
目录
在ML工作区中附加Kubernetes集群
在启用Arc的Kubernetes集群上训练ML模型
在Azure中注册模型
下一步
- 下载源 - 2.4 MB
在本系列的第一篇文章中,我们将本地Kubernetes集群连接到Azure Arc。本文介绍如何使用在Arc管理的本地Kubernetes集群上运行的Azure机器学习(AML)来训练模型。
您可以在GitHub上查看完整的项目代码。
在ML工作区中附加Kubernetes集群要在启用Arc的集群上运行ML工作负载,我们必须将Kubernetes集群附加到Azure中的ML工作区。我们首先在Azure门户中创建一个AML资源。
我们可以登录Azure门户,在市场中搜索机器学习。在机器学习页面上,我们单击创建。
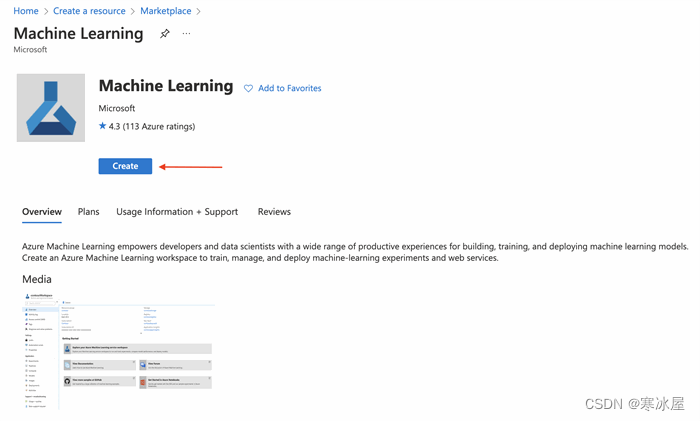
在下一页上,我们选择一个资源组并指定工作区的名称和区域。完成后,我们点击Review + create。
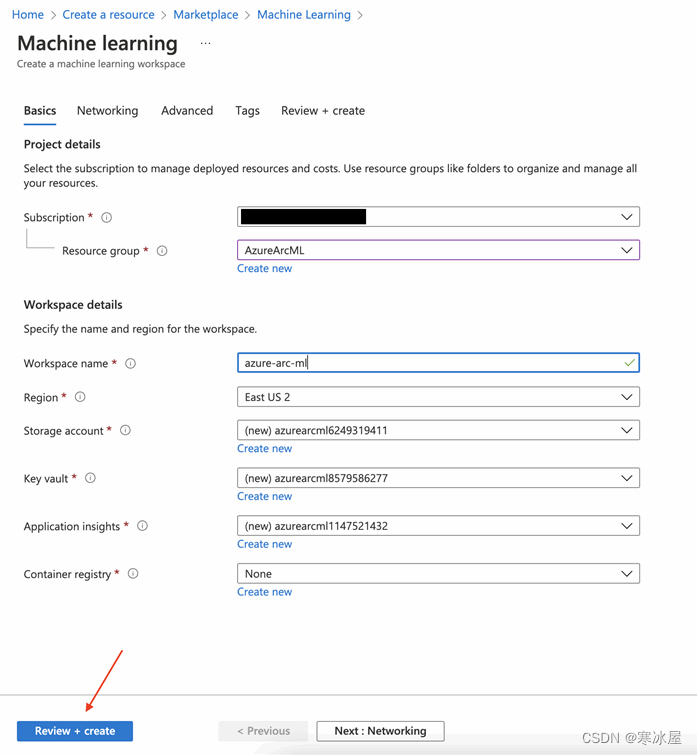
验证指定的设置需要几秒钟。完成后,我们单击Create。
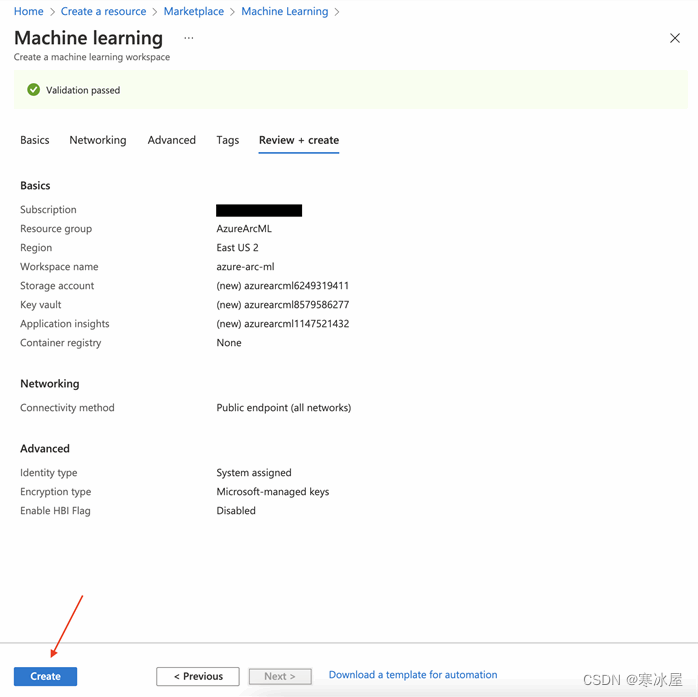
部署完成后,我们转到资源。
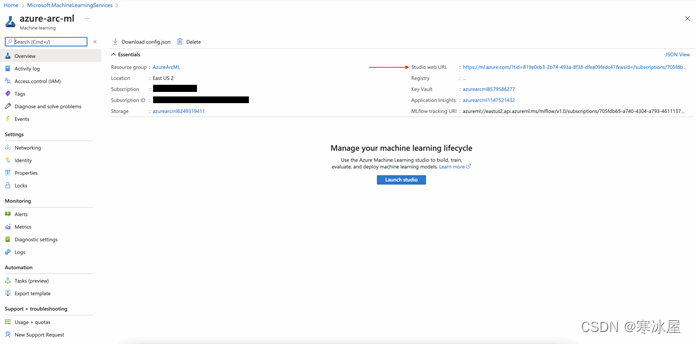
在这里,连同其他配置,我们还可以看到AML工作室的URL。我们点击链接启动工作室。
然后,在工作室中,我们点击左侧菜单中的计算。
在AML工作室中制作和运行笔记本之前,我们必须创建一个计算实例。在计算实例下,我们单击新建。
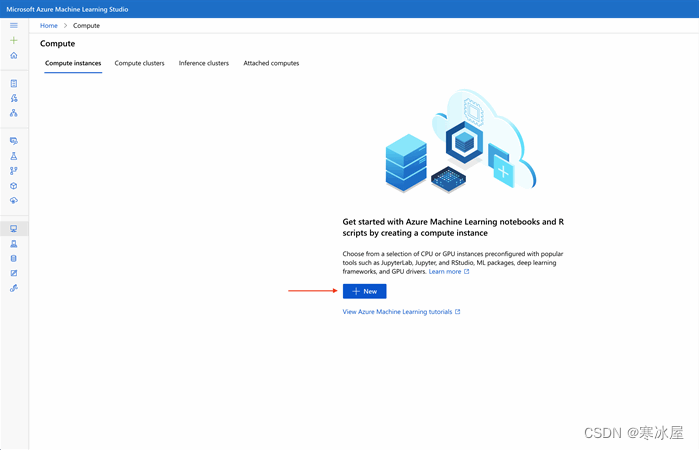
我们在下一页输入计算名称并指定要求。完成后,我们单击Create。
Azure只需几秒钟即可部署计算实例。
下一步是将我们的Kubernetes集群附加到ML工作区。我们导航到Attached computes,单击New,然后从菜单中选择Kubernetes(预览版) 。
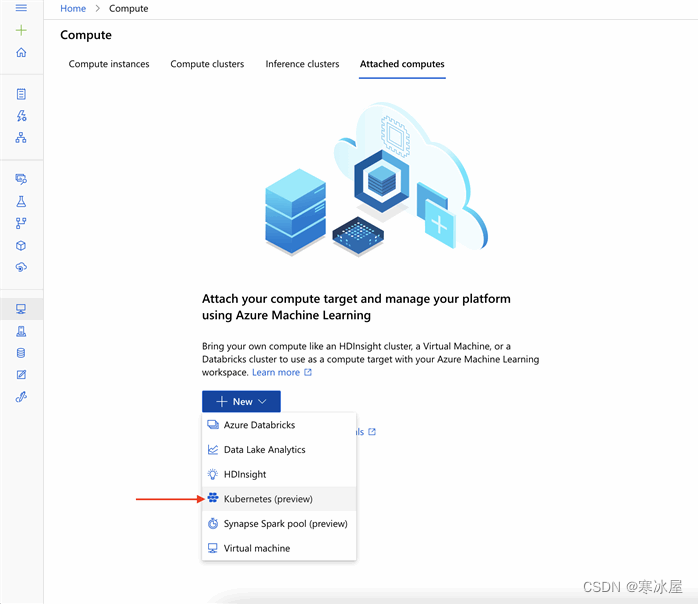
我们在下一页为我们的计算机输入一个名称,然后从列表中选择我们的Kubernetes集群。此外,我们必须将Assign a managed identity设置为System-assigned。完成后,我们点击Attach。
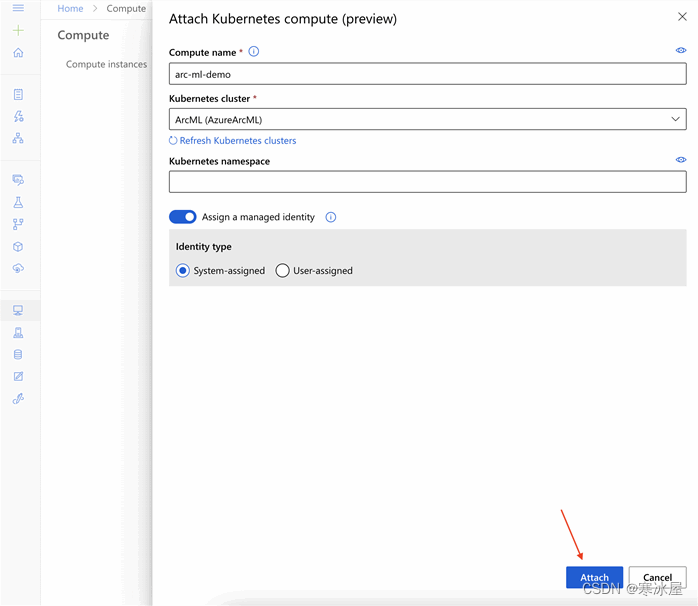
完成后,我们会在Attached computes下看到我们附加的Kubernetes集群。现在我们都准备好使用AML训练我们的模型了。
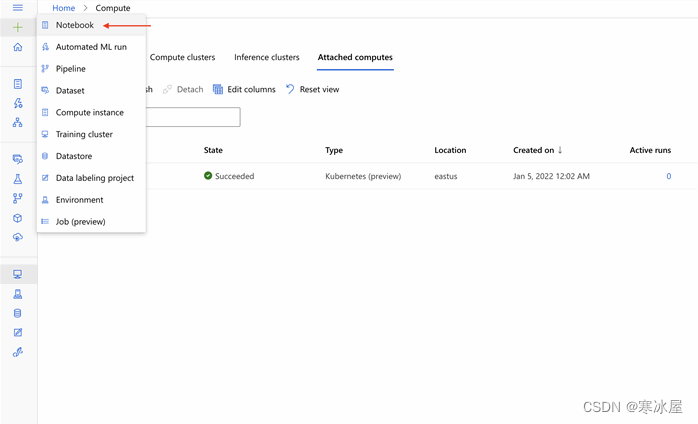
在启用Arc的Kubernetes集群上训练ML模型在AML studio中,我们点击左上角的加号(+),然后点击Notebook。
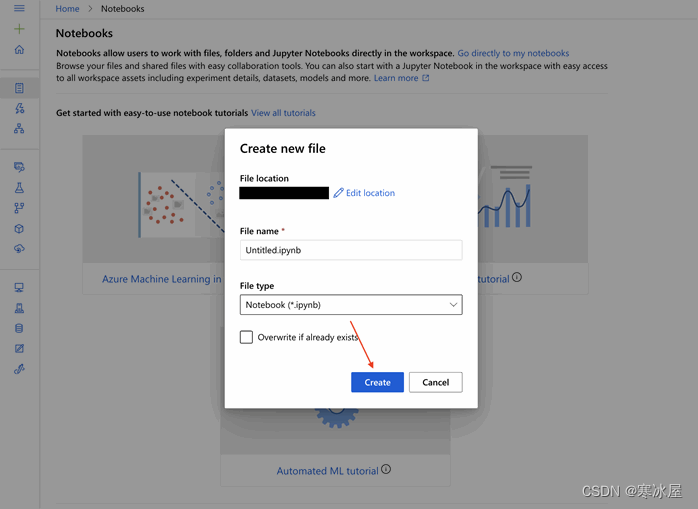
我们在下一页指定文件位置、名称和类型,然后单击Create。
现在,我们将在fashion-mnist 数据集上训练一个经典的图像分类模型。
在开始训练模型之前,我们必须连接到我们的ML工作区。输入以下代码以连接到AML工作区:
# Connect to Azure Machine Learning Workspace
import azureml.core
from azureml.core import Workspace
ws = Workspace.from_config()然后,我们将创建一个脚本文件夹来保存与我们的机器学习模型相关的所有脚本。
# Create script folder
import os
script_folder = os.path.join(os.getcwd(), 'script')
os.makedirs(script_folder, exist_ok=True)这段代码完成后,我们会在Users > {$username}下看到脚本目录。
接下来,我们必须为我们的图像分类问题创建一个ML模型。以下代码在脚本文件夹中创建一个名为train.py的文件,其中包含用于训练和测试我们的分类模型的所有方法。
%%writefile script/train.py
import os
import time
import azureml
import argparse
import numpy as np
import tensorflow as tf
from tensorflow import keras
from keras import backend as K
from keras import utils, losses
from keras.models import Sequential
from azureml.core import Workspace, Run
from keras.layers import Conv2D, MaxPooling2D
from keras.layers import Dense, Dropout, Flatten
os.environ["TF_CPP_MIN_LOG_LEVEL"]= "2"
os.environ['KERAS_BACKEND'] = 'tensorflow'
#Fashion MNIST Dataset CNN model development: https://github.com/zalandoresearch/fashion-mnist
from keras.datasets import fashion_mnist
parser = argparse.ArgumentParser()
parser.add_argument('--data-folder', type=str, dest='data_folder', help='data folder mounting point')
args = parser.parse_args()
#load training and testing data
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
print(x_train.shape, y_train.shape, x_test.shape, y_test.shape, sep = '\n')
# Define the labels
fashion_mnist_labels = ["Top",
"Trouser",
"Jumper",
"Dress",
"Coat",
"Sandal",
"Shirt",
"Trainer",
"Bag",
"Ankle boot"]
#data pre-processing
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
y_train = utils.to_categorical(y_train, num_classes)
y_test = utils.to_categorical(y_test, num_classes)
#formatting issues for image depth (greyscale = 1) with different kernels (tensorflow, cntk, etc)
if K.image_data_format()== 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 1, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0],1,img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols,1)
x_test = x_test.reshape(x_test.shape[0],img_rows, img_cols,1)
input_shape = (img_rows, img_cols,1)
# declare variables for model training
num_classes = 10
batch_size = 128
epochs = 10
img_rows,img_cols = 28,28
# model for image classification
model = Sequential()
model.add(Conv2D(64, kernel_size=(3,3), padding = 'same', activation = 'relu', input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.2))
model.add(Conv2D(32, kernel_size=(3,3), padding = 'same', activation = 'relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(num_classes, activation='softmax'))
model.summary()
# start an Azure ML run
run = Run.get_context()
# training the deep learning model
model.compile(loss=losses.categorical_crossentropy, optimizer="Adam", metrics=['accuracy'])
hist = model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(x_test, y_test))
# evaluate the model performance on test data
print('Predict the test set')
result = model.evaluate(x_test, y_test, verbose=0)
print('Test Loss: ', result[0])
print('Test Accuracy: ', result[1])
# calculate accuracy on the prediction
print('Accuracy is', result[1])
os.makedirs('outputs/model', exist_ok=True)
# save trained model
model.save('outputs/model/model.h5')在这段代码中,我们从Keras数据集中加载fashion-mnist数据。该fashion-mnist数据集包含60,000个用于训练的示例和一个包含10,000个与来自10个类的标签相关的示例的测试集。一旦我们成功加载数据,我们就会对图像进行归一化并格式化图像深度。
在对数据进行预处理后,我们创建了一个用于图像分类的序列模型。该模型由两个2D卷积层组成,每个卷积层后跟一个最大池化2D层。神经网络模型也使用一个softmax函数作为多类分类的激活函数。
接下来,我们开始运行Azure机器学习,分别用于训练和评估训练数据和验证数据的数据。模型训练完成后,我们将其保存以备将来使用。
脚本到位后,下一步是附加启用Arc的Kubernetes计算,如下所示:
# Get attached Arc-enabled kubernetes compute
arc_compute = ws.compute_targets["arc-ml-demo"]上面的代码将计算目标设置为我们附加的Kubernetes集群。
最后,让我们运行ML工作负载。
from azureml.core import Experiment
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
from azureml.core import ScriptRunConfig
# Register environment to re-use later
env = Environment('test')
conda_dep = packages = CondaDependencies.create(conda_packages=['pip', 'tensorflow', 'keras', 'scikit-learn'],
pip_packages=['azureml-defaults'])
env.python.conda_dependencies = conda_dep
env.register(workspace = ws)
# reference the data
datastore = ws.get_default_datastore()
data_ref = datastore.path('./data').as_mount()
src = ScriptRunConfig(source_directory=script_folder,
script='train.py',
arguments=['--data-folder', str(data_ref)],
compute_target=arc_compute,
environment=env)
# Run the experiment
src.run_config.data_references = {data_ref.data_reference_name: data_ref.to_config()}
run = Experiment(workspace=ws, name='fashion-mnist').submit(src)
run.wait_for_completion(show_output=True)在这段代码中,我们首先注册环境并为我们的环境定义依赖项。我们还将当前ML工作区注册到环境中。由于我们从Keras数据集中加载数据,因此我们必须创建一个data_ref对象来引用默认数据存储中的数据。为了在AML中提交运行,我们将配置信息(包括脚本、计算目标和环境)打包到ScriptRunConfig类的实例中。接下来,我们提交这些配置并在Azure中启动ML加载。
模型开始训练后,它会提供一个Web链接来查看其训练进度。此链接使我们能够始终如一地查看和提取历史记录、指标和模型。一旦我们的模型完成训练,我们应该会看到与该图像类似的输出:
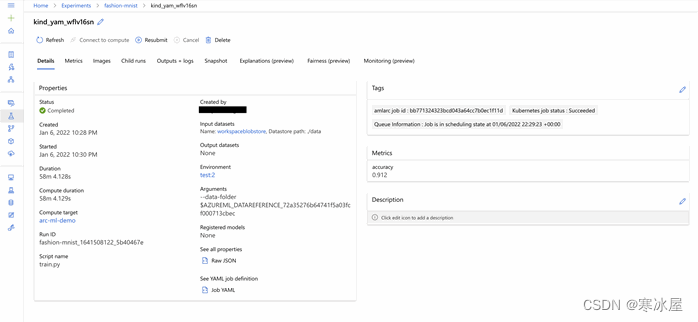
我们还可以按如下方式检查模型的性能:
print(run.get_metrics())我们的模型已经完成了训练,并报告了91%的准确率。既然结果是值得的,我们可以在Azure中注册这个模型。
在Azure中注册模型当我们向Azure注册模型时,Azure会将其上传到我们工作区的默认存储帐户,我们可以将其挂载到任何地方。当我们想要创建一个返回模型预测的后端系统时,这种方法很有用。注册后,我们可以下载或部署注册的模型。
Azure默认将输出文件夹中的文件上传到实验记录中。由于我们将训练好的模型保存在输出文件夹中,因此它应该在实验记录中。我们可以从那里注册我们的模型。在注册之前,让我们验证我们的模型是否在所需的文件夹中。
# get files in experiment record
print(run.get_file_names())上面这行代码输出了记录中所有文件的名称。我们还应该看到model.h5文件,在我们的例子中,它位于输出/模型文件夹中。
接下来,我们注册这个模型如下:
# register model
model = run.register_model(model_name='fashion-mnist-tf', model_path='outputs/')
print(model.name, model.id, model.version, sep = '\t')上述代码成功执行后,我们应该会在Azure中看到我们的模型。
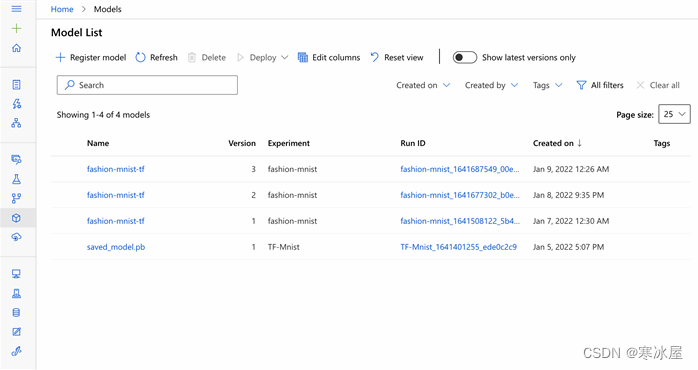
我们还可以将训练模型的副本下载到我们的本地系统并用于推理。
下一步本文将我们本地托管、启用Arc的Kubernetes集群附加到AML工作区,并使用它来训练经典图像分类模型。继续阅读以下文章,我们将在其中学习使用支持Azure Arc的ML在任何地方部署模型和启用推理。
若要详细了解如何配置Azure Kubernetes服务(AKS)和启用Azure Arc的Kubernetes集群以训练和推理机器学习工作负载,请查看配置Kubernetes集群以进行机器学习。
https://www.codeproject.com/Articles/5323949/Azure-Arc-Machine-Learning-Part-2-Training-Machine

