
目录
1、数字辅助表
2、日期和时间值序列
3、序列键——更新列中的值为唯一值
4、分页
5、删除重复
6、数据透视
7、每组前N行
8、模式
9、统计总和
10、最大并发间隔
11、包装间隔
12、数据差距和数据岛
12.1、数据差距
12.2、数据岛
12.3、中位数
13、条件聚合
14、层次结构排序
说在前面
我所用的SQL版本为2017,而知识点基于SQL SERVER 2012说明,所以建议使用2012或以上版本测试。如果要完成下面案例的测试,请自行创建测试数据库(如TSQL2012)。有的解决方案不止此文所写,只是主要为了介绍窗口函数的优化解决方案而已。但是并不是说窗口函数的解决方案都是最优的(此篇所介绍的基本都是最优),而且限于篇幅,很多案例的更多解决方案并没有给出,有兴趣的也可以自行多研究。
此文涵盖的解决方案包含: Virtual Auxiliary Table of Numbers(虚拟数字辅動表)、 Sequences of Date and Time Values(日期和时间值序列)、 Sequences ofKeys(序列键)、 Paging(分页)、 Removing Duplicates(删除重复)、 Pivoting(数据透视)、 Top N Per Group(每组前N行)、Mode(模式)、 Running Totals(统计总和)、 Max Concurrent Intervals(最大并发间隔)、 Packing Intervals(包装间隔)、 Gaps and Islands(数据差距和数据岛)、 Median(中位数)、 ConditionalAggregate(条件聚合)和 Sorting Hierarchies(层次结构排序)。
如果对窗口函数的概念不是很熟悉,可以查看我之前的文章:SQL ——窗口函数简介 。
1、数字辅助表
数字辅助表是一个整数序列,可以用它来完成多种不同的查询任务。数字表有多种用途,如生成日期和实际值序列,以及分裂值表。
使用窗口函数实现的解决方案,以函数的形式完成,完整代码如下:
--创建一个函数,在要求的范围内产生一个整数序列
IF OBJECT_ID('dbo.GetNums','IF') IS NOT NULL
DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT ,@high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT C FROM (VALUES(1),(1)) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum FROM L5)
SELECT @low +rownum -1 AS N
FROM Nums
ORDER BY rownum
OFFSET 0 ROWS FETCH FIRST @high -@low +1 ROWS ONLY;
GO
注意,直到SQL SERVER 2012才兼容了OFFSET/FETCH选项,如果要兼容之前的版本,需要使用TOP选项。
修改如下:
--创建一个函数,在要求的范围内产生一个整数序列
IF OBJECT_ID('dbo.GetNums','IF') IS NOT NULL
DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT ,@high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT C FROM (VALUES(1),(1)) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum FROM L5)
SELECT TOP(@high-@low+1) @low +rownum -1 AS N
FROM Nums
ORDER BY rownum;
GO
在测试之前需要做些配置工作:

注意,如果要生成此函数,此操作可忽略!
测试结果如下:

2、日期和时间值序列
与数据操作相关的各种场景要求生成一个日期和时间序列,序列的范围是从输入值@start到@end,且有一定的时间间隔(如1天,12小时等)。这样的场景包括填充数据仓库的时间维度、应用程序的运行时间安排以及其他。使用上面生成的GetNums函数实现。
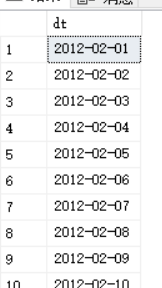
下面生成一个2012年2月1日到2012年02月12日之间的一个日期序列:
DECLARE
@start AS DATE ='20120201',
@end AS DATE ='20120212';
SELECT DATEADD(day,n ,@start) AS dt
FROM dbo.GetNums(0,DATEDIFF(day,@start,@end)) AS Nums;
结果如下:
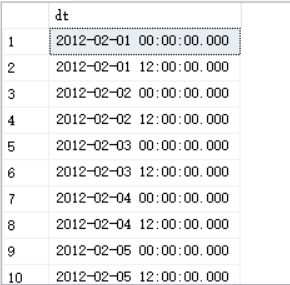
如果时间的间隔是12小时,可以参考如下案例:
DECLARE
@start AS DATETIME ='20120201 00:00:00',
@end AS DATETIME ='20120212 12:00:00';
SELECT DATEADD(hour,n*12 ,@start) AS dt
FROM dbo.GetNums(0,DATEDIFF(hour,@start,@end)/12) AS Nums;
结果如下:
3、序列键——更新列中的值为唯一值
当需要更新表中的数据或向表中插入数据时,在很多情况下需要产生唯一的整数序列键。本节将要描述的场景涉及如何处理数据质量问题。首先创建测试用例表:
IF OBJECT_ID('MyOrders','U') IS NOT NULL
DROP TABLE MyOrders;
GO
SELECT 0 AS orderid,custid,empid,orderdate
INTO MyOrders
FROM dbo.Orders;
--查看生成的表及相关数据
SELECT * FROM MyOrders;
生成数据如下:

注意,dbo.Orders表的结构和数据可以通过下面链接得到。 链接:https://pan.baidu.com/s/1_bHE3C6H589PXy-QDWdoDA 提取码:yi6i
假设由于数据质量问题,MyOrders表的orderid列的值不是唯一的。我的任务就是将orderid的值修改为唯一的值。
--修改orderid为唯一值
WITH C AS
(
SELECT orderid,ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.MyOrders
)
UPDATE C
SET orderid = rownum;
结果如下:

4、分页
在应用程序中经常用到分页(paging)。我们想让用户一次得到查询结果行的一部分,这样的结果可以更冗余大偶然目标网页、用户界面(UI)或屏幕中。ROW_NUMBER函数可用于此目的。根据所需的排序为结果行指定行号,然后根据给定的页码和页面大小参数筛选出正确范围内的行号。为了获得最佳性能,要定义窗口排序元素为索引键的索引,索引键还包括出现的查询中的其余列。
以表MyOrders为例,我们先给表创建索引:
--索引
CREATE UNIQUE INDEX idx_od_oid_i_cid_eid
ON MyOrders(orderdate,orderid)
INCLUDE(custid,empid);
具体实现如下:(获取第三页的25条记录,即51到75行)
--分页处理,具体可放到存储过程中,或者其他需要的地方
DECLARE
@pagenum AS INT =3,
@pagesize AS INT=25;
WITH C AS
(
SELECT ROW_NUMBER() OVER(ORDER BY orderdate,orderid) AS rownum,
orderid,orderdate,custid,empid
FROM MyOrders
)
SELECT orderid,orderdate,custid,empid
FROM C
WHERE rownum BETWEEN (@pagenum-1)*@pagesize-1 AND @pagenum * @pagesize
ORDER BY rownum;
执行计划如下:

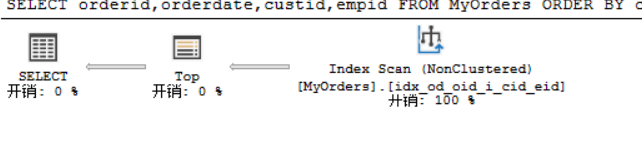
因为有索引支持ROW_NUMBER的计算,所以SQL SERVER 不需要扫描表中所有行 。相反,它只扫描索引中的前75行,然后筛选出行号为51到75的行。
在SQL SERVER 2005及更高版本中可以使用上述技术,如果是SQL SERVER 2012及以上版本还可以一个代替方案,即OFFSET/FETCH筛选选项。
--分页处理,具体可放到存储过程中,或者其他需要的地方 OFFSET/FETCH
DECLARE
@pagenum AS INT =3,
@pagesize AS INT=25;
SELECT orderid,orderdate,custid,empid
FROM MyOrders
ORDER BY orderdate,orderid
OFFSET (@pagenum-1)*@pagesize-1 ROWS FETCH NEXT @pagenum * @pagesize ROWS ONLY;
其执行计划如下:
5、删除重复
删除重复数据是一种常见的需求,尤其是由于缺乏强制执行约束的唯一性,致使数据存在重复行。
首先处理样本数据:
--样本数据
IF OBJECT_ID('dbo.MyOrders') IS NOT NULL
DROP TABLE dbo.MyOrders;
GO
SELECT * INTO dbo.MyOrders
FROM Orders
UNION ALL
SELECT * FROM Orders
UNION ALL
SELECT * FROM Orders;
假设需要删除重复数据,每个ORDERID值只保留唯一的一行。
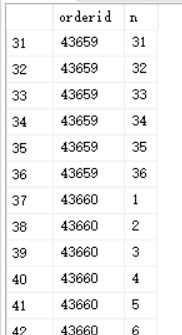
--标记重复行
SELECT orderid,
ROW_NUMBER() OVER(PARTITION BY orderid
ORDER BY (SELECT NULL)) AS n
FROM dbo.MyOrders;
结果如下:
如果是少量的重复数据,可以移除所有行号大于1的行,如下:
--重复数据少的时候使用如下方法
WITH C AS
(
SELECT orderid,
ROW_NUMBER() OVER(PARTITION BY orderid
ORDER BY (SELECT NULL)) AS n
FROM dbo.MyOrders
)
DELETE FROM C
WHERE n>1;
但是如果需要删除大量的行,特别是当此数字代表的行在表中占很大比例时,完全记录的删除操作会很慢。这样可以考虑以下方法:
WITH C AS
(
SELECT orderid,
ROW_NUMBER() OVER(ORDER BY orderid) AS rownum,
RANK() OVER(ORDER BY orderid) AS rnk
FROM dbo.MyOrders
)
DELETE FROM C
WHERE rownumrnk;
上述方法只能在SQL SERVER 2012 及以上版本可用,且上述的解决方案不是唯一的。例如在有些时候可以使用TOP选项分批完成一个大型删除。但在这里我想重点介绍使用窗口函数的解决方案。
6、数据透视
透视是一种通过聚合和旋转把数据行转换成数据列的技术。当透视数据时,需要确定3个要素:要在行(分组元素)中看到的元素,要在列(扩展元素)上看到的元素,要在数据部分看到的元素(聚合元素)。
例如,假设我们需要查询OrderValues表,并未每个订单年返回一行,每个订单月为一列,年份和月份相交的每一个地方是订单金额总和。基于此请求,行或分组的元素是YEAR(orderdate);列或展开的元素是MONTH(orderdate);唯一扩展值是1,2到12;数据或聚合的元素是SUM(val)。
如下:
WITH C AS
(
SELECT YEAR(orderdate) AS orderyear,MONTH(orderdate) AS ordermonth,val
FROM OrderValues
)
SELECT *
FROM C
PIVOT(SUM(val)
FOR ordermonth IN([1],[2],[3],[4],[5],[6],[7],[8],[9],[10],[11],[12])) AS P;注意,此节使用的表及数据可通过下面链接获取。链接:https://pan.baidu.com/s/1Zr1PHO1hfCSUxCR_04Yh7Q 提取码:vg27
但有些情况下,扩展元素不存在数据源中,需要进行计算。例如为每一个客户返回最近5次订单的订单ID。我们希望在行上看到客户ID,在数据部分看到订单ID,但不同客户的订单ID之间没有共同点可以用来作为扩展元素。
解决方案是使用ROW_NUMBER函数在每个客户分区内为每个订单ID分配序号,根据所需的排序——这里是orderdate DESC、orderid DESC。然后代表该行的行号的列可以用作扩展元素,并作为扩展值计算的行号。
如下:
WITH C AS
(
SELECT custid, val,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC,orderid DESC) AS rownum
FROM OrderValues
)
SELECT *
FROM C
PIVOT(MAX(val) FOR rownum IN([1],[2],[3],[4],[5])) AS P;
结果如下:

如果我们需要把每个客户最近的5个订单ID连成一个字符串,可以使用CONCAT函数(SQL SERVER 2012或者以上版本提供),如下:
WITH C AS
(
SELECT custid, CAST(orderid AS NVARCHAR(20)) AS sorderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC,orderid DESC) AS rownum
FROM OrderValues
)
SELECT custid,CONCAT([1],','+[2],','+[3],','+[4],','+[5]) AS orderids
FROM C
PIVOT(MAX(sorderid) FOR rownum IN([1],[2],[3],[4],[5])) AS P;
结果如下:

CONCAT函数会自动用一个空字符串体会NULL。要在SQL SERVER 2012之前的版本中达到相同的目的,可以使用‘+’连接运算符和COALESCE函数来用空字符串替换NULL,如下:
WITH C AS
(
SELECT custid, CAST(orderid AS NVARCHAR(20)) AS sorderid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC,orderid DESC) AS rownum
FROM OrderValues
)
SELECT custid,
[1]+COALESCE(','+[2],'')
+COALESCE(','+[3],'')
+COALESCE(','+[4],'')
+COALESCE(','+[5],'') AS orderids
FROM C
PIVOT(MAX(sorderid) FOR rownum IN([1],[2],[3],[4],[5])) AS P;7、每组前N行
当需要从每个组或分区中更加某种指定拍下筛选出一定数量的行时,通常都会用到每组前N行查询。例如,查询MyOrders表,并为每个客户返回最近的3个订单。
首先我们需要根据POC(Partioning、Ordering、Covering)理念来创建索引:
--索引
CREATE UNIQUE INDEX idx_cid_odD_oidD_i_empid
ON dbo.MyOrders(custid,orderdate DESC,orderid DESC)
INCLUDE(empid);
有两种策略来完成该任务:一种是使用ROW_NUMBER函数;而另一种使用APPLY运算符和OFFSET/FETCH或TOP。哪一种策略更有效由分区列(这里是custid)的密度决定。低密度——意味着有大量不同的客户,每个客户的订单都很小——基于ROW_NUMBER函数的解决方案是最佳的。
如下:
WITH C AS
(
SELECT custid,orderdate,orderid,empid,
ROW_NUMBER() OVER(PARTITION BY custid
ORDER BY orderdate DESC,orderid DESC) AS rownum
FROM MyOrders
)
SELECT *
FROM C
WHERE rownum=starttime)
);
GO
IF OBJECT_ID('dbo.Users') IS NOT NULL
DROP TABLE dbo.Users;
GO
CREATE TABLE dbo.Users
(
username VARCHAR(14) NOT NULL,
CONSTRAINT PK_Users PRIMARY KEY(username)
);
GO
接下来添加数据:
--添加数据
DECLARE
@num_users AS INT =2000,
@intervals_per_user AS INT =2500,
@start_period AS DATETIME ='20120101',
@end_period AS DATETIME ='20120107',
@max_duration_in_ms AS INT =3600000;
--先清除数据
TRUNCATE TABLE dbo.Users;
TRUNCATE TABLE dbo.Sessions;
INSERT INTO dbo.Users(username)
SELECT 'User'+RIGHT('000000000'+CAST(U.n AS VARCHAR(10)),10) AS username
FROM dbo.GetNums(1,@num_users) AS U;
WITH C AS
(
SELECT 'User'+RIGHT('000000000'+CAST(U.n AS VARCHAR(10)),10) AS username,
DATEADD(ms,ABS(CHECKSUM(NEWID()))%86400000,
DATEADD(DAY,ABS(CHECKSUM(NEWID()))%DATEDIFF(DAY,@start_period,@end_period),
@start_period)) AS starttime
FROM dbo.GetNums(1,@num_users) AS U
CROSS JOIN dbo.GetNums(1,@intervals_per_user) AS I
)
INSERT INTO dbo.Sessions WITH(TABLOCK) (username,starttime,endtime)
SELECT username,starttime,
DATEADD(ms,ABS(CHECKSUM(NEWID()))%(@max_duration_in_ms+1),starttime) AS endtime
FROM C;
此段代码为Sessions表填充5000000行数据。数据包含2000名用户,每个用户一周之内有2500个会话,每个会话长达一个小时。我们可以改变代码中任何想要更改的元素来测试解决方案的性能。
首先来介绍传统的基于集合的解决方案,为提高性能,我们先添加以下索引。
--索引 以提高性能
CREATE INDEX idx_user_start_end ON dbo.Sessions(username,starttime,endtime);
CREATE INDEX idx_user_end_start ON dbo.Sessions(username,endtime,starttime);
解决方案的完整代码如下:
--传统的基于集合的解决方案
WITH StartTimes AS
(
SELECT DISTINCT username,starttime
FROM dbo.Sessions AS S1
WHERE NOT EXISTS
(
SELECT *
FROM dbo.Sessions AS S2
WHERE S2.username = s1.username
AND S2.starttime=s1.endtime
)
),
EndTimes AS
(
SELECT DISTINCT username,endtime
FROM dbo.Sessions AS S1
WHERE NOT EXISTS
(
SELECT *
FROM dbo.Sessions AS S2
WHERE S2.username = s1.username
AND S2.endtime=s1.starttime
)
)
SELECT username,starttime,
(SELECT MIN(endtime) FROM EndTimes AS E
WHERE E.username= S.username
AND endtime >= starttime) AS endtime
FROM StartTimes AS S;
看下其执行计划:

在有5000000行记录的Sessions上运行了好几个小时(原文所说,没有亲自尝试)。
在继续之前,我们先删除前面创建的索引:
--删除索引
DROP INDEX idx_user_start_end ON dbo.Sessions;
DROP INDEX idx_user_end_start ON dbo.Sessions;
接下来介绍两个比传统的解决方案速度更快的基于窗口函数的解决方案。创建以下索引以支持新的解决方案:
--窗口函数的 索引
CREATE INDEX idx_user_start_id ON dbo.Sessions(username,starttime,id);
CREATE INDEX idx_user_end_id ON dbo.Sessions(username,endtime,id);
前两个新策略是依靠ROW_NUMBER函数,所以在SQL SERVER 2005及以上版本都可以运行。解决方案代码如下:
--窗口函数 利用行号来打包间隔
WITH C1 AS
--let e = end ordinals,let s = start ordinals
(
SELECT id,username,starttime AS ts, +1 AS type,NULL AS e,
ROW_NUMBER() OVER(PARTITION BY username
ORDER BY starttime,id) AS s
FROM dbo.Sessions
UNION ALL
SELECT id,username,endtime AS ts, -1 AS type,
ROW_NUMBER() OVER(PARTITION BY username
ORDER BY endtime,id) AS e,
NULL AS s
FROM dbo.Sessions
),
C2 AS
-- let se = start or end ordinal, namely ,how many events ( start or end) happended so far
(
SELECT C1.*,
ROW_NUMBER() OVER(PARTITION BY username
ORDER BY ts,type DESC,id) AS se
FROM C1
),
C3 AS
(
SELECT username,ts,
FLOOR((ROW_NUMBER() OVER(PARTITION BY username
ORDER BY ts)-1)/2+1) AS grpnum
FROM C2
WHERE COALESCE(s-(se-s)-1,(se-s)-s) = 0
)
SELECT username,MIN(ts) AS starttime,MAX(ts) AS endtime
FROM C3
GROUP BY username,grpnum;
注意,一个包装的间隔总是在开始事件之前的活动会话的数量是零时开始,结束事件之后的活动会话的数量是零时结束。因此,对于每个开始事件,我们需要知道在它之前有多少活动会话,并且对于每个结束事件,我们需要知道在它之后有多少个活动会话。
其执行计划如下:

总体而言,这个计划只是对数据执行了两次扫描(每个索引一次),并按照索引的顺序扫描。该解决方案在我的笔记本上执行了6s。这个解决方案没有利用好的一个地方是并行性。就是下面介绍的这个解决方案的过人之处:
--窗口函数 ROW_NUMBER 解决并行性
IF OBJECT_ID('dbo.UserIntervals1') IS NOT NULL
DROP FUNCTION dbo.UserIntervals1;
GO
CREATE FUNCTION dbo.UserIntervals1(@user AS VARCHAR(14)) RETURNS TABLE
AS
RETURN
WITH C1 AS
(
SELECT id,starttime AS ts, +1 AS type,NULL AS e,
ROW_NUMBER() OVER(PARTITION BY username
ORDER BY starttime,id) AS s
FROM dbo.Sessions
WHERE username=@user
UNION ALL
SELECT id,endtime AS ts, -1 AS type,
ROW_NUMBER() OVER(PARTITION BY username
ORDER BY endtime,id) AS e,
NULL AS s
FROM dbo.Sessions
WHERE username=@user
),
C2 AS
(
SELECT C1.*,
ROW_NUMBER() OVER(ORDER BY ts,type DESC,id) AS se
FROM C1
),
C3 AS
(
SELECT ts,
FLOOR((ROW_NUMBER() OVER(ORDER BY ts)-1)/2+1) AS grpnum
FROM C2
WHERE COALESCE(s-(se-s)-1,(se-s)-s) = 0
)
SELECT MIN(ts) AS starttime,MAX(ts) AS endtime
FROM C3
GROUP BY grpnum;
GO
最后,利用CROSS APPLY运算符对Users表中的每个用户调用这个函数,如下所示:
--利用CROSS APPLY解决
SELECT U.username,A.starttime,A.endtime
FROM dbo.Users AS U
CROSS APPLY dbo.UserIntervals1(U.username) AS A;
执行计划如下(该方案在我的笔记本上执行了2s):

第二个基于窗口函数的新解决方案。它是利用SUM窗口集合函数,并依靠SQL SERVER 2012 中引入的窗口规范中的元素。
完整的代码如下:
--SUM 函数解决方案
WITH C1 AS
(
SELECT username,starttime AS ts, +1 AS type,1 AS sub
FROM dbo.Sessions
UNION ALL
SELECT username,endtime AS ts, -1 AS type,0 AS sub
FROM dbo.Sessions
),
C2 AS
(
SELECT C1.*,
SUM(type) OVER(PARTITION BY username
ORDER BY ts,type DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) - sub AS cnt
FROM C1
),
C3 AS
(
SELECT username,ts,
FLOOR((ROW_NUMBER() OVER(PARTITION BY username
ORDER BY ts)-1)/2+1) AS grpnum
FROM C2
WHERE cnt=0
)
SELECT username,MIN(ts) AS starttime,MAX(ts) AS endtime
FROM C3
GROUP BY username,grpnum;
执行计划如下,而在我的笔记本上运行了13s:

类似于把针对单个用户的基于行号的解决方案的逻辑封装在内联表函数中,以及使用APPLY运算符对Users中的每个用户调用该函数,也可以对SUM窗口聚合采用同样的思路。下面是使用内联函数的代码:
-- 封装到函数
IF OBJECT_ID('dbo.UserIntervals2') IS NOT NULL
DROP FUNCTION dbo.UserIntervals2;
GO
CREATE FUNCTION dbo.UserIntervals2(@user AS VARCHAR(14)) RETURNS TABLE
AS
RETURN
WITH C1 AS
(
SELECT starttime AS ts, +1 AS type,1 AS sub
FROM dbo.Sessions
WHERE username = @user
UNION ALL
SELECT endtime AS ts, -1 AS type,0 AS sub
FROM dbo.Sessions
WHERE username = @user
),
C2 AS
(
SELECT C1.*,
SUM(type) OVER(ORDER BY ts,type DESC
ROWS BETWEEN UNBOUNDED PRECEDING
AND CURRENT ROW) - sub AS cnt
FROM C1
),
C3 AS
(
SELECT ts,
FLOOR((ROW_NUMBER() OVER(ORDER BY ts)-1)/2+1) AS grpnum
FROM C2
WHERE cnt=0
)
SELECT MIN(ts) AS starttime,MAX(ts) AS endtime
FROM C3
GROUP BY grpnum;
GO
查询代码如下:
--查询
SELECT U.username,A.starttime,A.endtime
FROM dbo.Users AS U
CROSS APPLY dbo.UserIntervals2(U.username) AS A;
执行计划如下,并在我的笔记本上执行了7s:

12、数据差距和数据岛
数据差距(Gap)和数据岛(Island)是经典的SQL问题,在实践中用多种形式来体现它们。其基本概念是,我们有一些数字、日期或时间值序列,其中序列值之间应该是有固定的间隔,但有些序列值可能会丢失。那么数据差距问题就是识别序列中缺失值的所有范围,数据岛问题涉及识别现有值的所有范围。为了演示找出数据差距和数据岛的技术,下面我们使用名为T1的表,该表的col1列为一个间隔为整数1的数字序列;另一个表为T2,该表的col1列为日期和时间序列,间隔为1天。代码如下:
--dbo.T1(numeric sequence with unique values,interval:1)
IF OBJECT_ID('dbo.T1','U') IS NOT NULL
DROP TABLE dbo.T1;
GO
CREATE TABLE dbo.T1
(
col1 INT NOT NULL PRIMARY KEY
);
GO
INSERT INTO dbo.T1(col1)
VALUES(2),(3),(7),(8),(11),(15),(16),(17),(28);
--dbo.T2(temporal sequence with unique values,interval: 1 day)
IF OBJECT_ID('dbo.T2','U') IS NOT NULL
DROP TABLE dbo.T2;
GO
CREATE TABLE dbo.T2
(
col1 DATE NOT NULL PRIMARY KEY
);
GO
INSERT INTO dbo.T2(col1) VALUES
('20120202'),
('20120203'),
('20120207'),
('20120208'),
('20120209'),
('20120211'),
('20120215'),
('20120216'),
('20120217'),
('20120228');12.1、数据差距
在SQL SERVER 2012 之前的版本,用来处理数据差距的技术工作量很大,有时还很复杂。但是随着引入LAG和LEAD函数,我们现在可以简单高效的处理这方面的需求。
针对T1的解决方案:
--数据差距 T1
WITH C AS
(
SELECT col1 AS cur, LEAD(col1) OVER(ORDER BY col1) AS nxt
FROM dbo.T1
)
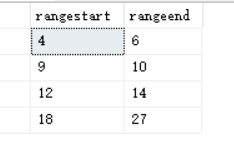
SELECT cur+1 AS rangestart,nxt-1 AS rangeend
FROM C
WHERE nxt-cur>1;
结果如下:
针对T2的解决方案:
--数据差距 T2
WITH C AS
(
SELECT col1 AS cur, LEAD(col1) OVER(ORDER BY col1) AS nxt
FROM dbo.T2
)
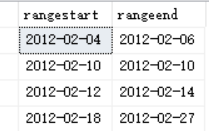
SELECT DATEADD(DAY,1,cur) AS rangestart, DATEADD(DAY,-1,nxt) AS rangeend
FROM C
WHERE DATEDIFF(DAY,cur,nxt)>1;
结果如下:
12.2、数据岛
针对T1的解决方案:
--数据岛 T1
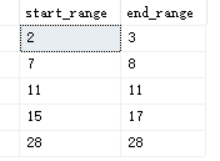
WITH C AS
(
SELECT col1,col1- DENSE_RANK() OVER(ORDER BY col1) AS grp
FROM dbo.T1
)
SELECT MIN(col1) AS start_range,MAX(col1) AS end_range
FROM C
GROUP BY grp;
结果如下:
执行计划如下:

也许你会奇怪,为什么我们使用DENSE_RANK函数,而不是ROW_NUMBER函数。这是因为需要支持那些不能保证序列值是唯一的情况。对于ROW_NUMBER函数,该技术只对当序列值是唯一的情况下有效(这恰好是样本数据的情况),但有重复时,它会失败。使用DENSE_RANK函数,该技术对唯一和非唯一的值都有效。
下面来看下针对T2的解决方案:
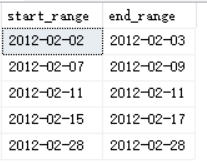
--数据岛 T2
WITH C AS
(
SELECT col1,DATEADD(DAY,-1* DENSE_RANK() OVER(ORDER BY col1),col1) AS grp
FROM dbo.T2
)
SELECT MIN(col1) AS start_range,MAX(col1) AS end_range
FROM C
GROUP BY grp;
结果如下:
有些情况下,我们需要使用这些数据岛技术,其中包括可用性报告、活动周期,以及其他技术。我们甚至可以使用这些数据岛技术来处理一个涉及打包日期间隔的经典问题。下面先来创建日期间隔表:
--创建日期间隔表
IF OBJECT_ID('dbo.Intervals','U') IS NOT NULL
DROP TABLE dbo.Intervals;
GO
CREATE TABLE dbo.Intervals
(
id INT NOT NULL,
starttime DATE NOT NULL,
endtime DATE NOT NULL
);
GO
INSERT INTO dbo.Intervals(id,starttime,endtime) VALUES
(1,'20120212','20120220'),
(1,'20120214','20120312'),
(1,'20120124','20120201');
解决方案如下:
--时间间隔 数据岛 解决方案
DECLARE
@from AS DATE ='20120101',
@to AS DATE = '20121231';
WITH Dates AS
(
SELECT DATEADD(DAY,n-1,@from) AS dt
FROM dbo.GetNums(1,DATEDIFF(DAY,@from,@to)+1) AS Nums
),
Groups AS
(
SELECT D.dt,
DATEADD(DAY,-1*DENSE_RANK() OVER(ORDER BY D.dt),D.dt) AS grp
FROM dbo.Intervals AS I
JOIN Dates AS D
ON D.dt BETWEEN I.starttime AND I.endtime
)
SELECT MIN(dt) AS rangestart,MAX(dt) AS endrange
FROM Groups
GROUP BY grp;
结果如下:

请注意,此解决方案对于时间间隔跨度很长的一段时间效果不是很好。该解决方案需要解开各个周期所涉及的个别日期,这是可以理解的。
还有比基本版本更加复杂的数据岛问题的版本。例如,假设忽略达到一定规模的数据差距——例如,数字序列,假设忽略达到2的差距。解决方案如下:
--数字序列,忽略大于2的差距 T1 数据岛 解决方案如下
WITH C1 AS
(
SELECT col1,
CASE WHEN col1 - LAG(col1) OVER(ORDER BY col1)
关注
打赏
最近更新
- 深拷贝和浅拷贝的区别(重点)
- 【Vue】走进Vue框架世界
- 【云服务器】项目部署—搭建网站—vue电商后台管理系统
- 【React介绍】 一文带你深入React
- 【React】React组件实例的三大属性之state,props,refs(你学废了吗)
- 【脚手架VueCLI】从零开始,创建一个VUE项目
- 【React】深入理解React组件生命周期----图文详解(含代码)
- 【React】DOM的Diffing算法是什么?以及DOM中key的作用----经典面试题
- 【React】1_使用React脚手架创建项目步骤--------详解(含项目结构说明)
- 【React】2_如何使用react脚手架写一个简单的页面?

