
目录
基本情况
摘要
1 介绍
2 相关工作
深度估计:
语义分割:
多任务学习:
3 方法
3.1 动机
3.2 网络架构
Task-attentional module
Upsampling blocks
3.3 训练损失函数
4 试验
4.1 Experimental Settings
4.2 Ablation Study
4.3 Comparisons with the state-of-the-art methods
5 总结
参考
基本情况- 题目:Joint Task-Recursive Learning for Semantic Segmentation and Depth Estimation
- 作者:Zhenyu Zhang1, Zhen Cui1⋆, Chunyan Xu1, Zequn Jie2, Xiang Li1, Jian Yang1
- 1 Nanjing University of Science and Technology, 2 Tencent AI Lab
- 出处:2018-ECCV
johncomment: 不能只是翻译,要挑剔的眼光?启发的眼光?发现问题?寻找解决方法?不断试错?
摘要在本文中,我们提出了一种新颖的联合任务递归学习(TRL)框架(joint Task-Recursive Learning framework),用于闭环语义分割和单眼深度估计任务。 TRL可以通过序列化的任务级交互来递归地优化两个任务的结果。 为了相互促进,我们将交互封装到特定的任务注意模块(TAM)中,以自适应地增强这两个任务的某些对应模式。 此外,为了使推论更可信,我们通过明确地串联先前的响应,将先前在两个任务上的学习经验传播到下一个网络演化中。 任务级交互的序列最终沿粗到精的尺度空间演化,从而可以逐步重建所需的细节。 在NYU-Depth v2和SUN RGBD数据集上进行的大量实验表明,我们的方法获得了用于单眼深度估计和语义分割的最佳结果。
关键字:深度估计,语义分割,递归学习,递归神经网络,深度学习
1 介绍由于缺乏可靠的场景线索,场景类型的大变化,背景杂乱,姿势变化和物体遮挡,从单眼图像中进行语义分割和深度估计是计算机视觉中的两个挑战性任务。近年来,在深度学习技术的推动下,对它们的研究取得了长足的进步,并开始使一些潜在的应用受益,例如场景理解[1],机器人技术[2],自动驾驶[3]和同时定位与地图绘制(SLAM)系统[4]。尽管深度学习(尤其是CNN)在单眼深度估计[5] [6] [7] [8] [9]和语义分割[10] [11] [12] [13]方面取得了成功,但大多数方法都强调要学习鲁棒的回归,却几乎不考虑它们之间的相互作用。实际上,这两个任务具有一些共同的特征,可以相互利用。例如,场景的语义分割和深度都可以揭示布局和对象形状/边界。文献[14]中的最新工作还表明,利用RGBD数据中的深度信息可以促进语义分割。因此,应该考虑共同学习这两个任务,以相互促进。
现有的两个任务的联合学习属于多任务学习的范畴,在过去的几十年中,它已经得到了广泛的研究[15]。它涉及许多交叉任务,例如检测和分类[16] [17],深度估计和图像分解(image decomposition)[18],图像分割和分类[19],以及深度估计和语义分割[20] [21] [22] ],等等。但是这种现有的联合学习方法主要属于浅层任务级交互。例如,利用共享的深度网络提取两个任务的共同特征,并从高层分叉以分别执行两个任务[16] [17] [22] [19] [21] [18] 。这样,在这些方法中,由于任务之间的相对独立性,因此交互较少。然而,众所周知,人类学习系统受益于不同任务之间的迭代/循环交互过程[23]。在最简单的常识性案例中,交替进行读写可以迅速提高这两个方面的人员能力。因此,我们在考虑随着深度学习的突破,任务替代学习(例如交叉分割和深度估计)是否可以进一步深入。
为了解决这个问题,在本文中,我们提出了一种新颖的联合TaskRecursive学习(TRL)框架,以对室内场景的语义分割和深度估计进行紧密循环。如图1所示,两个任务之间的交互被序列化为一个新创建的时间轴。沿着时间维度,两个任务{D,S}相互协作以相互提升性能。在每次互动中,将有选择地传播先前状态的历史经验(即,两项任务的先前时间步长的特征),并有助于估计新状态,如弧形和水平黑色箭头所示。为了正确传播信息流,我们设计了用于语义分割和深度估计的Task-TRL 3 关联两个任务注意模块(TAM),在抑制任务无关信息的同时,将增强与当前任务相关的有用公共信息。因此,在本文中,可以轻松地将两个任务的学习过程模块化为一个序列网络,称为任务递归学习网络。此外,考虑到高分辨率像素级预测的困难,我们在一系列从粗到精的尺度上推导了递归任务学习,这将逐步完善估计结果的细节。大量的实验表明,我们提出的任务递归学习可以使两个任务彼此受益。总而言之,本文的贡献包括三个方面:
- –提出一种新颖的联合任务递归学习(TRL)框架,用于语义分割和深度估计。通过将问题序列化为任务交替的时间序列,TRL可以通过正确传播信息流来逐步完善和相互促进这两个任务。
- –设计任务注意模块(TAM)来封装两个任务的交互,因此可以在那些常规网络中用作通用层或模块。
- –验证深层任务替代机制的有效性,并在NYU Depth V2和SUN RGBD数据集上实现深度估计和语义分割双重任务的一些最新技术成果。

Fig1. 我们的主要思想的插图。 逐步完善这两个任务(即深度估计和语义分段)以形成任务交替状态序列。 在时间片t处,我们分别将任务状态表示为Dt和St。 先前的任务相关经验和其他任务的信息通过称为任务注意模块(TAM)的设计的任务交互模块自适应地传播到下一个新状态(Dt)。 最后,将双重任务的演化-替代过程框架化为建议的任务递归学习。
2 相关工作 深度估计:已经提出了许多用于单眼深度估计的工作。
- Eigen等 [5,24]提出了一种多级CNN来解决单眼深度预测。
- 刘等[25]和李等 [26]利用CRF模型?来捕获局部图像纹理并指导网络学习过程。
- 最近,Laina等 [7]提出了一种具有向上投影(up-projection)?的全卷积网络,以实现有效的向上采样过程。
- 徐等[6]采用多尺度连续CRF?作为深度顺序网络。
与这些方法相比,我们的方法侧重于双任务学习,并尝试利用分段提示来促进深度预测。
语义分割:大多数方法[10,11,27–29]从单个RGB图像进行语义分割。随着大型RGBD数据集的发布,一些方法[30,31]尝试融合深度信息以获得更好的分割效果。
- 最近,Cheng等 [32]从RGB图像和HHA深度图像计算了关联矩阵?(the affinity matrices),以便更好地对重要位置进行上采样。
与这些基于RGBD的方法不同,我们的方法不直接使用含有深度的ground truth,而是用于语义分割的估计深度,因此本质上属于RGB图像分割的范畴。
多任务学习:长期以来研究了通用的多任务学习问题[15],并且在不同的研究领域开发了许多方法,
- 例如表示学习[33-35],
- 转移学习[36、37],
- 计算机视觉[38、16、19、39、17、40]。
这里最相关的工作是计算机视觉的那些多任务学习方法。
- 例如,文献[21,22]将带有分层CRF的CNN和多解码器结合?使用以获得深度估计和语义分割。
- 在文献[19]中,提出了一个十字绣单元(cross-stitch unit)?,以更好地交互两个任务。
- 最近提出的Ubernet [40]试图为内存有限的各种数据集上的各种任务提供解决方案。
与这些以前的工作不同,我们提出的TRL将多任务学习作为任务交互的一种深层方式。具体而言,在一般的递归体系结构中,深度估计和语义分割是相互促进和完善的。
3 方法 3.1 动机在这里,我们关注两个任务的交互式学习问题,包括深度估计和从单眼RGB图像进行语义分割。 我们的动机主要来自两个方面:
- i)人类学习受益于任务之间的迭代/循环交互过程[23];
- ii)除了共享一些公共信息外,这两项任务在一定程度上是互补的。
因此,我们的目的是使任务级交替交互更深入,从而使两个任务相互促进。 主要思想如图1所示。我们将任务替代学习过程定义为沿时间轴的一系列状态转换。
形式上,我们将深度估计和语义分割任务的状态,在第p个step时,分别表示为Dp和Sp,并将相应的响应表示为![]() 和
和![]() 。假设前一步获取的经验是
。假设前一步获取的经验是![]() 和
和![]() ,然后在时间片段p时,我们构建了双任务学习为:
,然后在时间片段p时,我们构建了双任务学习为:
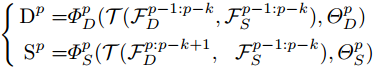
其中![]() 是交互函数(在下面设计为任务注意模块),
是交互函数(在下面设计为任务注意模块),![]() 和
和![]() 是变换函数,用于预测要学习的参数
是变换函数,用于预测要学习的参数![]() 和
和![]() 的下一状态。 作为时间片p,深度估计Dp是在先前的k阶经验
的下一状态。 作为时间片p,深度估计Dp是在先前的k阶经验![]() 和
和![]() 的条件下的,并且分割Sp取决于
的条件下的,并且分割Sp取决于![]() 和
和![]() 。 这样,将通过使用TAM沿时间顺序传播两个任务的历史经验。 这意味着,双任务交互将沿着状态序列更深入。 通常,该框架可以适用于其他双任务应用程序,甚至适用于多任务学习。 我们在补充材料中给出了多任务学习的公式。 在本文中,我们只需在等式中设置k = 1(在公式1中),即短期依赖。
。 这样,将通过使用TAM沿时间顺序传播两个任务的历史经验。 这意味着,双任务交互将沿着状态序列更深入。 通常,该框架可以适用于其他双任务应用程序,甚至适用于多任务学习。 我们在补充材料中给出了多任务学习的公式。 在本文中,我们只需在等式中设置k = 1(在公式1中),即短期依赖。
概述整个网络架构如图2所示。我们使用复杂的ResNet [41]对输入图像进行编码。从Res-2到Res-5的灰色立方体是从ResNet提取的多尺度响应图。下一个解码过程旨在基于任务递归思想解决双重任务。解码器由上采样块(upsampling blocks, and ),任务注意模块(task attentional modules)和残差块(residual-blocks)组成。
- 上采样块将卷积特征提升到像素级预测所需的尺度。详细的体系结构将在以下小节中介绍。
- 对于像素级预测,我们引入残差块(蓝色立方体)来解码先前的特征,这些特征是编码器中对应特征的镜像类型,但每个残差块中只有两个瓶颈。 Res-d1,Res-d3,Res-d5和Res-d7专注于深度估计,其余的专注于语义分割。
- TAM旨在执行两个任务的交互。在交互过程中,将有选择地增强先前的信息以适应当前任务。例如,Res-d5之前的TAM从两个来源接收输入:一个是使用细分信息从Res-d4上采样的特征,另一个是使用深度信息从Res-d3上采样的特征。在交互过程中,将有选择地增强两个输入的信息,以传播到下一个任务。
随着交互时间的增加,两个任务的结果将以相互促进的方案逐步完善。
- 另一个导入策略是采用从粗到细的过程来逐步重建细节,并产生高分辨率的细粒度预测。
- 具体来说,我们将编码器的不同比例尺特征连接到相应的残差块,如绿色箭头所示。
后续小节将介绍升采样模块和任务注意模块。

Fig.2. 我们的任务递归学习(TRL)网络的概述。 TRL网络是一种编码器-解码器体系结构,由一系列残差块,上采样块和任务注意模块组成。 首先将输入的RGB图像输入到ResNet中以对多级特征进行编码,然后将这些特征输入到任务递归解码过程中以估计深度和语义分割。在解码器中,通过自适应演化两项任务的先前经验,来交替处理这两个任务 (即深度和分割的先前特征),以便在学习过程中互相促进和受益。 为了估计当前任务状态,将两个任务的先前功能馈入TAM中以增强公共信息。 为了更好地细化预测的细节,我们在从粗到精的比例空间中逐步执行这两个任务。

如第1节所述,场景的语义分割和深度估计结果具有许多常见的模式,例如,它们都可以揭示对象的边缘,边界或布局 (dges, boundaries or layouts)。 为了更好地挖掘和利用公共信息,我们设计了一个任务关注模块,来增强两个任务的相关信息。 如图2所示,TAM在每个残差块(residual block)之前使用,并采用先前残差块的深度/分割特征作为输入。 设计的TAM如图3(a)所示。 首先将输入深度/分割特征输入到平衡单元(Balance Unit)中,以平衡两个源的特征的贡献。 如果我们分别使用![]() 和
和![]() 表示接收到的深度和分割特征,则平衡单位可以表示为:
表示接收到的深度和分割特征,则平衡单位可以表示为:
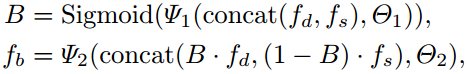
其中Ψ1和Ψ2是分别具有参数Θ1和Θ2的两个卷积层。 ![]() 是学习的平衡张量,
是学习的平衡张量,![]() 是平衡单元的平衡输出。 这样,fb组合了来自两个来源的平衡信息。 接下来,平衡的输出将被馈送到一系列的反卷积层中,如图3(a)中的黄色矩形块所示。 这种机制被设计为通过使用感受野变化来获得不同的空间注意力,如[42]?所证明的剩余注意力(residual attention)。 经过Sigmoid变换后,我们得到一个注意力图
是平衡单元的平衡输出。 这样,fb组合了来自两个来源的平衡信息。 接下来,平衡的输出将被馈送到一系列的反卷积层中,如图3(a)中的黄色矩形块所示。 这种机制被设计为通过使用感受野变化来获得不同的空间注意力,如[42]?所证明的剩余注意力(residual attention)。 经过Sigmoid变换后,我们得到一个注意力图![]() ,该图有望对常见模式有更高的响应。 最后,注意张量M用于正式生成门控深度/分段特征,正式地:
,该图有望对常见模式有更高的响应。 最后,注意张量M用于正式生成门控深度/分段特征,正式地:
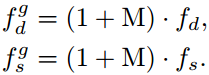
因此,可以通过学习到的注意力图M来增强特征fd和fs。门控特征![]() 和
和![]() 通过级联和随后的一个卷积层进一步融合。 TAM的输出表示为
通过级联和随后的一个卷积层进一步融合。 TAM的输出表示为![]() 。 任务注意模块可以使我们的任务递归学习方法受益,如第4.2节所述。
。 任务注意模块可以使我们的任务递归学习方法受益,如第4.2节所述。
上采样块旨在与任务递归学习期间的比例变化匹配。 上采样模块的架构如图3(b)所示。 首先将尺寸为H×W×C的特征馈入具有不同接收场的四个平行卷积层中(即图3中的conv-1至conv-4)。 这四个卷积层旨在捕获不同的局部结构。 然后,将四个卷积层产生的响应连接到一个尺寸为H×W×2C的张量特征上。 最后,[43]中的子像素操作?被应用于空间上的特征放大。 形式上,给定张量特征T和坐标[h,w,c],子像素算子可以定义为:
![]()
其中r是比例因子(scale factor)。 经过这样的亚像素运算(sub-pixel operation)后,当我们将r设置为2时,一个上采样块的输出就是2H×2W×C / 2的特征。上采样块比一般的反卷积更有效,如在第4.2节证实的那样。
3.3 训练损失函数我们在每个尺度上施加监督损失约束(supervised loss constraint)以获得多尺度预测。 对于深度估计,我们使用[7]中定义的逆Huber损耗作为损耗函数,可以表示为:
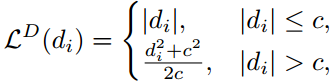
其中di是每个像素i的预测和地面真相之间的差,而c是默认值为![]() 的阈值。 这种损失函数可以在深度差较低的位置提供更明显的梯度,从而有助于更好地训练网络。 用于语义分割的损失函数是交叉熵损失,表示为
的阈值。 这种损失函数可以在深度差较低的位置提供更明显的梯度,从而有助于更好地训练网络。 用于语义分割的损失函数是交叉熵损失,表示为![]() 。 为了更好地优化我们提出的双任务网络,我们使用[22]中提出的策略?来平衡两个任务。 假设网络预测深度图和语义分割图的N个pair对(关于 N scales),则总损失函数可以定义为:
。 为了更好地优化我们提出的双任务网络,我们使用[22]中提出的策略?来平衡两个任务。 假设网络预测深度图和语义分割图的N个pair对(关于 N scales),则总损失函数可以定义为:
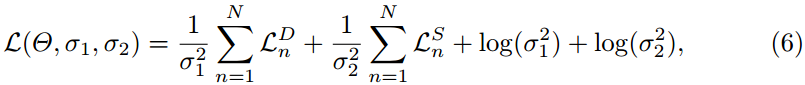
其中Θ是网络的参数,σ1和σ2是这两个任务的平衡权重。 请注意,在训练过程中,平衡权重作为参数也被优化。 实际上,为了避免潜在的被零除,我们重新定义了![]() 。 因此,总损失可以改写为:
。 因此,总损失可以改写为:
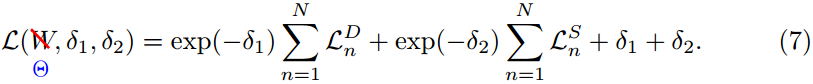


本文提出了一种新颖的端到端任务递归学习框架,用于从一个RGB图像联合预测深度图和语义分割。 任务递归学习网络将两个任务作为时间状态的递归序列交替进行细化。 为了更好地利用深度和语义细分的相关和通用模式,我们还设计了一个任务注意模块。 该模块可以自适应地挖掘两个任务的共同信息,鼓励双方进行交互式学习,并最终彼此受益。 全面的基准评估证明了我们的任务递归网络在联合处理深度估计和语义分割方面的优越性。 同时,我们还报告了有关NYU-Depth v2和SUN RGB-D数据集的一些最新结果。 将来,我们会将框架推广到更多任务的联合学习中。
参考14. Wang, J., Wang, Z., Tao, D., See, S., Wang, G.: Learning common and specific features for rgb-d semantic segmentation with deconvolutional networks. In: ECCV. (2016) 664–679

