
Redis全称:REmote DIctionary Server(远程字典服务器)。是完全开源免费的。Key-Value数据库,它通常被称为数据结构服务器,并提供多种语言的API。
Redis 官网:https://redis.io/
Redis 中文官网:http://www.redis.cn/
Redis 在线测试:http://try.redis.io/
Redis命令大全:http://www.redis.cn/commands.html
下面涉及的数据类型和更多命令详解,多查看上面官方文档。
一、Redis 数据类型Redis的数据类型的数据形式:key - value,键值对的形式来保存数据的。
key:只有一种数据类型就是字符串。
value:值的数据类型基本有8种:
- 字符串(String)
- 列表(list)
- 散列(hash)
- 无序集合(set)
- 有序集合(sorted sets)
- 基数统计(HyperLogLog) # 2.8.9新增
- 地理地图(GEO) # 3.2新增
- 流(Stream) # 5.0新增
Redis所有的数据结构都以唯一的 key 字符串作为名称,然后通过这个唯一 key 值来获取相应的 value 数据。不同类型的数据结 构的差异就在于 value 的结构不一样。
一些常用和通用命令:
命令描述OBJECT subcommand [arguments [arguments ...]]检查内部的在分配对象。subcommand 为refcount 和 idletime 返回整数,encoding 返回编码类型;DEL key [key ...]删除指定的一批keys,返回值:返回值是被删除的 key 的数量,如果删除中的某些key不存在,则直接忽略。KEYS pattern 查找所有符合给定模式( pattern)的 key 。EXISTS key [key ...]检查给定 key 是否存在。
- 1 如果key存在
- 0 如果key不存在
1、字符串(String)
字符串(String)是 Redis 最简单的数据结构,它的内部表示就是一个字符数组,类似于 Java 的 ArrayList,Redis 自己实现了SDS(简单动态字符串)的抽象类型。它是动态字符串,是可以修改的字符串。
字符串数据是二进制安全的,value 值最大长度是512M。
二进制安全:一个二进制安全功能(函数)是指在一个二进制文件上所执行的不更改文件内容的功能或者操作,其本质上将操作输入作为原始的、无任何特殊格式意义的数据流。
MySql是关系型数据库,不是二进制不安全的,如果编码格式不一致,就可能出现中文乱码。而 Redis 的字符串是二进制安全。Redis 只在客户端上才有编码和解码。保证你存什么东西进去,拿出来的一定是一样的。执行效率高。
Redis内部的字符串编码类型使用了三种编码类型来保存字符串对象的数据,并且会随着保存字符串内容自动变更。
1. int:用于保存64位有符号的整数形式的字符串。
2. embstr:用于保存小于或等于44字节大小的字符串,这个内部类型,有利于提高redis的工作效率。
3 .raw:用于大于44字节大小的字符串的保存。
1)常用 Redis命令
命令描述SET key value设置指定 key 的值。如果 key 存在时会直接覆盖原来的值,并且忽略原始类型。返回值:正常执行返回OK,否则,如果没有设置条件则返回nil。 GET key获取指定key的值。返回值:如果key不存在,返回特殊值nil。如果key的value不是string,就返回错误,因为GET只处理string类型的values。STRLEN key获取指定key值的长度。返回值:如果key不存在返回0;如果key的value不是string,就返回错误。APPEND key value追加value到该key原来值的末尾。如果 key 已存在,并且值为字符串,就把 value 追加到原来值(value)的结尾。 如果 key 不存在,就先创建一个空字符串的key,再执行追加操作。返回值:追加后字符串的长度。SETRANGE key offset value覆盖key对应的string的一部分,从指定的offset处开始,覆盖value的长度。返回值:修改后的字符串长度。GETSET key value设置一个key的value,并返回设置前的旧值。返回值:返回之前的旧值,如果key不存返回nil。
INCR key将 key 中储存的数字值增一。返回值:递增的值。DECR key将 key 中储存的数字值减一。返回值:递减的值。2)实例:
[root@centos7 redis]# ./bin/redis-cli
127.0.0.1:6379> keys *
(empty list or set)
127.0.0.1:6379> set k11 v11
OK
127.0.0.1:6379> get k11
"v11"
127.0.0.1:6379> STRLEN k11
(integer) 3
127.0.0.1:6379> strlen k22
(integer) 0
127.0.0.1:6379> APPEND k11 appendvalue
(integer) 14
127.0.0.1:6379> get k11
"v11appendvalue"
127.0.0.1:6379> SETRANGE k11 3 _3range
(integer) 14
127.0.0.1:6379> get k11
"v11_3rangealue"
127.0.0.1:6379> getset k11 v_getset
"v11_3rangealue"
127.0.0.1:6379> get k11
"v_getset"
127.0.0.1:6379> set knum 10
OK
127.0.0.1:6379> incr knum
(integer) 11
127.0.0.1:6379> decr knum
(integer) 10
127.0.0.1:6379> object encoding k11
"embstr"
127.0.0.1:6379> object encoding knum
"int"
127.0.0.1:6379> del knum
(integer) 12、列表(list)
Redis 列表是简单的字符串列表,按照插入顺序排序。你可以添加一个元素到列表的头部(左边)或者尾部(右边)。但这个列表底层不是数组结构,而是有点双向链表和队列结构的感觉(具体结构实现看官网)。
一个列表最多可以包含 2^32 - 1 个元素 (4294967295, 每个列表超过40亿个元素)。
1)常用 Redis命令:
命令描述LPUSH key value [value ...]向列表头部插入一个或多个值,如果 key不在这会创建一个空列表插入值 LPUSHX key value将值 value 插入到列表 key 的表头, 当且仅当 key 存在并且是一个列表。RPUSH key value [value ...]向列表尾部插入一个或多个值,如果 key不在这会创建一个空列表插入值RPUSHX key value将值 value 插入到列表 key 的表尾, 当且仅当 key 存在并且是一个列表。LRANGE key start stop获取列表指定范围内的元素。start 和 end 偏移量都是基于0的下标,偏移量也可以是负数,表示偏移量是从list尾部开始计数,-1 表示列表的最后一个元素,以此类推。LINSERT key BEFORE|AFTER pivot value在列表的元素前或者后插入元素。把 value 插入存于 key 的列表中在基准值 pivot 的前面或后面。当 key 不存在时,这个list会被看作是空list,任何操作都不会发生。LINDEX key index通过索引获取列表中的元素,标是从0开始索引的,负数索引用于指定从列表尾部开始索引的元素。LPOP key移除并且返回 key 对应的 list 的第一个元素。当 key 不存在时返回 nil。RPOP key移除并返回存于 key 的 list 的最后一个元素。当 key 不存在时返回 nil。LLEN key获取列表长度。如果 key 不存在时就被看作是空list,并且返回长度为 0。 LREM key count value从列表中删除元素。返回值:返回被移除的元素个数。当 key 不存在的时候,返回 0。
count > 0: 从头往尾移除值为 value 的元素。 count < 0: 从尾往头移除值为 value 的元素。 count = 0: 移除所有值为 value 的元素。
LSET key index value通过索引设置列表元素的值RPOPLPUSH source destination移除列表的最后一个元素,并将该元素添加到另一个列表并返回2)实例:
127.0.0.1:6379> lpush klist a b c 1 2 3 d
(integer) 7
127.0.0.1:6379> RPUSH klist2 7 8 9 e f g
(integer) 6
127.0.0.1:6379> lrange klist 0 -1
1) "d"
2) "3"
3) "2"
4) "1"
5) "c"
6) "b"
7) "a"
127.0.0.1:6379> lrange klist2 0 -2
1) "7"
2) "8"
3) "9"
4) "e"
5) "f"
127.0.0.1:6379> linsert klist2 before g "abc"
(integer) 7
127.0.0.1:6379> lrange klist2 0 -1
1) "7"
2) "8"
3) "9"
4) "e"
5) "f"
6) "abc"
7) "g"
127.0.0.1:6379> lindex klist2 1
"8"
127.0.0.1:6379> lpop klist2
"7"
127.0.0.1:6379> rpop klist2
"g"
127.0.0.1:6379> lrange klist2 0 -1
1) "8"
2) "9"
3) "e"
4) "f"
5) "abc"
127.0.0.1:6379> lset klist2 0 e
OK
127.0.0.1:6379> lrange klist2 0 -1
1) "e"
2) "9"
3) "e"
4) "f"
5) "abc"
127.0.0.1:6379> lrem klist2 2 e
(integer) 2
127.0.0.1:6379> lrange klist2 0 -1
1) "9"
2) "f"
3) "abc"
127.0.0.1:6379> rpoplpush klist2 klist3
"abc"
127.0.0.1:6379> rpoplpush klist2 klist3
"f"
127.0.0.1:6379> lrange klist3 0 -1
1) "f"
2) "abc"
127.0.0.1:6379> lrange klist2 0 -1
1) "9"3、散列(hash)
hash是一个键值(key=>value)对集合,是一个string类型的field和value的映射表,hash特别适合用于存储对象。
每个 hash 可以存储 2^32 - 1 键值对(40多亿)。
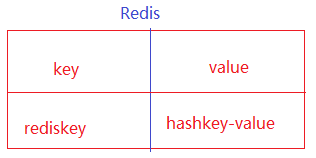
为了区别 redis 和 hash 表中的key,我们把 hash 的 key叫字段field
1)常用 Redis命令:
命令描述HSET key field value设置 key 指定的哈希集中指定字段的值。如果 key 指定的哈希集不存在,会创建一个新的哈希集并与 key 关联。 返回值:1:如果field是一个新的字段 0:如果field原来在map里面已经存在HGET key field获取 hash中field的值,当字段不存在或者 key 不存在时返回nil。HMSET key field value [field value ...]同时将多个 field-value (域-值)对设置到 key 中。如果 key 指定的哈希集不存在,会创建一个新的哈希集并与 key 关联HMGET key field [field ...]获取 key 指定的哈希集中指定字段的值。HGETALL key获取 key 指定的哈希集中所有的字段和值,当 key 指定的哈希集不存在时返回空列表。HDEL key field [field ...]删除一个或多个hash的field字段,返回从哈希集中成功移除的域的数量,不包括指出但不存在的那些域HEXISTS key field判断field是否 存在于hash中,返回值: 1: hash里面包含该field。 0:ash里面不包含该field或者key不存在。HLEN key获取 key 指定的哈希集中所有字段的数量。当 key 指定的哈希集不存在时返回 0HKEYS key获取 key 指定的哈希集中所有字段的名字。当 key 指定的哈希集不存在时返回空列表。HVALS key获取 key 指定的哈希集中所有字段的值。当 key 指定的哈希集不存在时返回空列表。2)实例:
127.0.0.1:6379> hset khash username lisi
(integer) 1
127.0.0.1:6379> hget khash username
"lisi
127.0.0.1:6379> hset khash2 username houzi age 18 sex nan
(integer) 3
127.0.0.1:6379> hmget khash2 username sex age
1) "houzi"
2) "nan"
3) "18"
127.0.0.1:6379> hdel khash2 sex
(integer) 1
127.0.0.1:6379> hgetall khash2
1) "username"
2) "houzi"
3) "age"
4) "18"
127.0.0.1:6379> hexists khash2 sex
(integer) 0
127.0.0.1:6379> hlen khash2
(integer) 2
127.0.0.1:6379> hkeys khash2
1) "username"
2) "age"
127.0.0.1:6379> hvals khash2
1) "houzi"
2) "18"4、无序集合(set)
Redis 的 Set 是 String 类型的无序集合。集合成员是唯一的,这就意味着不允许重复的成员。
Redis 中集合是通过哈希表实现的,集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储40多亿个成员)。
1)常用 Redis命令:
命令描述SADD key member [member ...]添加一个或多个元素到集合的 key中。如果元素在集合key中已经存在,则忽略。返回新成功添加到集合里元素的数量,不包括已经存在于集合中的元素。SMEMBERS key获取key集合所有的元素。SREM key member [member ...]从集合中删除一个或多个元素。如果元素不是key集合中的元素则忽略,如果key集合不存在时则被视为一个空的集合,返回0.返回值:从集合中移除元素的个数,不包括不存在的成员。SCARD key获取集合里面元素的数量,如果key不存在,则返回 0.SRANDMEMBER key [count]从集合里面随机获取一个元素,而不做任何操作。count默认是1 如果count是整数且小于元素的个数,返回含有 count 个不同的元素的数组, 如果count是个整数且大于集合中元素的个数时,仅返回整个集合的所有元素, 当count是负数,则会返回一个包含count的绝对值的个数元素的数组, 如果count的绝对值大于元素的个数,则返回的结果集里会出现一个元素出现多次的情况. 不使用count 参数时,如果key不存在则返回nil。 使用count参数时,如果key不存在则返回一个空的数组。SMOVE source destination member移除集合中的一个元素到另一个集合SPOP key 删除并获取集合中一个随机元素,当key不存在时返回nil。SISMEMBER key member判断元素是否存在集合的key中。 如果元素存在则返回1,如果元素不存在或者集合key不存在,则返回0SUNION key [key ...]求指定集合成员的并集。不存在的key认为是空集。SUNIONSTORE destination key [key ...]将指定集合的并集结果存入到另一个set(若存在, 则将其覆盖重写)中,返回结果集中元素的个数。SINTER key [key ...]求指定集合成员的交集。不存在的key认为是空集.SINTERSTORE destination key [key ...]将指定集合的交集结果存入到另一个set(若存在, 则将其覆盖重写)中,返回结果集中元素的个数。SDIFF key [key ...]求指定集合成员的差集。不存在的key认为是空集.SDIFFSTORE destination key [key ...]将指定集合的差集结果存入到另一个set中(若存在, 则将其覆盖重写),返回结果集中元素的个数。2)实例:
127.0.0.1:6379> sadd kset1 a b 1 2
(integer) 4
127.0.0.1:6379> smembers kset1
1) "1"
2) "b"
3) "a"
4) "2"
127.0.0.1:6379> srem kset1 1
(integer) 1
127.0.0.1:6379> scard kset1
(integer) 3
127.0.0.1:6379>
127.0.0.1:6379> srem kset1 1
(integer) 1
127.0.0.1:6379> scard kset1
(integer) 3
127.0.0.1:6379> SRANDMEMBER kset1
"2"
127.0.0.1:6379> srandmember kset1 2
1) "a"
2) "b"
127.0.0.1:6379> smove kset1 kset2 a
(integer) 1
127.0.0.1:6379> smembers kset2
1) "a"
127.0.0.1:6379> smembers kset1
1) "b"
2) "2"
127.0.0.1:6379> sadd kset b 2 3 4
(integer) 4
127.0.0.1:6379> spop kset
"3"
127.0.0.1:6379> sismember kset 3
(integer) 0
127.0.0.1:6379> sunion kset1 kset
1) "b"
2) "4"
3) "2"
127.0.0.1:6379> sunionstore kset3 kset1 kset
(integer) 3
127.0.0.1:6379> smembers kset3
1) "b"
2) "4"
3) "2"
127.0.0.1:6379> sinter kset1 kset
1) "b"
2) "2"5、有序集合(sorted sets)
Redis 有序集合是string类型元素的有序集合,且不允许重复的成员。有序集合的成员是唯一的,但分数(score)却可以重复。赋值时需要手工给每个元素关联一个double类型的分数。redis正是通过分数来为集合中的成员进行从小到大的排序。
集合中最大的成员数为 2^32 - 1 (4294967295, 每个集合可存储40多亿个成员)。
1)常用 Redis命令:
命令描述ZADD key [NX|XX] [CH] [INCR] score member [score member ...]向有序集合添加一个或多个成员,或者更新已存在成员的分数ZRANGE key start stop [WITHSCORES]获取有序集合key中的指定范围的元素。 返回的元素可以认为是按得分从最低到最高排列。 如果得分相同,将按字典排序。WITHSCORES选项,可将元素的分数与元素一起返回。ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]通过分数返回有序集合指定区间内的成员,分数由低到高排序ZSCORE key member获取有序集key中,成员score值。key不存在,返回nil。ZRANK key member返回有序集key中成员member的排名数。其中有序集成员按score值递增(从小到大)顺序排列。ZREVRANK key member返回有序集key中成员member的排名数,其中有序集成员按score值递减(从大到小)顺序排列。ZREM key member [member ...]移除有序集合中的一个或多个成员ZREMRANGEBYSCORE key min max移除有序集key中,所有score值介于min和max之间(包括等于min或max)的成员。ZREMRANGEBYRANK key start stop移除有序集key中,指定排名(rank)区间内的所有成员ZCARD key返回key的有序集元素的个数。ZCOUNT key min max返回有序集key中,score值在min和max之间(默认包括score值等于min或max)的成员。ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight] [SUM|MIN|MAX]计算给定的一个或多个有序集的交集并将结果集存储在新的有序集合 key 中2)实例:
127.0.0.1:6379> zadd kzset1 1 aa 2 bb 1 dd 4 cc
(integer) 4
127.0.0.1:6379> zrange kzset1 0 -1
1) "aa"
2) "dd"
3) "bb"
4) "cc"
127.0.0.1:6379> zrangebyscore kzset1 1 3 withscores
1) "aa"
2) "1"
3) "dd"
4) "1"
5) "bb"
6) "2"
127.0.0.1:6379> zscore kzset1 cc
"4"
127.0.0.1:6379> zrank kzset1 cc
(integer) 3
127.0.0.1:6379> zrank kzset1 dd
(integer) 1
127.0.0.1:6379> zrevrank kzset1 aa
(integer) 3
127.0.0.1:6379> zrem kzset1 aa
(integer) 1
127.0.0.1:6379> zremrangebyscore kzset1 1 2
(integer) 2
127.0.0.1:6379> zadd kzset1 5 ff 6 gg 8 jj 9 hh
(integer) 4
127.0.0.1:6379> zrange kzset1 0 -1
1) "cc"
2) "ff"
3) "gg"
4) "jj"
5) "hh"
127.0.0.1:6379> zremrangebyrank kzset1 3 4
(integer) 2
127.0.0.1:6379> zcard kzset1
(integer) 3
127.0.0.1:6379> zrange kzset1 0 -1 withscores
1) "cc"
2) "4"
3) "ff"
4) "5"
5) "gg"
6) "6"
127.0.0.1:6379> zcount kzset1 5 6
(integer) 2
127.0.0.1:6379> zadd kzset2 1 aa 5 cc 2 ff
(integer) 3
127.0.0.1:6379> ZINTERSTORE kzset3 2 kzset1 kzset2 aggregate SUM
(integer) 2
127.0.0.1:6379> zrange kzset3 0 -1 withscores
1) "ff"
2) "7"
3) "cc"
4) "9"6、基数统计(HyperLogLog)
Redis HyperLogLog 是用来做基数(不重复元素)统计的算法,优点是:海量数据的计算时,计算基数所需的空间总是固定的并且占用空间小。在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。但是,因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
HyperLogLog 可以接受多个元素作为输入,并给出输入元素的基数估算值:
基数:集合中不同元素的数量。
估算值:算法给出的基数并不是精确的,可能会比实际稍微多一些或者稍微少一些,但会控制在合理的范围之内。
1)常用 Redis命令:
命令描述PFADD key element [element ...]添加指定元素到 HyperLogLog 中。如果 HyperLogLog 的内部被修改了,那么返回 1,否则返回 0 .PFCOUNT key [key ...]返回给定 HyperLogLog 的基数估算值。如果不存在,则返回0.PFMERGE destkey sourcekey [sourcekey ...]将多个 HyperLogLog 合并为一个 HyperLogLog,合并的结果会被储存在目标变量2)实例:
统计网站每天访问的独立IP数量的功能:
1)使用集合,随着ip数量的增加,耗费的内存会越多。
2)使用HyperLogLog 基数统计,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 2^64 个不同元素的基数。
127.0.0.1:6379> PFADD unique::ip::counter '192.168.198.5' '127.0.0.1' '127.0.0.1'
(integer) 1
127.0.0.1:6379> PFADD unique::ip::counter '255.255.255.255' '255.255.255.255' '255.255.255.255'
(integer) 1
127.0.0.1:6379> PFCOUNT unique::ip::counter
(integer) 3
127.0.0.1:6379> PFADD unique::ip::counter2 '192.168.198.55' '127.0.0.4'
(integer) 1
127.0.0.1:6379> PFMERGE uniqueIp unique::ip::counter unique::ip::counter2
OK
127.0.0.1:6379> PFCOUNT uniqueIp
(integer) 57、地理地图(GEO)
对GEO(地理位置)的数据支持。
1)常用 Redis命令:
命令描述GEOADD key longitude latitude member [longitude latitude member ...]将指定的地理空间位置(纬度、经度、名称)添加到指定的key中。 返回值:添加到sorted set元素的数目,但不包括已更新score的元素。
- 有效的经度从-180度到180度。
- 有效的纬度从-85.05112878度到85.05112878度。
- m 表示单位为米。
- km 表示单位为千米。
- mi 表示单位为英里。
- ft 表示单位为英尺。
以给定的经纬度为中心, 返回键包含的位置元素当中, 与中心的距离不超过给定最大距离的所有位置元素。 在给定以下可选项时, 命令会返回额外的信息:
WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。 距离的单位和用户给定的范围单位保持一致。WITHCOORD: 将位置元素的经度和维度也一并返回。WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。
命令默认返回未排序的位置元素。 通过以下两个参数, 用户可以指定被返回位置元素的排序方式:
ASC: 根据中心的位置, 按照从近到远的方式返回位置元素。DESC: 根据中心的位置, 按照从远到近的方式返回位置元素。
2)实例:
127.0.0.1:6379> geoadd kcityGeo 116.405285 39.904989 "beijing"
(integer) 1
127.0.0.1:6379> geoadd kcityGeo 121.472644 31.231706 "shanghai"
(integer) 1
127.0.0.1:6379> geodist kcityGeo beijing shanghai km
"1067.5980"
127.0.0.1:6379> geopos kcityGeo beijing
1) 1) "116.40528291463851929"
2) "39.9049884229125027"
127.0.0.1:6379> geohash kcityGeo beijing
1) "wx4g0b7xrt0"
127.0.0.1:6379> georadiusbymember kcityGeo beijing 1200 km withdist withcoord asc count 5
1) 1) "beijing"
2) "0.0000"
3) 1) "116.40528291463851929"
2) "39.9049884229125027"
2) 1) "shanghai"
2) "1067.5980"
3) 1) "121.47264629602432251"
2) "31.23170490709807012"8、流(Stream) -- 这里简单了解
对于 stream 详细使用和解释参考:https://www.zhihu.com/question/279540635
Stream是Redis 5.0引入的一种新数据类型。它是一个新的强大的支持多播的可持久化的消息队列,
Redis Stream的结构有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的ID和对应的内容。消息是持久化的,Redis重启后,内容还在。
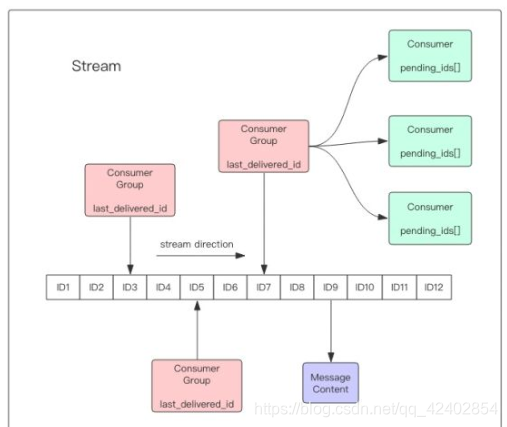
每个Stream都有唯一的名称,它就是Redis的key,在我们首次使用xadd指令追加消息时自动创建。
每个Stream都可以挂多个消费组,每个消费组会有个游标last_delivered_id在Stream数组之上往前移动,表示当前消费组已经消费到哪条消息了。每个消费组都有一个Stream内唯一的名称,消费组不会自动创建,它需要单独的指令xgroup create进行创建,需要指定从Stream的某个消息ID开始消费,这个ID用来初始化last_delivered_id变量。
每个消费组(Consumer Group)的状态都是独立的,相互不受影响。也就是说同一份Stream内部的消息会被每个消费组都消费到。
同一个消费组(Consumer Group)可以挂接多个消费者(Consumer),这些消费者之间是竞争关系,任意一个消费者读取了消息都会使游标last_delivered_id往前移动。每个消费者者有一个组内唯一名称。
消费者(Consumer)内部会有个状态变量pending_ids,它记录了当前已经被客户端读取的消息,但是还没有ack。如果客户端没有ack,这个变量里面的消息ID会越来越多,一旦某个消息被ack,它就开始减少。这个pending_ids变量在Redis官方被称之为PEL,也就是Pending Entries List,这是一个很核心的数据结构,它用来确保客户端至少消费了消息一次,而不会在网络传输的中途丢失了没处理。
消息ID
消息ID的形式是timestampInMillis-sequence,例如1527846880572-5,它表示当前的消息在毫米时间戳1527846880572时产生,并且是该毫秒内产生的第5条消息。消息ID可以由服务器自动生成,也可以由客户端自己指定,但是形式必须是整数-整数,而且必须是后面加入的消息的ID要大于前面的消息ID。
消息内容
消息内容就是键值对,形如hash结构的键值对,这没什么特别之处。
1)常用 Redis列表命令:
命令描述XADD key ID field string [field string ...]将指定的流条目追加到指定key的流中,如果指定的ID参数是字符 * ,XADD命令会自动为您生成一个唯一的ID。 XDEL key ID [ID ...]删除消息,XRANGE key start end [COUNT count]返回流中满足给定ID范围的条目。范围由最小和最大ID指定。特殊ID:-和+分别表示流中可能的最小ID和最大IDXREVRANGE key end start [COUNT count]返回流中满足给定ID范围的条目。与 XRANGE结果相反
XLEN key返回流中的条目数。如果指定的key不存在,则此命令返回0XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...]从一个或者多个流中读取数据,仅返回ID大于调用者报告的最后接收ID的条目。此命令有一个阻塞选项,用于等待可用的项目2)实例:
127.0.0.1:6379> XADD mystream * field1 value1 field2 value2 field3 value3
"1588491680862-0"
127.0.0.1:6379> XADD mystream * username lisi age 18
"1588491854070-0"
127.0.0.1:6379> xlen mystream
(integer) 2
127.0.0.1:6379> XADD mystream * username lisi age 18
"1588491861215-0"
127.0.0.1:6379> xrange mystream - +
1) 1) "1588491680862-0"
2) 1) "field1"
2) "value1"
3) "field2"
4) "value2"
5) "field3"
6) "value3"
2) 1) "1588491854070-0"
2) 1) "username"
2) "lisi"
3) "age"
4) "18"
3) 1) "1588491861215-0"
2) 1) "username"
2) "lisi"
3) "age"
4) "18"
127.0.0.1:6379> xdel mystream 1588491854070-0
(integer) 1
127.0.0.1:6379> xrange mystream - +
1) 1) "1588491680862-0"
2) 1) "field1"
2) "value1"
3) "field2"
4) "value2"
5) "field3"
6) "value3"
2) 1) "1588491861215-0"
2) 1) "username"
2) "lisi"
3) "age"
4) "18"
127.0.0.1:6379> xlen mystream
(integer) 2如果Redis做集群就没有数据库的概念。
Redis支持多个数据库,并且每个数据库的数据是隔离的不能共享,并且是基于单机才有。每个数据库对外都是一个从0开始的递增数字命名,Redis默认支持16个数据库(可以通过配置文件支持更多,无上限),可以通过配置databases来修改这一数字。客户端与Redis建立连接后会自动选择0号数据库,不过可以随时使用SELECT命令更换数据库。
127.0.0.1:6379> select 1
OK
127.0.0.1:6379[1]> 注意:
1)Redis不支持自定义数据库的名字,每个数据库都以编号命名,开发者必须自己记录哪些数据库存储了哪些数据。
2)Redis也不支持为每个数据库设置不同的访问密码,所以一个客户端要么可以访问全部数据库,要么连一个数据库也没有权限访问。
3)多个数据库之间并不是完全隔离的,比如 FLUSHALL 命令可以清空一个Redis实例中所有数据库中的数据。
ends

