参考文章:https://www.jianshu.com/p/b77e80d6c18e
先了解es的调用链路——看一次搜索的时序图一次查询分为三部分
-
将用户请求restRequest 转发到应该处理本次请求的RestAction
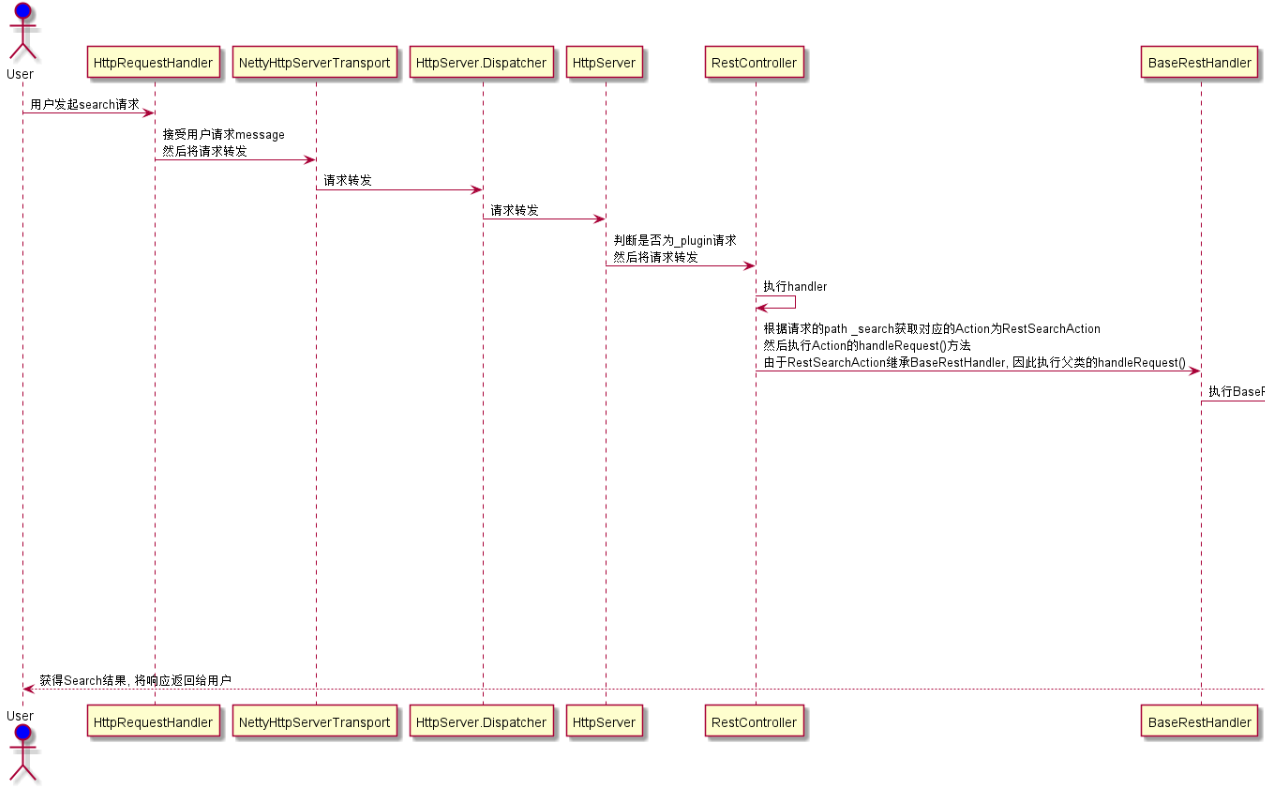
以search查询为例:一次调用链路:
Netty4HttpRequestHandler#channelRead0() 调用 Netty4HttpServerTransport#dispatchRequest()
Netty4HttpServerTransport#dispatchRequest() 这里是接口
RestController#dispatchRequest()实现了上边的接口
接着调用了RestController#tryAllHandlers()
RestController#tryAllHandlers() 调用 RestController#dispatchRequest()
RestController#dispatchRequest() 调用 BaseRestHandler#handleRequest()
BaseRestHandler#handleRequest() 调用子类RestSearchAction#prepareRequest()
-
将RestRequest(http层面的请求)转换成 SearchRequest(es内部认识能处理的请求),然后调用search(),此时相当于进入到了controller层。
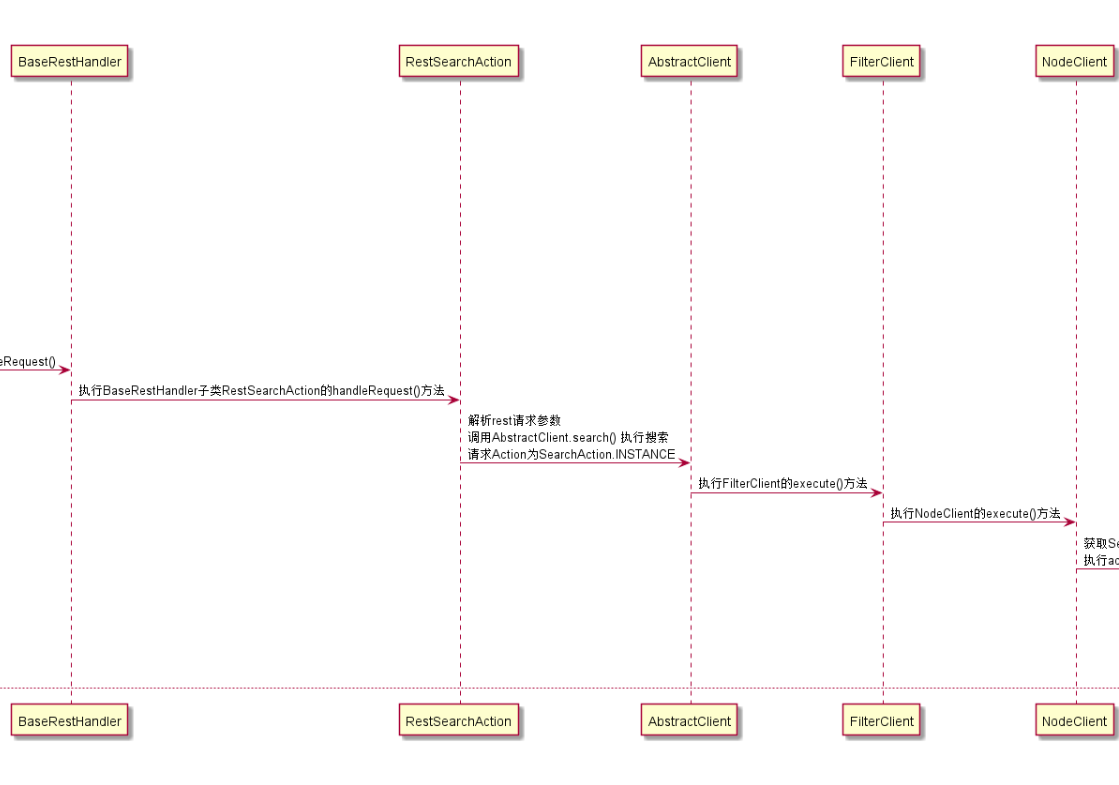
-
还要根据请求,来找到要处理的服务层,对应es的是TransportSearchAction,调用其子类的execute()方法来执行搜索。
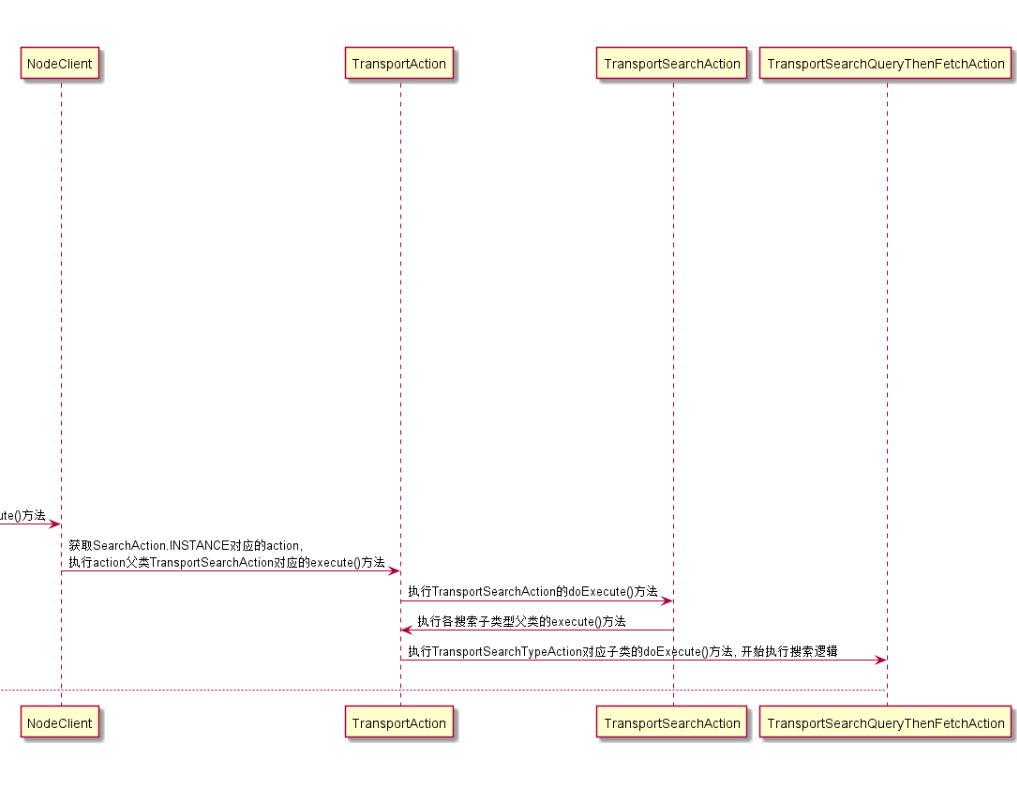
实际上对应时序图中的第二部分,对应的代码在RestSearchAction类中
RestSearchAction类继承了BaseRestHandler类,重写了prepareRequest方法。
@Override
public RestChannelConsumer prepareRequest(final RestRequest request, final NodeClient client) throws IOException {
SearchRequest searchRequest = new SearchRequest();
searchRequest.remoteAddress(new TransportAddress((InetSocketAddress)request.getRemoteAddress()));
IntConsumer setSize = size -> searchRequest.source().size(size);
// 下边的 parser -> 是一个lambda表达式。理解起来不太容易。要清楚 parser是在RestRequest#withContentOrSourceParamParserOrNull()方法中完成构建的!知道这一点很重要,因为这个parser是非常重要的。它将请求中的条件进行了解析。并作为了参数给了parseSearchRequest()方法,在该方法里边,去构造了查询条件。
request.withContentOrSourceParamParserOrNull(parser ->
//重点在这里,将RestRequest转换成了SearchRequest
parseSearchRequest(searchRequest, request, parser, setSize));
return channel -> client.search(searchRequest, new RestStatusToXContentListener(channel));
}
可以看下一下RestRequest#withContentOrSourceParamParserOrNull()方法
从RestRequest对象中,获取请求内容,转成XContentParser对象。
public final void withContentOrSourceParamParserOrNull(CheckedConsumer withParser) throws IOException {
if (hasContentOrSourceParam()) {
Tuple tuple = contentOrSourceParam();
BytesReference content = tuple.v2();
XContentType xContentType = tuple.v1();
try (InputStream stream = content.streamInput();
// 在这里创建了 parser出来,注意这里
XContentParser parser = xContentType.xContent()
.createParser(xContentRegistry, LoggingDeprecationHandler.INSTANCE, stream)) {
withParser.accept(parser);
}
} else {
withParser.accept(null);
}
}
接着再看 parseSearchRequest() 方法源码
/**
* Parses the rest request on top of the SearchRequest, preserving values that are not overridden by the rest request.
*
* @param requestContentParser body of the request to read. This method does not attempt to read the body from the {@code request}
* parameter
* @param setSize how the size url parameter is handled. {@code udpate_by_query} and regular search differ here.
*/
public static void parseSearchRequest(SearchRequest searchRequest, RestRequest request,
XContentParser requestContentParser,
IntConsumer setSize) throws IOException {
if (searchRequest.source() == null) {
searchRequest.source(new SearchSourceBuilder());
}
// 获取到索引的索引
searchRequest.indices(Strings.splitStringByCommaToArray(request.param("index")));
if (requestContentParser != null) {
// 这里是重点!正是这个方法,将http的查询条件,转换成了es的查询条件。
searchRequest.source().parseXContent(requestContentParser, true);
}
final int batchedReduceSize = request.paramAsInt("batched_reduce_size", searchRequest.getBatchedReduceSize());
searchRequest.setBatchedReduceSize(batchedReduceSize);
searchRequest.setPreFilterShardSize(request.paramAsInt("pre_filter_shard_size", searchRequest.getPreFilterShardSize()));
if (request.hasParam("max_concurrent_shard_requests")) {
// only set if we have the parameter since we auto adjust the max concurrency on the coordinator
// based on the number of nodes in the cluster
final int maxConcurrentShardRequests = request.paramAsInt("max_concurrent_shard_requests",
searchRequest.getMaxConcurrentShardRequests());
searchRequest.setMaxConcurrentShardRequests(maxConcurrentShardRequests);
}
if (request.hasParam("allow_partial_search_results")) {
// only set if we have the parameter passed to override the cluster-level default
searchRequest.allowPartialSearchResults(request.paramAsBoolean("allow_partial_search_results", null));
}
// do not allow 'query_and_fetch' or 'dfs_query_and_fetch' search types
// from the REST layer. these modes are an internal optimization and should
// not be specified explicitly by the user.
String searchType = request.param("search_type");
if ("query_and_fetch".equals(searchType) ||
"dfs_query_and_fetch".equals(searchType)) {
throw new IllegalArgumentException("Unsupported search type [" + searchType + "]");
} else {
searchRequest.searchType(searchType);
}
parseSearchSource(searchRequest.source(), request, setSize);
searchRequest.requestCache(request.paramAsBoolean("request_cache", null));
String scroll = request.param("scroll");
if (scroll != null) {
searchRequest.scroll(new Scroll(parseTimeValue(scroll, null, "scroll")));
}
searchRequest.types(Strings.splitStringByCommaToArray(request.param("type")));
searchRequest.routing(request.param("routing"));
searchRequest.preference(request.param("preference"));
searchRequest.indicesOptions(IndicesOptions.fromRequest(request, searchRequest.indicesOptions()));
}
进入parseXContent()方法
/**
* Parse some xContent into this SearchSourceBuilder, overwriting any values specified in the xContent. Use this if you need to set up
* different defaults than a regular SearchSourceBuilder would have and use {@link #fromXContent(XContentParser, boolean)} if you have
* normal defaults.
*
* @param parser The xContent parser.
* @param checkTrailingTokens If true throws a parsing exception when extra tokens are found after the main object.
*/
public void parseXContent(XContentParser parser, boolean checkTrailingTokens) throws IOException {
XContentParser.Token token = parser.currentToken();
String currentFieldName = null;
if (token != XContentParser.Token.START_OBJECT && (token = parser.nextToken()) != XContentParser.Token.START_OBJECT) {
throw new ParsingException(parser.getTokenLocation(), "Expected [" + XContentParser.Token.START_OBJECT +
"] but found [" + token + "]", parser.getTokenLocation());
}
while ((token = parser.nextToken()) != XContentParser.Token.END_OBJECT) {
if (token == XContentParser.Token.FIELD_NAME) {
currentFieldName = parser.currentName();
// 如果是查询条件的参数,例如:from size
} else if (token.isValue()) {
if (FROM_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
from = parser.intValue();
} else if (SIZE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
size = parser.intValue();
} else if (TIMEOUT_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
timeout = TimeValue.parseTimeValue(parser.text(), null, TIMEOUT_FIELD.getPreferredName());
} else if (TERMINATE_AFTER_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
terminateAfter = parser.intValue();
} else if (MIN_SCORE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
minScore = parser.floatValue();
} else if (VERSION_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
version = parser.booleanValue();
} else if (SEQ_NO_PRIMARY_TERM_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
seqNoAndPrimaryTerm = parser.booleanValue();
} else if (EXPLAIN_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
explain = parser.booleanValue();
} else if (TRACK_SCORES_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
trackScores = parser.booleanValue();
} else if (TRACK_TOTAL_HITS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
trackTotalHits = parser.booleanValue();
} else if (_SOURCE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
fetchSourceContext = FetchSourceContext.fromXContent(parser);
} else if (STORED_FIELDS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
storedFieldsContext =
StoredFieldsContext.fromXContent(SearchSourceBuilder.STORED_FIELDS_FIELD.getPreferredName(), parser);
} else if (SORT_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
sort(parser.text());
} else if (PROFILE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
profile = parser.booleanValue();
} else {
throw new ParsingException(parser.getTokenLocation(), "Unknown key for a " + token + " in [" + currentFieldName + "].",
parser.getTokenLocation());
}
// 如果是查询条件 例如:query agg
} else if (token == XContentParser.Token.START_OBJECT) {
if (QUERY_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
// 构造查询条件
queryBuilder = parseInnerQueryBuilder(parser);
} else if (POST_FILTER_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
postQueryBuilder = parseInnerQueryBuilder(parser);
} else if (_SOURCE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
fetchSourceContext = FetchSourceContext.fromXContent(parser);
} else if (SCRIPT_FIELDS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
scriptFields = new ArrayList();
while ((token = parser.nextToken()) != XContentParser.Token.END_OBJECT) {
scriptFields.add(new ScriptField(parser));
}
} else if (INDICES_BOOST_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
DEPRECATION_LOGGER.deprecated(
"Object format in indices_boost is deprecated, please use array format instead");
while ((token = parser.nextToken()) != XContentParser.Token.END_OBJECT) {
if (token == XContentParser.Token.FIELD_NAME) {
currentFieldName = parser.currentName();
} else if (token.isValue()) {
indexBoosts.add(new IndexBoost(currentFieldName, parser.floatValue()));
} else {
throw new ParsingException(parser.getTokenLocation(), "Unknown key for a " + token +
" in [" + currentFieldName + "].", parser.getTokenLocation());
}
}
} else if (AGGREGATIONS_FIELD.match(currentFieldName, parser.getDeprecationHandler())
|| AGGS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
aggregations = AggregatorFactories.parseAggregators(parser);
} else if (HIGHLIGHT_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
highlightBuilder = HighlightBuilder.fromXContent(parser);
} else if (SUGGEST_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
suggestBuilder = SuggestBuilder.fromXContent(parser);
} else if (SORT_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
sorts = new ArrayList(SortBuilder.fromXContent(parser));
} else if (RESCORE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
rescoreBuilders = new ArrayList();
rescoreBuilders.add(RescorerBuilder.parseFromXContent(parser));
} else if (EXT_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
extBuilders = new ArrayList();
String extSectionName = null;
while ((token = parser.nextToken()) != XContentParser.Token.END_OBJECT) {
if (token == XContentParser.Token.FIELD_NAME) {
extSectionName = parser.currentName();
} else {
SearchExtBuilder searchExtBuilder = parser.namedObject(SearchExtBuilder.class, extSectionName, null);
if (searchExtBuilder.getWriteableName().equals(extSectionName) == false) {
throw new IllegalStateException("The parsed [" + searchExtBuilder.getClass().getName() + "] object has a "
+ "different writeable name compared to the name of the section that it was parsed from: found ["
+ searchExtBuilder.getWriteableName() + "] expected [" + extSectionName + "]");
}
extBuilders.add(searchExtBuilder);
}
}
} else if (SLICE.match(currentFieldName, parser.getDeprecationHandler())) {
sliceBuilder = SliceBuilder.fromXContent(parser);
} else if (COLLAPSE.match(currentFieldName, parser.getDeprecationHandler())) {
collapse = CollapseBuilder.fromXContent(parser);
} else {
throw new ParsingException(parser.getTokenLocation(), "Unknown key for a " + token + " in [" + currentFieldName + "].",
parser.getTokenLocation());
}
} else if (token == XContentParser.Token.START_ARRAY) {
if (STORED_FIELDS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
storedFieldsContext = StoredFieldsContext.fromXContent(STORED_FIELDS_FIELD.getPreferredName(), parser);
} else if (DOCVALUE_FIELDS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
docValueFields = new ArrayList();
while ((token = parser.nextToken()) != XContentParser.Token.END_ARRAY) {
docValueFields.add(FieldAndFormat.fromXContent(parser));
}
} else if (INDICES_BOOST_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
while ((token = parser.nextToken()) != XContentParser.Token.END_ARRAY) {
indexBoosts.add(new IndexBoost(parser));
}
} else if (SORT_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
sorts = new ArrayList(SortBuilder.fromXContent(parser));
} else if (RESCORE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
rescoreBuilders = new ArrayList();
while ((token = parser.nextToken()) != XContentParser.Token.END_ARRAY) {
rescoreBuilders.add(RescorerBuilder.parseFromXContent(parser));
}
} else if (STATS_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
stats = new ArrayList();
while ((token = parser.nextToken()) != XContentParser.Token.END_ARRAY) {
if (token == XContentParser.Token.VALUE_STRING) {
stats.add(parser.text());
} else {
throw new ParsingException(parser.getTokenLocation(), "Expected [" + XContentParser.Token.VALUE_STRING +
"] in [" + currentFieldName + "] but found [" + token + "]", parser.getTokenLocation());
}
}
} else if (_SOURCE_FIELD.match(currentFieldName, parser.getDeprecationHandler())) {
fetchSourceContext = FetchSourceContext.fromXContent(parser);
} else if (SEARCH_AFTER.match(currentFieldName, parser.getDeprecationHandler())) {
searchAfterBuilder = SearchAfterBuilder.fromXContent(parser);
} else {
throw new ParsingException(parser.getTokenLocation(), "Unknown key for a " + token + " in [" + currentFieldName + "].",
parser.getTokenLocation());
}
} else {
throw new ParsingException(parser.getTokenLocation(), "Unknown key for a " + token + " in [" + currentFieldName + "].",
parser.getTokenLocation());
}
}
if (checkTrailingTokens) {
boolean success;
try {
token = parser.nextToken();
success = token == null;
} catch (JsonParseException exc) {
success = false;
}
if (success == false) {
DEPRECATION_LOGGER.deprecated("Found extra tokens after the _search request body, " +
"an error will be thrown in the next major version");
}
}
}


