (x - \mu)^{T} \Sigma^{-1}(x - \mu) & = \sum_{i=1}^p \frac{1}{\lambda_i}k_ik_i^{T} \\ & = \sum_{i=1}^p \frac{k_i^2}{\lambda_i}(i=1,2,\cdots,p) \end{aligned} (x−μ)TΣ−1(x−μ)=i=1∑pλi1kikiT=i=1∑pλiki2(i=1,2,⋯,p)
将上述结果展开: ∑ i = 1 p k i 2 λ i = k 1 2 λ 1 + k 2 2 λ 2 + ⋯ + k p 2 λ p \sum_{i=1}^p \frac{k_i^2}{\lambda_i} = \frac{k_1^2}{\lambda_1} + \frac{k_2^2}{\lambda_2} +\cdots + \frac{k_p^2}{\lambda_p} i=1∑pλiki2=λ1k12+λ2k22+⋯+λpkp2
如果给定上述结果一个具体的值: Δ \Delta Δ 则有: k 1 2 λ 1 + k 2 2 λ 2 + ⋯ + k p 2 λ p = Δ 1 Δ ( k 1 2 λ 1 + k 2 2 λ 2 + ⋯ + k p 2 λ p ) = 1 k 1 2 Δ λ 1 + k 2 2 Δ λ 2 + ⋯ + k p 2 Δ λ p = 1 \begin{aligned} \frac{k_1^2}{\lambda_1} + \frac{k_2^2}{\lambda_2} +\cdots + \frac{k_p^2}{\lambda_p} = \Delta \\ \frac{1}{\Delta}(\frac{k_1^2}{\lambda_1} + \frac{k_2^2}{\lambda_2} +\cdots + \frac{k_p^2}{\lambda_p} ) = 1 \\ \frac{k_1^2}{\Delta\lambda_1} + \frac{k_2^2}{\Delta\lambda_2} +\cdots + \frac{k_p^2}{\Delta\lambda_p} = 1 \end{aligned} λ1k12+λ2k22+⋯+λpkp2=ΔΔ1(λ1k12+λ2k22+⋯+λpkp2)=1Δλ1k12+Δλ2k22+⋯+Δλpkp2=1 它就是一个超椭圆形的标准方程。 令 p = 2 p=2 p=2: k 1 2 Δ λ 1 + k 2 2 Δ λ 2 = 1 \frac{k_1^2}{\Delta\lambda_1} + \frac{k_2^2}{\Delta\lambda_2} = 1 Δλ1k12+Δλ2k22=1
它就是一个椭圆的标准方程,其中 a = Δ λ 1 , b = Δ λ 2 a = \sqrt{\Delta\lambda_1},b = \sqrt{\Delta\lambda_2} a=Δλ1 ,b=Δλ2
至此,基于马氏距离 ( x − μ ) T Σ − 1 ( x − μ ) (x - \mu)^{T} \Sigma^{-1}(x - \mu) (x−μ)TΣ−1(x−μ),它执行一次坐标系的映射:
- 原始 p p p维坐标系 x i ( i = 1 , 2 , ⋯ , p ) x_i(i=1,2,\cdots,p) xi(i=1,2,⋯,p);
- 经过一系列变换: k i = ( x − μ ) T u i k_i = (x - \mu)^{T} u_i ki=(x−μ)Tui 将 x x x坐标系先通过平移 μ \mu μ个长度后,再映射到 u u u坐标系中(矩阵乘法的特点)
- k i k_i ki表示在样本 x x x在 u u u坐标系中的映射结果。
- 而马氏距离
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
(x - \mu)^{T} \Sigma^{-1}(x - \mu)
(x−μ)TΣ−1(x−μ)可理解为在
x
x
x映射到
k
k
k之后,构建一个椭圆,而椭圆上的值就是马氏距离的结果。
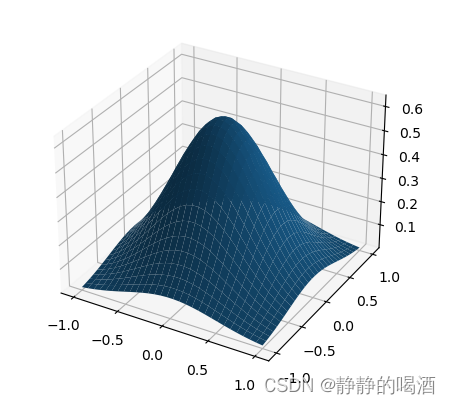 上述表示
i
=
2
i=2
i=2时的高斯分布图像,由于
x
x
x只和
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
(x - \mu)^{T} \Sigma^{-1}(x - \mu)
(x−μ)TΣ−1(x−μ)相关,和表示概率的
1
(
2
π
)
p
2
⋅
∣
Σ
∣
1
2
\begin{aligned}\frac{1}{(2\pi)^{\frac{p}{2}}\cdot|\Sigma|^{\frac{1}{2}}}\end{aligned}
(2π)2p⋅∣Σ∣211无关。
上述表示
i
=
2
i=2
i=2时的高斯分布图像,由于
x
x
x只和
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
(x - \mu)^{T} \Sigma^{-1}(x - \mu)
(x−μ)TΣ−1(x−μ)相关,和表示概率的
1
(
2
π
)
p
2
⋅
∣
Σ
∣
1
2
\begin{aligned}\frac{1}{(2\pi)^{\frac{p}{2}}\cdot|\Sigma|^{\frac{1}{2}}}\end{aligned}
(2π)2p⋅∣Σ∣211无关。
但是概率和 Δ \Delta Δ相关,基于上述标准方程,椭圆的长轴和短轴长度分别是 Δ λ 1 , Δ λ 2 \sqrt{\Delta\lambda_1},\sqrt{\Delta\lambda_2} Δλ1 ,Δλ2 ;选择的 Δ \Delta Δ值直接影响椭圆的大小,从而影响获取横截面的位置。
因此,当概率被确定时,以上述图为例,在 z z z轴对应概率值位置进行横切,而横切得到的横截面必然是椭圆形截面。而 ( x − μ ) T Σ − 1 ( x − μ ) (x - \mu)^{T} \Sigma^{-1}(x - \mu) (x−μ)TΣ−1(x−μ)表示椭圆形上的点。
高斯分布的局限性(2022/11/18) 回顾:协方差矩阵,马氏距离回顾正常情况下(正定条件下) 协方差矩阵的表示:
Σ
=
U
Λ
U
T
U
T
U
=
U
U
T
=
I
\Sigma = \mathcal U \Lambda \mathcal U^T \quad \mathcal U^T\mathcal U = \mathcal U\mathcal U^T = \mathcal I
Σ=UΛUTUTU=UUT=I 其中
I
\mathcal I
I是单位矩阵,由于协方差矩阵自身的性质,
U
\mathcal U
U是各向量两两正交的正交矩阵:
U
=
(
u
1
,
u
2
,
⋯
,
u
p
)
p
×
p
\mathcal U = (u_1,u_2,\cdots,u_p)_{p \times p}
U=(u1,u2,⋯,up)p×p 某样本点
x
x
x到对应分布的马氏距离
Δ
\Delta
Δ表示如下: 需要补充的点:
k
i
k_i
ki并不是正交基,而是
x
x
x坐标轴的元素
x
−
μ
x - \mu
x−μ在
u
u
u正交基上的投影坐标,是一个实数。
k
i
=
(
x
−
μ
)
T
⋅
u
i
k_i = (x - \mu)^T \cdot u_i
ki=(x−μ)T⋅ui
Δ
=
(
x
−
μ
)
T
Σ
−
1
(
x
−
μ
)
=
(
x
−
μ
)
T
∑
i
=
1
p
1
λ
i
u
i
u
i
T
(
x
−
μ
)
=
∑
i
=
1
p
1
λ
i
[
(
x
−
μ
)
T
⋅
u
i
]
⋅
[
(
x
−
μ
)
T
⋅
u
i
]
T
=
∑
i
=
1
p
1
λ
i
k
i
k
i
T
=
∑
i
=
1
p
k
i
2
λ
i
(
i
=
1
,
2
,
⋯
,
p
)
\begin{aligned} \Delta & = (x - \mu)^{T} \Sigma^{-1}(x - \mu) \\ & = (x - \mu)^{T} \sum_{i=1}^p \frac{1}{\lambda_i}u_iu_i^{T}(x - \mu) \\ & = \sum_{i=1}^p \frac{1}{\lambda_i} \left[(x - \mu)^T \cdot u_i\right] \cdot \left[(x - \mu)^T \cdot u_i\right]^T\\ & = \sum_{i=1}^p \frac{1}{\lambda_i}k_ik_i^{T} \\ & = \sum_{i=1}^p \frac{k_i^2}{\lambda_i}(i=1,2,\cdots,p) \end{aligned}
Δ=(x−μ)TΣ−1(x−μ)=(x−μ)Ti=1∑pλi1uiuiT(x−μ)=i=1∑pλi1[(x−μ)T⋅ui]⋅[(x−μ)T⋅ui]T=i=1∑pλi1kikiT=i=1∑pλiki2(i=1,2,⋯,p) 因此,马氏距离在正交基
U
=
(
u
1
,
u
2
,
⋯
,
u
p
)
\mathcal U = (u_1,u_2,\cdots,u_p)
U=(u1,u2,⋯,up)中的呈现的函数是一个标准椭圆形状。但是该椭圆仅在
U
\mathcal U
U正交基下是标准的,但在
x
x
x坐标轴中可能存在偏移: 这里图形均以二维坐标为例,下同。 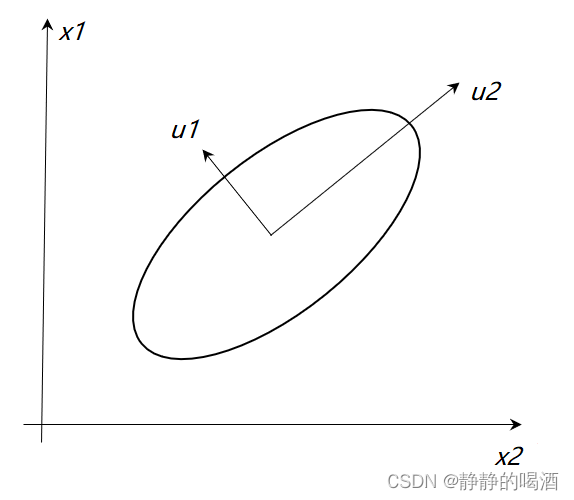
- 计算协方差矩阵参数的时间复杂度过高。 协方差矩阵是一个
p
×
p
p \times p
p×p的实对称矩阵,因此需要求解的元素包含上/下三角阵 + 对角阵的参数。具体参数数量
δ
\delta
δ以及对应的时间复杂度为:
δ
=
p
(
p
+
1
)
2
→
O
(
p
2
)
\delta = \frac{p(p+1)}{2} \to O(p^2)
δ=2p(p+1)→O(p2) 为了减小时间复杂度,尝试对求解过程进行简化。
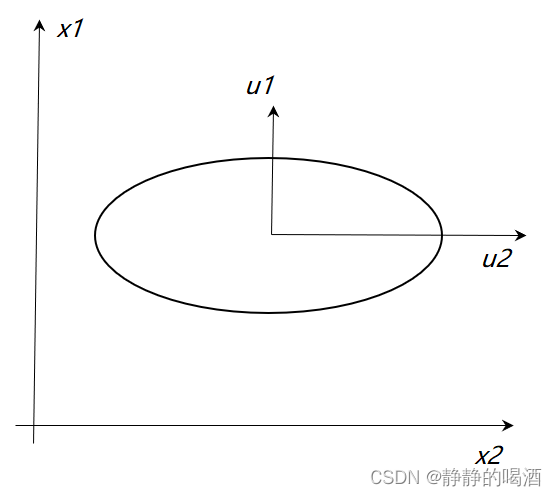
- 假设协方差矩阵是对角矩阵。即:
Σ
=
U
Λ
U
T
→
Λ
\Sigma = \mathcal U \Lambda \mathcal U^T \to \Lambda
Σ=UΛUT→Λ 这意味着
U
\mathcal U
U不仅仅是单纯的正交矩阵,并且是单位矩阵,矩阵内各向量均是两两相互正交的单位向量:
U
=
U
T
=
E
\mathcal U = \mathcal U^T = \mathcal E
U=UT=E 这使得正交基
u
i
u_i
ui和坐标轴
x
i
x_i
xi方向相同,此时仅需要计算 对角线上的
p
p
p个特征值即可。
Δ
=
∑
i
=
1
p
1
λ
i
u
i
u
i
T
\Delta = \sum_{i=1}^p \frac{1}{\lambda_i} u_iu_i^T
Δ=i=1∑pλi1uiuiT 协方差矩阵是对角阵对应在图中的表示如下:
- 在上述假设的基础上,假设表示协方差矩阵
Σ
\Sigma
Σ的对角阵中各元素均相同。即:
λ
1
,
=
λ
2
=
⋯
=
λ
p
=
λ
\lambda_1, = \lambda_2 = \cdots = \lambda_p = \lambda
λ1,=λ2=⋯=λp=λ 此时的马氏距离变化为:
由于λ \lambda λ均相同,使得原始的超椭圆体的判别式变成一个超球体的判别式。Δ = ∑ i = 1 p u i u i T λ \Delta = \frac{\sum_{i=1}^p u_i u_i^T}{\lambda} Δ=λ∑i=1puiuiT 协方差矩阵是对角线元素相同的对角阵对应图像表示如下: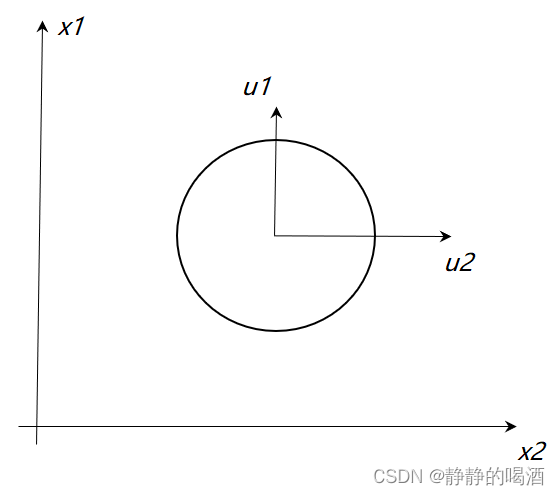 此时的协方差矩阵仅需要计算一个特征值即可,大大简化了运算。将这种情况称为各向同性(isotropic)。具体的延伸方法有因子分析(Factor Analysis),概率性主成分分析(Probabilisitc PCA)等。
此时的协方差矩阵仅需要计算一个特征值即可,大大简化了运算。将这种情况称为各向同性(isotropic)。具体的延伸方法有因子分析(Factor Analysis),概率性主成分分析(Probabilisitc PCA)等。
- 假设协方差矩阵是对角矩阵。即:
Σ
=
U
Λ
U
T
→
Λ
\Sigma = \mathcal U \Lambda \mathcal U^T \to \Lambda
Σ=UΛUT→Λ 这意味着
U
\mathcal U
U不仅仅是单纯的正交矩阵,并且是单位矩阵,矩阵内各向量均是两两相互正交的单位向量:
U
=
U
T
=
E
\mathcal U = \mathcal U^T = \mathcal E
U=UT=E 这使得正交基
u
i
u_i
ui和坐标轴
x
i
x_i
xi方向相同,此时仅需要计算 对角线上的
p
p
p个特征值即可。
Δ
=
∑
i
=
1
p
1
λ
i
u
i
u
i
T
\Delta = \sum_{i=1}^p \frac{1}{\lambda_i} u_iu_i^T
Δ=i=1∑pλi1uiuiT 协方差矩阵是对角阵对应在图中的表示如下:
- 高斯分布自身的局限性——虽然高斯分布涉及范围很广泛,但是一些情况使用高斯分布建立概率模型 显得不足。最明显的如高斯混合模型的概率分布,其分布明显一个高斯分布无法进行表示。详见高斯混合模型——模型介绍。
- 矩阵乘法——将当前变量的坐标系映射到其他坐标系中;
在后续的线性判别分析中加深印象; - 将 x x x参考系被映射到新的参考系中,并将马氏距离映射为标准的超椭圆方程。
相关参考: 机器学习-数学基础-概率-高斯分布3-从概率密度角度观察 机器学习-数学基础-概率-高斯分布4-局限性

