
目录
1 利用多尺度深度网络,从单一图像预测深度图
2 使用常用的多尺度卷积结构,预测深度、表面法线和语义标签
3 从单一的RGB图像,学习细尺度的深度地图
4 利用深度卷积网络,联合语义分割和深度估计
5 利用全卷积残差网络,进行深度预测
6 基于左右一致性的无监督单目深度估计
7 半监督深度学习的单眼深度图预测
8 采用多尺度连续CRFs,作为单目深度估计的连续深度网络
9 分类说明
9.1 第一类 仅仅依靠深度学习和网络架构得到结果
9.2 第二类 依靠于深度信息本身的性质
9.3 第三类 基于CRF的方法
9.4 第四类 基于相对深度
9.5 第五类 非监督学习
9.6 总结
作者:buldajs
- 链接:https://www.zhihu.com/question/53354718/answer/207687177
- 来源:知乎
Depth Map Prediction from a Single Image using a Multi-Scale Deep Network
NIPS2014,第一篇CNN-based来做单目深度估计的文章。
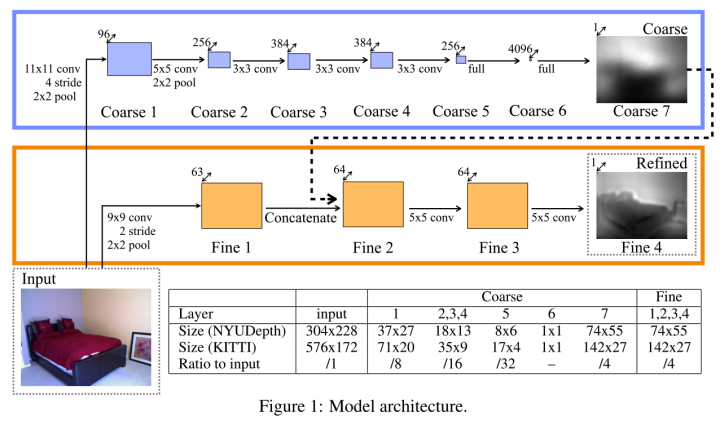
基本思想用的是一个Multi-scale的网络,这里的Multi-scale不是现在网络中Multi-scale features的做法,而是分为两个scale的网络来做DepthMap的估计,分别是Global Coarse-Scale Network和Local Fine-Scale Network。前者其实就是AlexNet,来得到一个低分辨率的Coarse的Depth Map,再用后者去refine前者的输出得到最后的refined depth map.
代码:hjimce/Depth-Map-Prediction
2 使用常用的多尺度卷积结构,预测深度、表面法线和语义标签
Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture
ICCV2015,也是上一篇作者David Eigen发的,号称是multi-task的一个network.
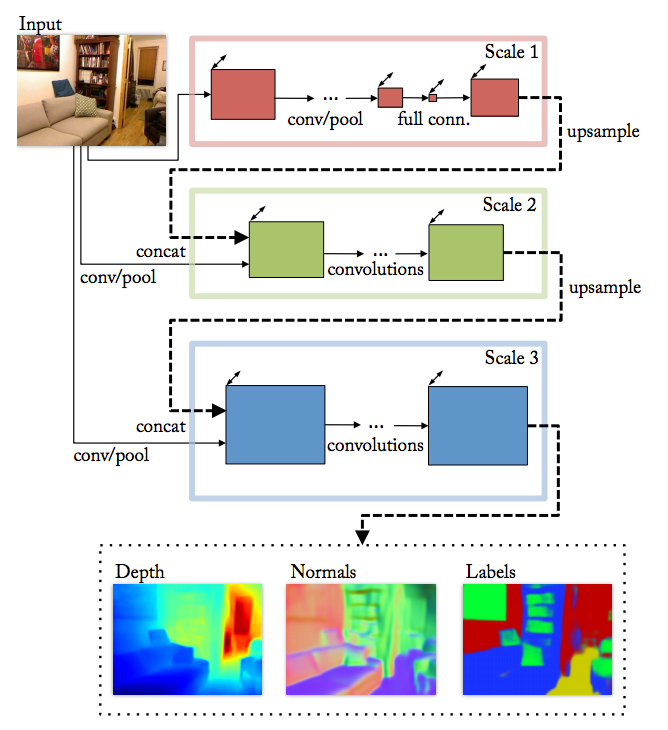
网络结构上做了一些改进,从两个scale增加到了三个scale,scale1考虑了用VGG替换AlexNet,这篇没细看,有错请指出~
3 从单一的RGB图像,学习细尺度的深度地图
Learning Fine-Scaled Depth Maps from Single RGB Images
挂在Arxiv1607上的,在上一篇的基础上做了一些改进。
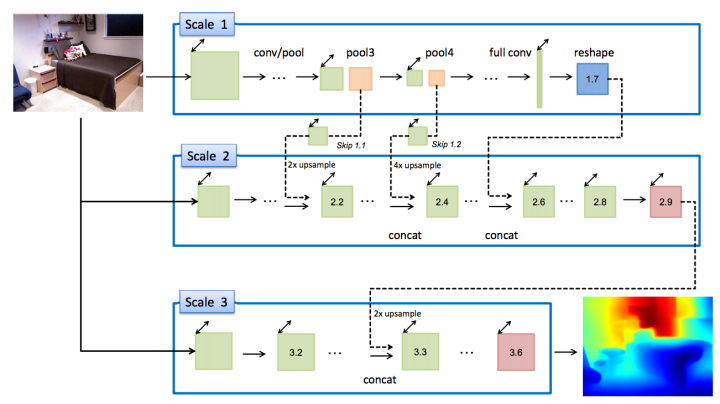
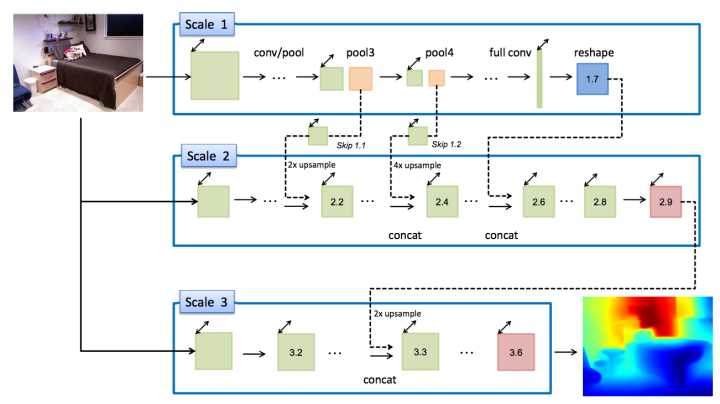
主要的contributions:
1.在ICCV2015的基础上加入了multi-scale之间的skip connections,号称可以加速网络的收敛。
2.考虑了在做Data Augmentation的时候,相同的数据生成的train data之间的相关性,其恢复得到的深度要尽可能接近,因此构建了基于set of transformed images的loss的约束。
4 利用深度卷积网络,联合语义分割和深度估计Joint Semantic Segmentation and Depth Estimation with Deep Convolutional Networks
Arxiv1604,分割和单目深度估计Joint的文章。。。然而。
5 利用全卷积残差网络,进行深度预测Deeper Depth Prediction with Fully Convolutional Residual Networks
IEEE 3D Vision 2016的文章,用ResNet的结构来做了。
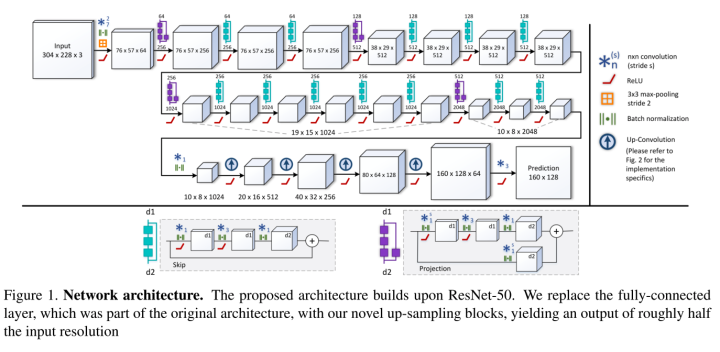
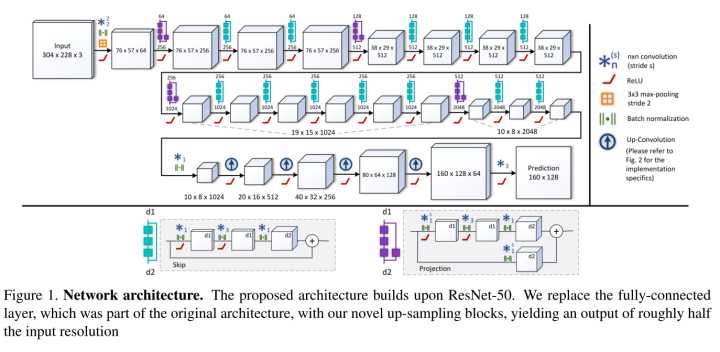
Deconv部分提出了几个版本,如下图.
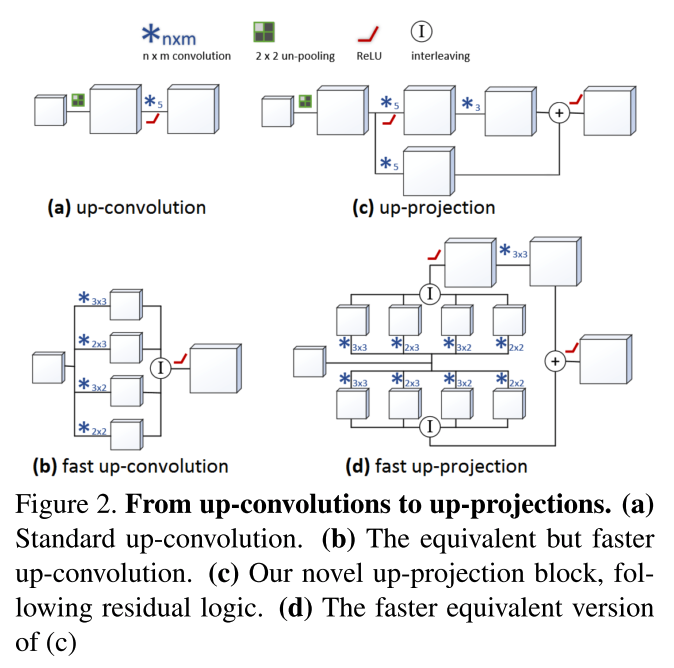
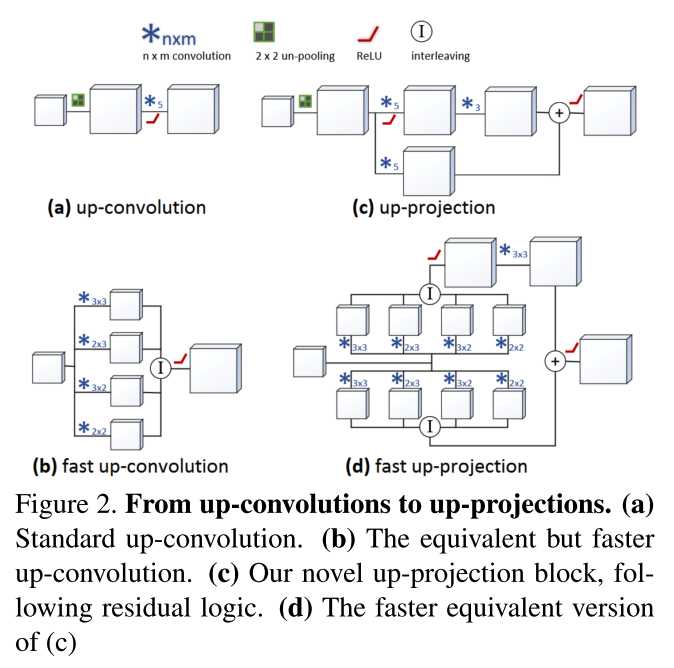
1. up-convolution:基本的unpooling+convolution
2. up-projection: 引入了残差的up-convolution单元
3. 两者的fast版本,基本思想就是unpooling+5*5的conv可以用4个更小的conv来实现,从而加速,如下图
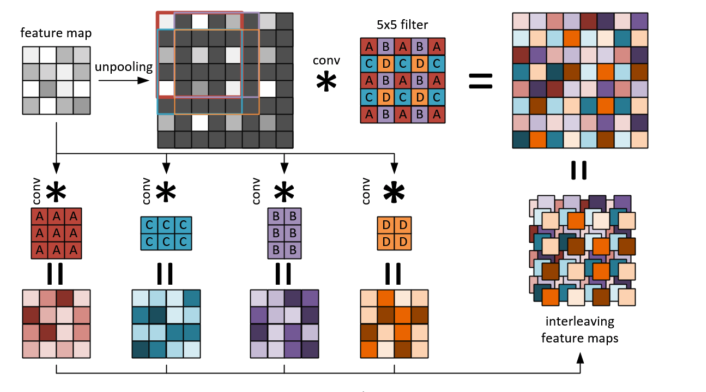
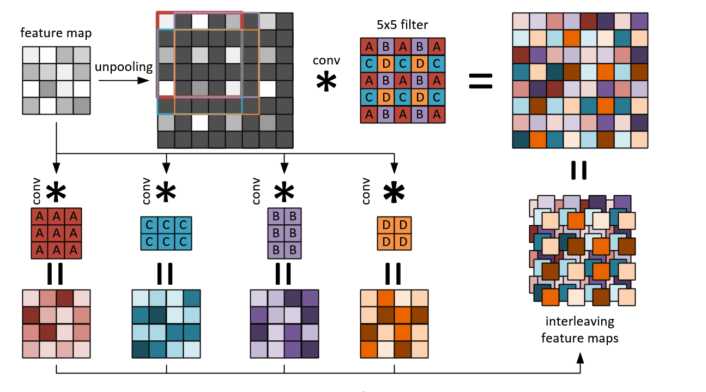
代码:FCRN-DepthPrediction,基于tensorflow的。
CVPR2017也有3篇。
6 基于左右一致性的无监督单目深度估计
Unsupervised Monocular Depth Estimation With Left-Right Consistency
这篇没细看,思想应该是loss不是直接用的depth的loss.
而是用估计出来的depthmap来做左右图的匹配,利用匹配后rgb图像的强度的偏差来构建loss,所以说是unsupervised.
代码:mrharicot-monodepth 也是基于tensorflow的。
7 半监督深度学习的单眼深度图预测Semi-Supervised Deep Learning for Monocular Depth Map Prediction
这篇是semi-supervised,网络结构基本用的是上面的FCRN,主要在loss上做了手脚。
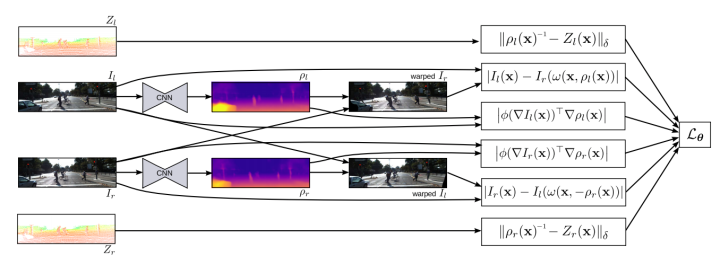
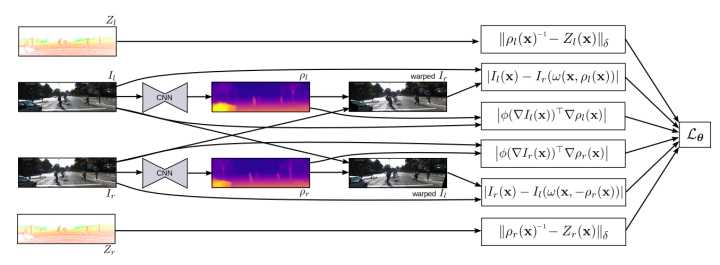
loss一共分为Supervised loss,Unsupervised loss,Regularization loss
1.Unsupervised loss
和上一篇unsupervised的一样,用的也是网络inference得到depthmap后做左右rgb图像匹配构建的loss.
2.Supervised loss
同时因为用的是kitti的数据,有雷达图像数据配准后的sparse的深度值图,将这些sparse的depth values作为seed点,也引入了loss中。
3.Regularization loss
还添加了gradient的Regularization loss作为约束。
所以个人感觉是,这篇文章是上两篇文章的结合。
8 采用多尺度连续CRFs,作为单目深度估计的连续深度网络
Multi-Scale Continuous CRFs as Sequential Deep Networks for Monocular Depth Estimation
xiaogang wang他们的成果,这篇主要是CNN和Graphical Model的结合。
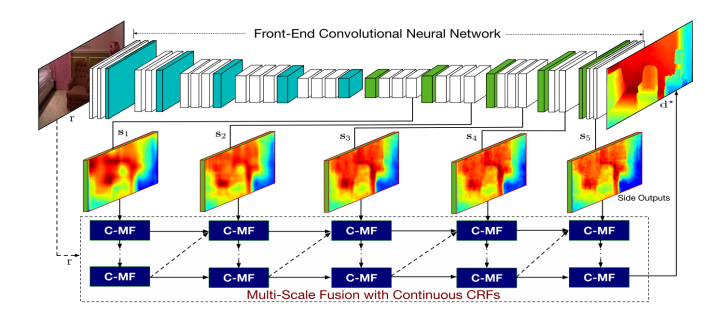
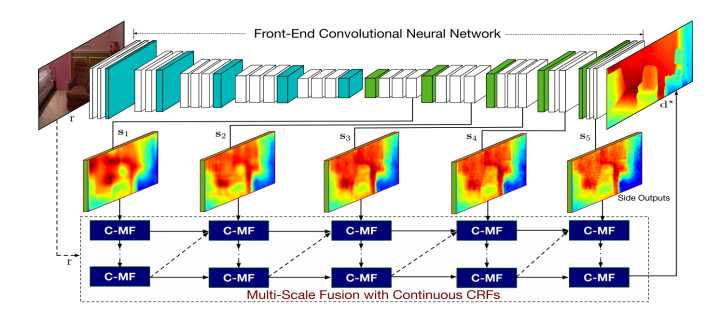
主要的motivation:
1.在CNN解决pixel级的classification/regression问题时,引入multi-scale的信息可以更好的结合low-level和high-level的feature。
2.在semantic segmentation问题中,CRFasRNN中将CRF的mean-field解法展开用RNN网络的结构实现,使得CNN+CRF可以进行end-to-end的优化,这是针对discrete domain的问题,而对于continuous domain的regression问题,还没有这样翻译成网络的CRF层的存在。
3.以及图模型有很好的表达能力,可以与CNN模型的特征表达结合,得到更好的效果。
因此作者提出了Multi-scale CRFs和Cascade CRFs两个模块。
具体推导不展开,有兴趣的可以看论文,两个CRFs的最小单元可以用一个C-MF block来实现。
代码:danxuhk/ContinuousCRF-CNN 基于caffe框架。
9 分类说明作者:知乎用户 链接:https://www.zhihu.com/question/53354718/answer/209398048 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
其实楼上写的蛮具体的了, 我再补充一下把。
我觉得近几年采用深度学习来解决深度估计的思路可以分为好几类:
9.1 第一类 仅仅依靠深度学习和网络架构得到结果最近这部分文章我较为详细的总结在了专栏里:深度学习之单目深度估计 (Chapter.1):基础篇
1. 引用最多、最早的是Eigen组的两篇文章,相对于简单粗暴的使用卷积神经网络回归来得到结果,主要卖点是采用Multi-scale的卷积网络结构(2015年):
- Predicting Depth, Surface Normals and Semantic Labels with a Common Multi-Scale Convolutional Architecture
- Depth Map Prediction from a Single Image using a Multi-Scale Deep Network
2. 之后在2016年,Laina依靠更深层次的网络和一个“novel”的逆卷积结构再加上一个"novel"的loss来得到结果。其实我认为这篇文章的贡献点不是很大,主要是pretrain的ResNet-50帮了很大的忙。这个方法被他们组改进然后用到了之后CVPR2017用来重建SLAM的文章中。
- Deeper Depth Prediction with Fully Convolutional Residual Networks (3DV 2016)
- CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction(2017 CVPR)
1. 深度信息和语义分割信息具有很强的相关性:场景中语义分割信息相似的物体所拥有的深度信息是相似的。
- Towards Unified Depth and Semantic Prediction From a Single Image (CVPR 2015)
2. 之后接下来又有文章试图去做了语义分割和深度信息的升级版:除了语义分割信息有没有其他信息和深度信息也相似的?
SURGE: Surface Regularized Geometry Estimation from a Single Image(NIPS 2016)
3. 深度信息本就是一个从远到近一层一层的分类,是不是把预测深度当做一个分类问题更好解一点,搜文章的时候搜到了这两篇用到了这个思路:
Estimating Depth from Monocular Images as Classification Using Deep Fully Convolutional Residual Networks
Single image depth estimation by dilated deep residual convolutional neural network and soft-weight-sum inference
9.3 第三类 基于CRF的方法
CRF之前一直在语义分割问题上表现的很好,包括CRFasRNN,DeepLab等等,几乎成为了这种回归问题的标配。这一类的方法采用CRF是因为通常CNN用来做回归时产生的图都比较糊(blur), CRF可以通过条件概率建模的方法将糊的图片变得不糊。这是一种纯数学解决问题的方法,与深度信息本身的物理性质关系不大。
Deep Convolutional Neural Fields for Depth Estimation from a Single Image(2015 CVPR)
Depth and surface normal estimation from monocular images using regression on deep features and hierarchical CRFs(2015 CVPR)
Multi-Scale Continuous CRFs as Sequential Deep Networks for Monocular Depth Estimation (2017 CVPR)
9.4 第四类 基于相对深度
接下来介绍的这一类是我觉得最有意思的一个方法。 总的来说就是利用了深度信息的基本特征:图片中的点与点之间的是有相对远近关系的。NIPS2016这篇文章自己构建了一个相对深度的数据库,每张图片之中仅仅标注两个随机点之间的相对远近关系,通过一个神经网络的训练就能得到原图之中的相对深度信息。而且,一般的方法通常是针对某个数据库的数据范围的(NYUv2用来做室内深度预测,深度的ground truth 是 0~10m,KITTI用来处理行车道路信息,深度的ground truth 是 0~70m),这篇文章的深度是没有这种限制的。这篇文章得到的深度信息感觉是很amazing的一件事,为这篇文章打call! 但是缺点也很明显,由于是相对深度信息仅仅得到的数据表示了当前图片中物体的远近关系和真实深度信息有很大的区别。
Single-Image Depth Perception in the Wild (NIPS2016)
当然这种相对关系的想法第一个提出来应该是下面这篇文章。不过我觉得这篇文章生成的图看起来太“超像素”了,不太smooth(因为它训练的时候就是使用的是图片中超像素的中点):
Learning Ordinal Relationships for Mid-Level Vision(2015ICCV)
9.5 第五类 非监督学习
最近这部分文章我较为详细的总结在了专栏里:深度学习之单目深度估计 (Chapter.2):无监督学习篇
所谓使用非监督学习来训练就是利用不知道ground truth的输入图片训练来得到深度信息。既然没有深度的ground truth那肯定有来自于其他地方的约束,比如使用stereo image。stereo image是来自两个相机(或者双目相机)在同一水平线上左右相距一定位置得到的两幅图片。这种图片获取的代价要比深度的ground truth 低一些。 这些方法利用了深度信息和场景之间的一些物理规律来约束,感觉得到了很不错的结果,这三个方法可以说是一脉相承:
Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue(2016 ECCV)
Unsupervised Monocular Depth Estimation with Left-Right Consistency (2017 CVPR)
Semi-Supervised Deep Learning for Monocular Depth Map Prediction (2017 CVPR)
9.6 总结其实感觉同样是image to image 的转换,深度信息相比于语义分割关注的人要少很多,很多语义分割方面的方法就会有可能直接用到深度预测方面。比如Estimating Depth from Monocular Images as Classification Using Deep Fully Convolutional Residual Networks 这篇文章其实就和CRFasRNN很像。
直接利用深度网络来得到深度预测的结果已经不是很novel的方法了,采用基于CRF的方法得到的效果比较好但是和感觉并不是那么让人眼前一亮。
很喜欢基于相对深度和采用非监督学习来得到深度信息的这几种方法。大胆的预测一下,在这种问题上,结合物理规律和深度学习的方法得到更好的结果可能会有更多的文章出来,拭目以待把。
看到有人说Unsupervised Monocular Depth Estimation,但我觉得这个算法训练是个坑,需要双目图像进行训练,而这个监督信号又带了相机参数这个新的约束,如果你用一个相机采集数据进行训练,换一个不同焦距的相机进行测试,获取到的视差实际上就带有scale了。
这个作者也给出了stereo的版本,性能提升是质变。
个人还是比较认可双目无监督估计,[1709.00930] Self-Supervised Learning for Stereo Matching with Self-Improving Ability,这个看看kitti stereo 2015(The KITTI Vision Benchmark Suite)的排名就知道了,和很多有监督的算法比起来也是state-of-art。
如果实在是想用单目做,建议还是看看用视频序列做的吧,(Unsupervised Learning of Depth and Ego-Motion from Video)开源的

