
目录
介绍
AdaBoost模型
弱分类器
权重更新
分类
结论与分析
可访问 实现机器学习的循序渐进指南系列汇总,获取本系列完成文章列表。
介绍AdaBoost是Boosting的一种方法,它基于多分类器组合可以在复杂环境中获得更准确结果的原则。
AdaBoost模型AdaBoost模型由弱分类器,权重更新和分类组成。
弱分类器AdaBoost将弱分类器与某些策略相结合,以获得强大的分类器,如下所示。在每次迭代中,错误分类的样本的权重将增加以捕获分类器“注意”。例如,在图(a)中,虚线是分类器平面,并且存在两个错误分类的蓝色样本和一个红色样本。然后,在图(b)中,增加了两个蓝色样本和一个红色样本的权重。在每次迭代时调整权重后,我们可以组合所有弱分类器以获得最终的强分类器。

在每次迭代时有两种类型的权重要更新,即每个样本![]() 的权重和每个弱分类器
的权重和每个弱分类器![]() 的权重。一开始,初始化如下:
的权重。一开始,初始化如下:
![]()
![]()
其中N, M分别是样本数和弱分类器数。
AdaBoost在每次迭代中训练一个弱分类器,表示![]() 其训练误差计算为
其训练误差计算为
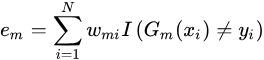
然后,通过更新弱分类器的权重
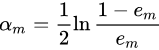
更新样本的权重
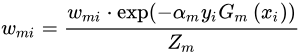
其中
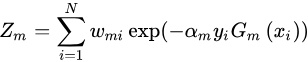
形成上述等式,我们可以得出结论
1.训练误差是错误分类样本的权重之和
2.当e m小于0.5,am 大于0,这意味着较低的训练误差的弱分类具有
弱分类器在最终分类器中扮演的更重要的角色。
3.权重更新可写为
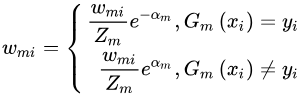
这意味着正确的分类样本的权重减少,而错误的分类样本的权重增加。
AdaBoost的训练流程代码如下所示
def train(self, train_data, train_label):
if self.norm_type == "Standardization":
train_data = preProcess.Standardization(train_data)
else:
train_data = preProcess.Normalization(train_data)
train_label = np.expand_dims(train_label, axis=1)
sample_num = len(train_data)
weak_classifier = []
# initialize weights
w = np.ones([sample_num, 1])
w = w/sample_num
# predictions
agg_predicts = np.zeros([sample_num, 1]) # aggregate value of prediction
# start train
for i in range(self.iterations):
base_clf, error, base_prediction = self.baseClassifier(train_data, train_label, w)
alpha = self.updateAlpha(error)
weak_classifier.append((alpha, base_clf))
# update parameters in page of 139 Eq.(8.4)
expon = np.multiply(-1 * alpha * train_label, base_prediction)
w = np.multiply(w, np.exp(expon))
w = w/w.sum()
# calculate the total error rate
agg_predicts += alpha*base_prediction
error_rate = np.multiply(np.sign(agg_predicts) != train_label, np.ones([sample_num, 1]))
error_rate = error_rate.sum()/sample_num
if error_rate == 0:
break
self.classifier_set = weak_classifier
return weak_classifier结合所有弱分类器以获得强分类器。分类规则是每个弱分类结果的加权和,由下式给出
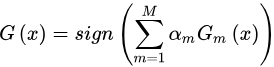
AdaBoost可以作为使用前向步进算法的指数损失函数的加法模型。在AdaBoost中,弱分类器的类型可以不同或相同。在本文中,我们使用5个SVM分类器作为弱分类器,检测性能如下所示:

它可以是精度提高约5%,运行时间约为单个SVM的5倍。
可以在MachineLearning中找到本文中的相关代码和数据集 。
有兴趣的小伙伴可以查看上一篇或者下一篇。
原文地址:https://www.codeproject.com/Articles/4114375/Step-by-Step-Guide-to-Implement-Machine-Learning

