
目录
问题和数据集
先决条件
下载MNIST数据集
为ML准备Visual Studio代码
准备Azure ML工作区
将数据集上传到机器学习工作区
选择计算选项
准备培训代码
确定培训工作的环境
开始模型训练
下一步
本文展示了使用XGBoost创建和训练模型,然后在Azure ML上运行模型训练的代码。随后将进行简短的演示,以表明经过训练的模型可以按预期工作。
很难错过机器学习(ML)和数据科学的日益普及和流行。这种趋势是Python大受欢迎的最大驱动力之一。截至2021年,Python语言正式比Java、C#或C++等成熟的老前辈更受欢迎。它在11月的TIOBE指数中排名第一,在Stack Overflow的2021年开发者调查中,它是第三受欢迎的编程语言。当您想到机器学习代码时,您很可能会想到Python。
您可以在几乎所有设备上运行Python代码:PC、Mac或Raspberry Pi,配备x86、x86-64、AMD64或ARM/ARM64处理器,以及Windows、Linux或macOS操作系统。但是,机器学习通常需要强大的处理能力,这可能会超过您在特定时刻拥有的任何计算机的能力。Azure是运行几乎任何规模的基于Python的ML工作负载的好地方。
在这个由三部分组成的系列中,我们将介绍几种在Azure上的Python中创建和使用机器学习模型的方法。您可以在GitHub上找到本文的示例代码。
我们将首先使用带有Azure机器学习服务的XGBoost库来训练和测试模型。而且,我们将在不离开Visual Studio Code的情况下(几乎)完成所有工作,以使事情变得更加精简。
问题和数据集本教程将使用著名的MNIST数据集来训练模型以识别手写数字。我们不会依赖该数据集的现成版本来提高相关性,即使它在许多框架中都可用。相反,我们以一种您可以适应您选择的任何图像分类任务的方式使用它。
先决条件要遵循本文中的示例,您需要Visual Studio Code、最新的Python版本和用于Python包管理的Conda。如果您没有其他偏好,请从Miniconda和Python 3.9开始。
安装Python和Conda后,创建并激活一个新环境:
$ conda create -n azureml python=3.9
$ conda activate azureml此外,您需要一个Azure订阅。如果您还没有Azure帐户,请注册一个免费帐户。
下载MNIST数据集首先从Microsoft的Azure Open Datasets下载MNIST数据集:
import os
import urllib.request然后,将以下代码保存在名为download-dataset.py的文件中:
DATA_FOLDER = 'datasets/mnist-data'
DATASET_BASE_URL = 'https://azureopendatastorage.blob.core.windows.net/mnist/'
os.makedirs(DATA_FOLDER, exist_ok=True)
urllib.request.urlretrieve(
os.path.join(DATASET_BASE_URL, 'train-images-idx3-ubyte.gz'),
filename=os.path.join(DATA_FOLDER, 'train-images.gz'))
urllib.request.urlretrieve(
os.path.join(DATASET_BASE_URL, 'train-labels-idx1-ubyte.gz'),
filename=os.path.join(DATA_FOLDER, 'train-labels.gz'))
urllib.request.urlretrieve(
os.path.join(DATASET_BASE_URL, 't10k-images-idx3-ubyte.gz'),
filename=os.path.join(DATA_FOLDER, 'test-images.gz'))
urllib.request.urlretrieve(
os.path.join(DATASET_BASE_URL, 't10k-labels-idx1-ubyte.gz'),
filename=os.path.join(DATA_FOLDER, 'test-labels.gz'))您可以使用以下命令运行代码:
$ python download-dataset.pyAzure机器学习是用于端到端ML生命周期的云服务和工具的集合。为了更轻松地在Visual Studio Code中使用它,我们可以使用新的专用扩展。
首先,单击Visual Studio Code边栏中的扩展图标。
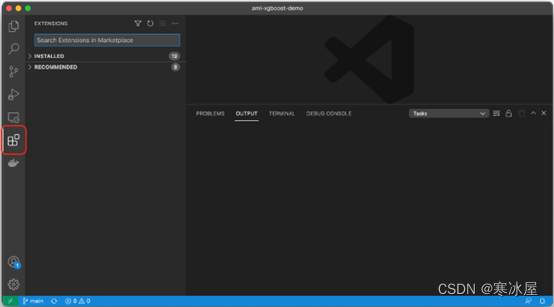
现在,搜索并安装Azure机器学习扩展。
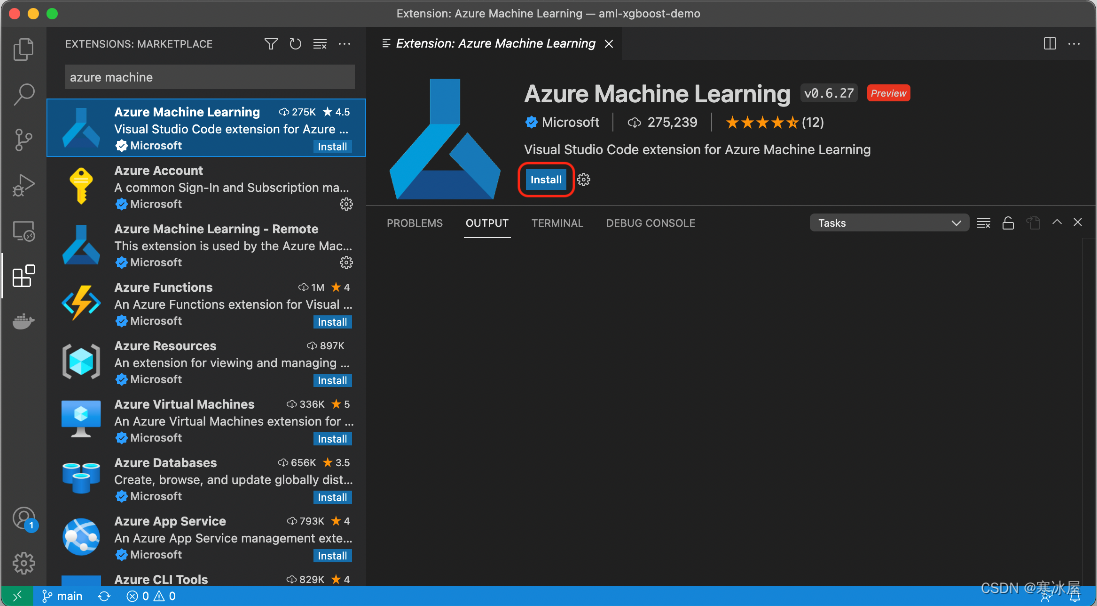
安装并激活扩展后(这可能需要重新启动Visual Studio Code),边栏中会出现一个新的Azure图标。
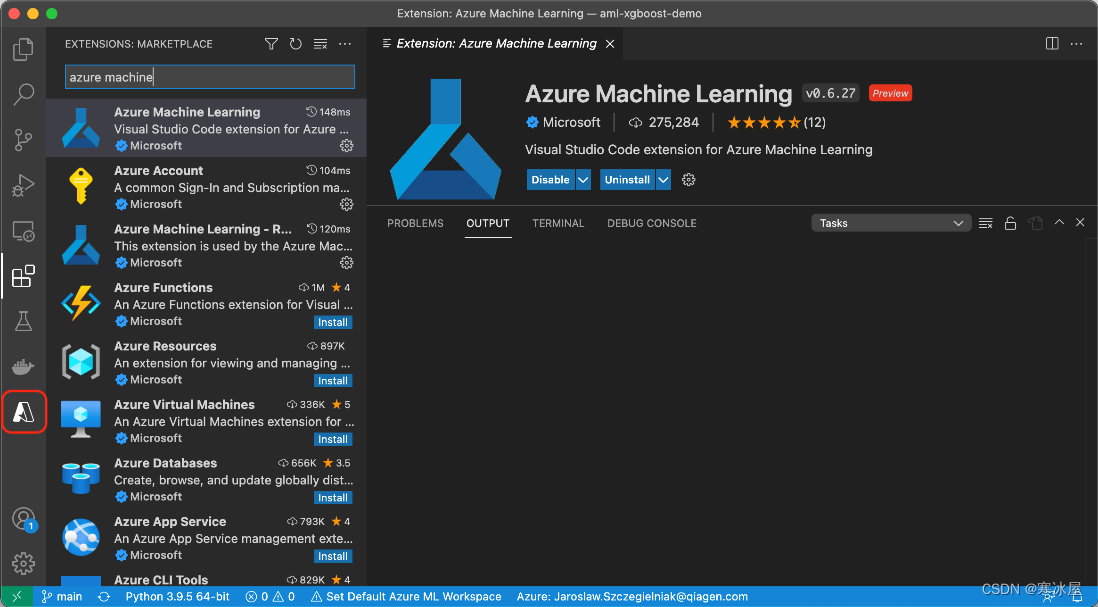
此外,我们需要版本大于或等于2.15.0的Azure命令行工具(azure-cli )及其机器学习扩展。在撰写本文时,它是2.0.2版。要使用这些工具,请输入以下内容:
$ az extension add -n ml -y现在我们可以开始配置我们的Azure资源了。首先,我们需要Azure:机器学习工作区。接下来,我们创建一个数据集、一个计算集群来处理工作,以及工作区内的训练工作。
我们使用已安装的Azure机器学习扩展来开始设置Azure。
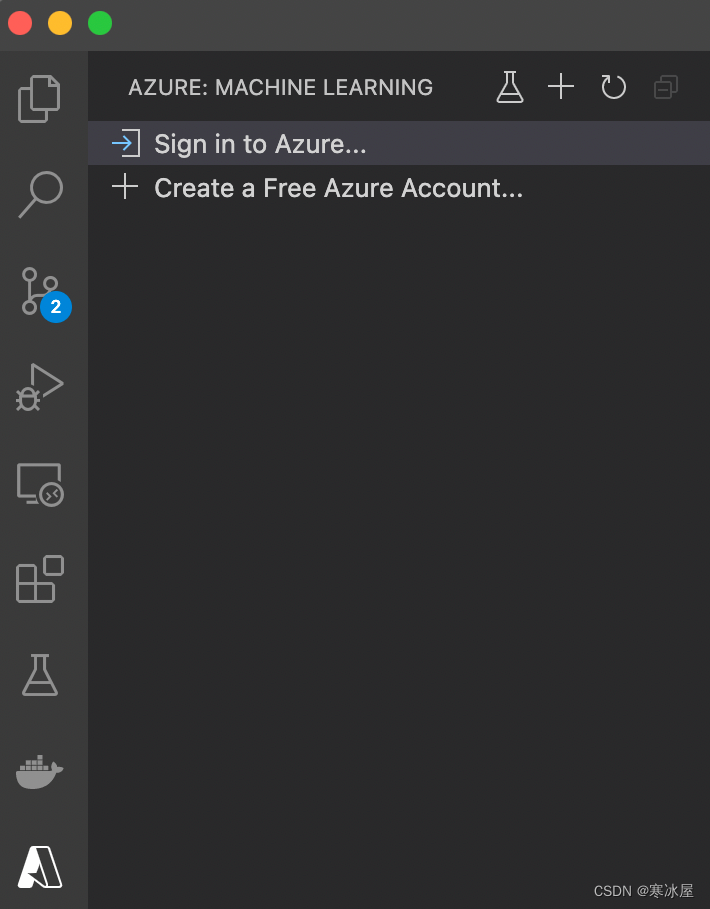
登录到Azure帐户(或创建新帐户)后,我们会看到订阅的名称和创建(机器学习)工作区的选项:
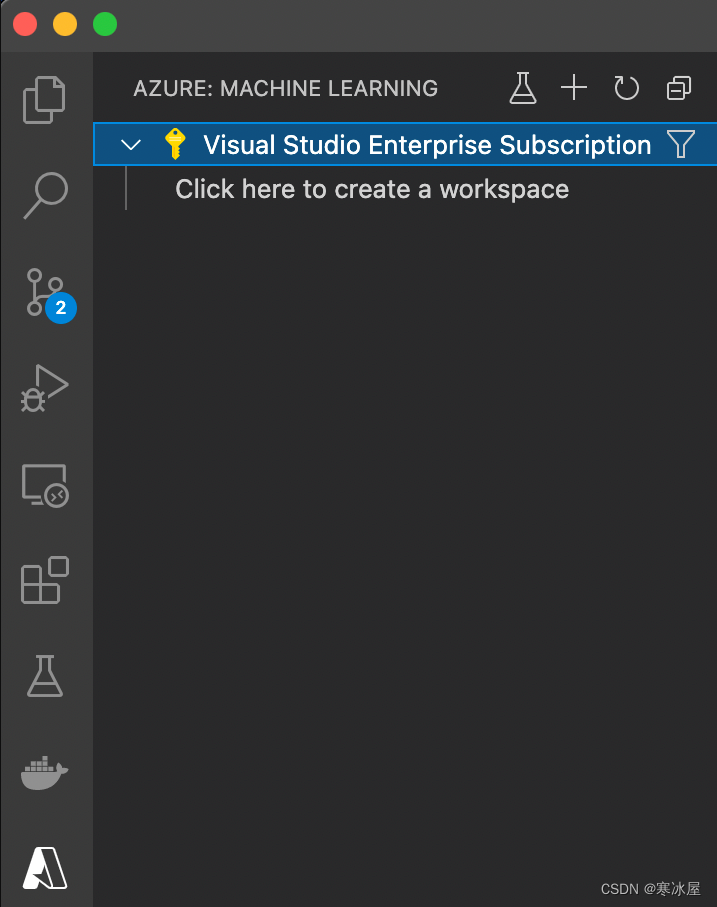
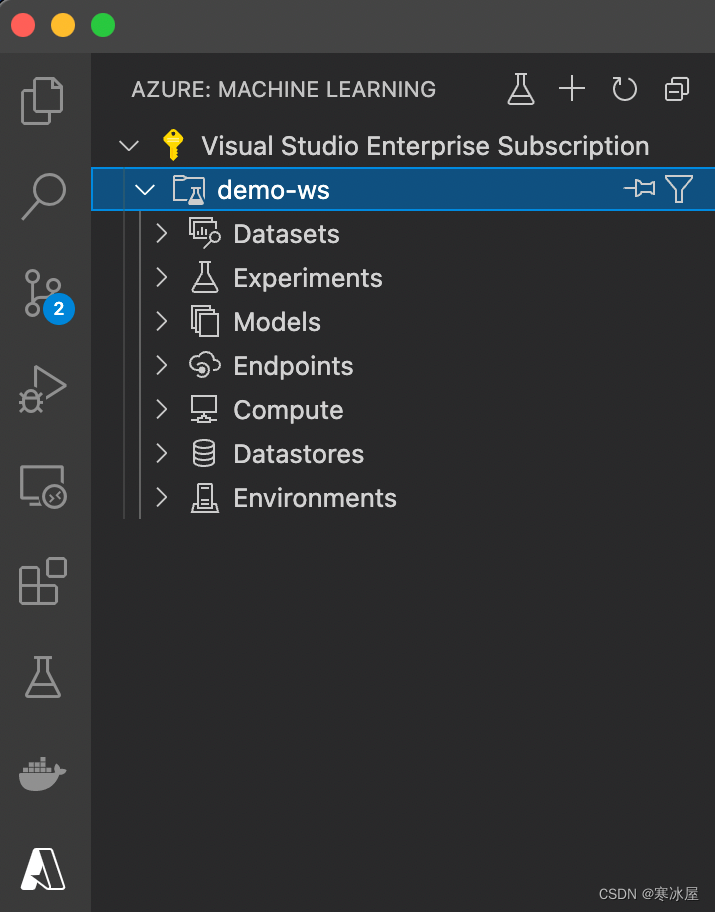
对于此示例,在距离您最近的位置的名为azureml-rg的新资源组中创建一个名为demo-ws的新工作区。在这里,我们选择了西欧。成功创建后,工作区应该在我们的订阅下方可见:
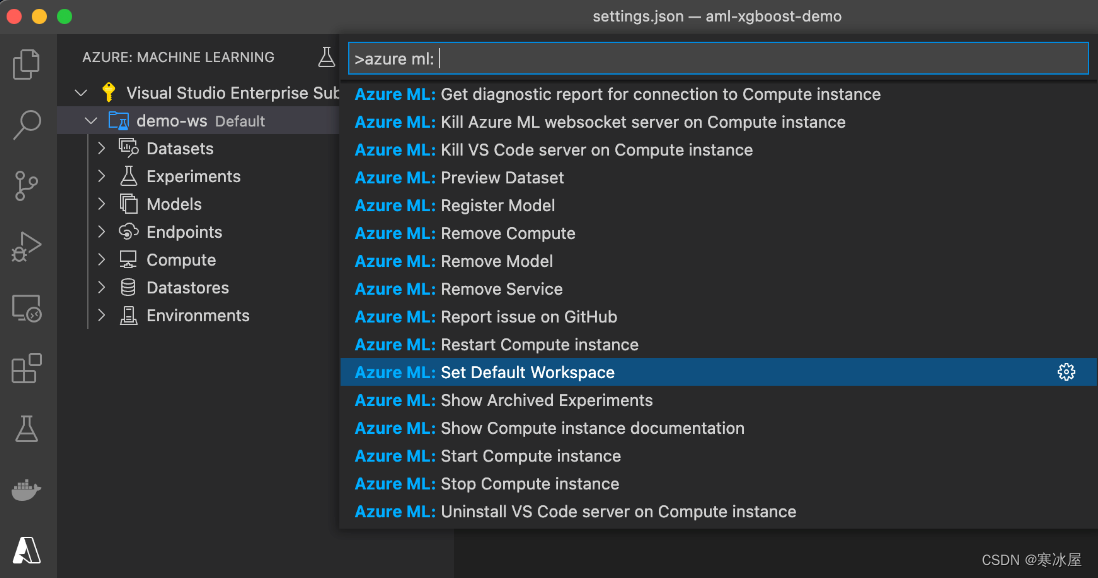
我们第一次尝试对Azure机器学习扩展进行任何操作时,Visual Studio Code会要求我们选择一个默认工作区:

不要忽视提示。如果没有默认工作区,大多数机器学习扩展功能将无法工作,而且我们有时只会收到有意义的错误消息。如果您错过了提示,您始终可以手动设置默认工作区。设置默认值的一种方法是使用Cmd/Ctrl+Shift+P,然后选择Azure ML:设置默认工作区命令:
或者,您可以在.vscode/settings.json文件中设置默认工作区:
{
"azureML.defaultWorkspaceId": "/subscriptions/
/resourceGroups/azureml-rg/providers/Microsoft.MachineLearningServices/workspaces/demo-ws"
}在某些情况下,您可能需要重新启动Visual Studio Code才能使此更改生效(毕竟扩展仍处于预览状态)。
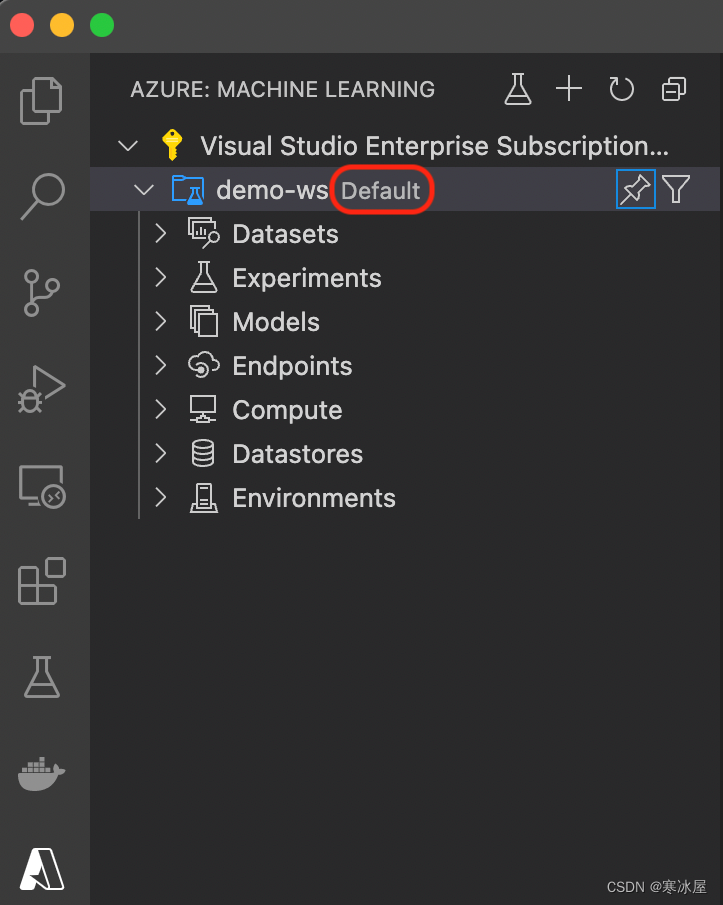
选择默认工作区后,您可以在Azure:机器学习扩展列表中看到它:
现在我们可以开始使用我们的工作区了。在任何机器学习项目中,我们首先需要的是数据。在Azure:机器学习工作区中处理数据的首选方式是将其注册为数据集。
使用Visual Studio Code扩展单击demo-ws工作区的Datasets节点,然后单击加号(+)。作为响应,Azure机器学习扩展会生成一个数据集定义模板。
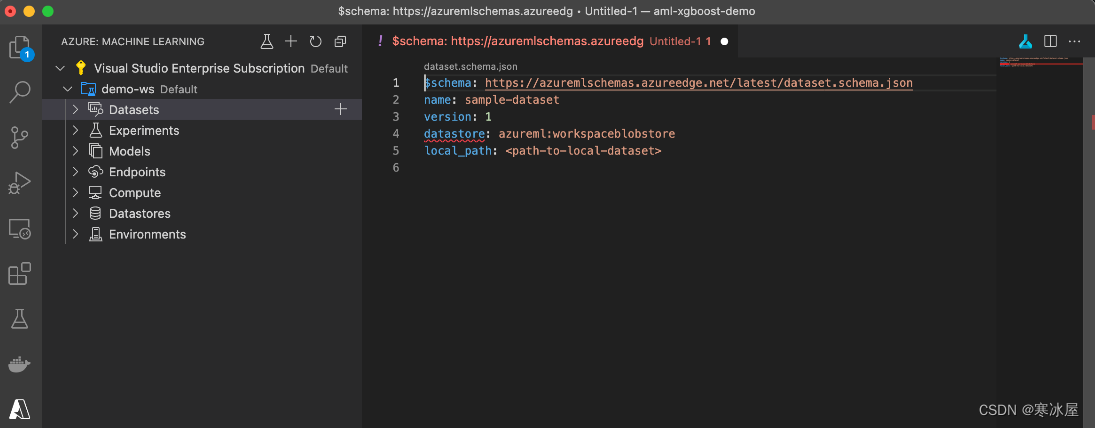
自动生成的模板与已接受的架构不兼容,后者不再支持数据存储属性。不幸的是,我们在使用预览代码时可能需要面对这个问题。但是,我们可以轻松创建适当的数据集定义,将我们之前下载的数据集文件上传到Azure:机器学习。
aml- mnist -dataset.yml文件应包含以下内容:
$schema: https://azuremlschemas.azureedge.net/latest/dataset.schema.json
name: mnist-dataset
version: 1
local_path: datasets/mnist-data现在,如果我们单击右上角的小图标(在下面的屏幕截图中的红色矩形中),Azure机器学习扩展应该会自动生成并执行正确的azure-cli命令:
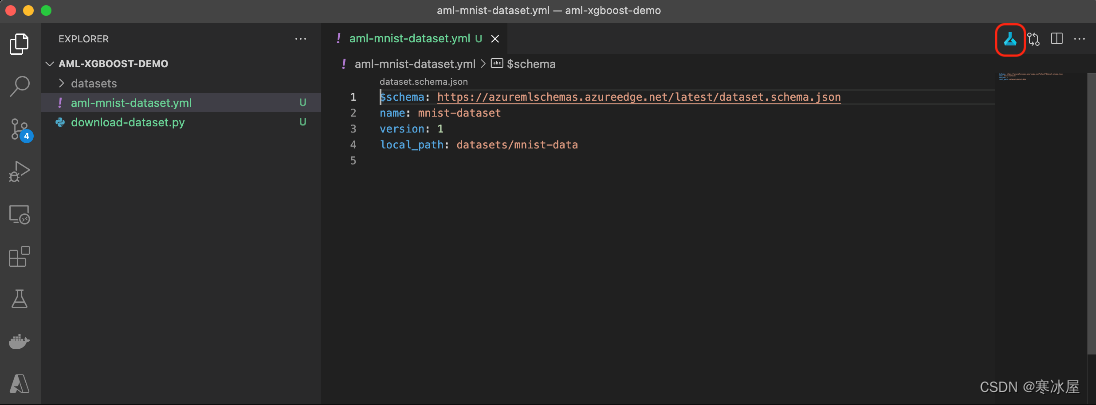
如果它不起作用,请确保您已设置默认Azure:机器学习工作区。此处的错误消息可能含糊不清。或者,您始终可以直接使用Azure CLI:
$ export SUBSCRIPTION=""
$ export GROUP="azureml-rg"
$ export WORKSPACE="demo-ws"
$ az ml dataset create --file aml-mnist-dataset.yml --subscription $SUBSCRIPTION
--resource-group $GROUP --workspace-name $WORKSPACE除了数据,我们还需要计算资源来运行我们的训练代码。如果我们在demo-ws工作区中展开Compute节点,我们可以看到几个选项:计算实例、计算集群、推理集群和附加计算机。
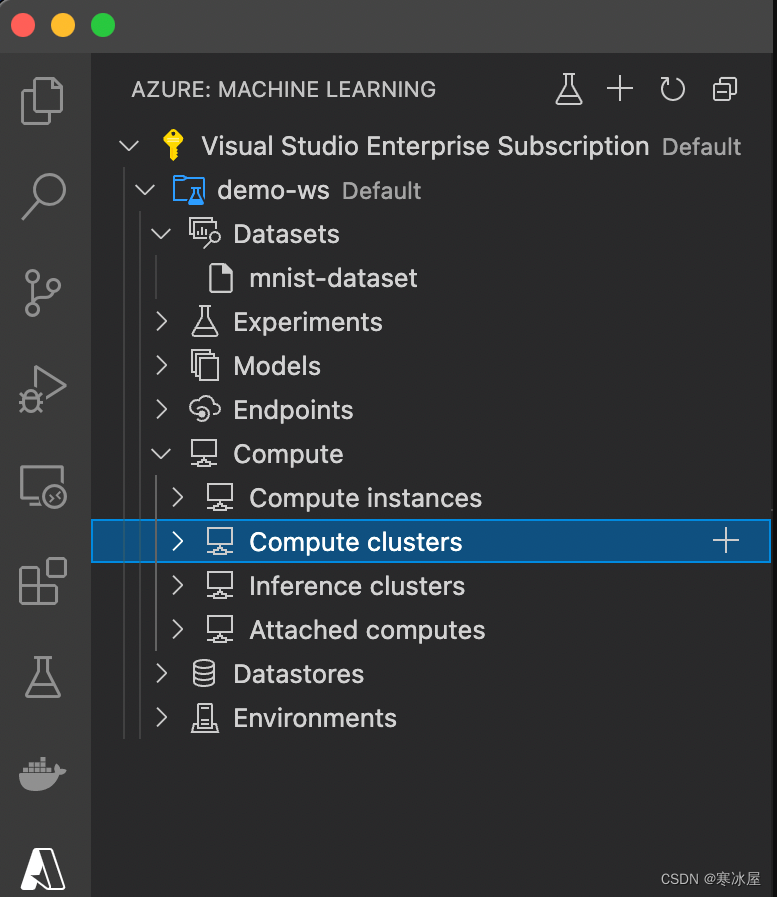
我们使用计算实例来运行完整的实验环境——例如,在JupyterLab中使用Jupyter笔记本。我们将在 本系列的第三篇文章中使用其中一个。
我们可以使用推理集群来处理对训练和保存模型的预测。连接的计算机允许使用现有Azure资源,而不是创建新资源。我们没有任何现有资源(VM、HDInsight、Databricks或Kubernetes集群),因此我们将创建一个新的计算集群。此类集群可以根据当前需求动态扩展和缩减。这是一个有用的功能,让我们只需为所需的计算资源付费。
如果我们单击Compute clusters节点右侧的加号(+) ,我们会创建一个相对较短且不是很有帮助的模板:
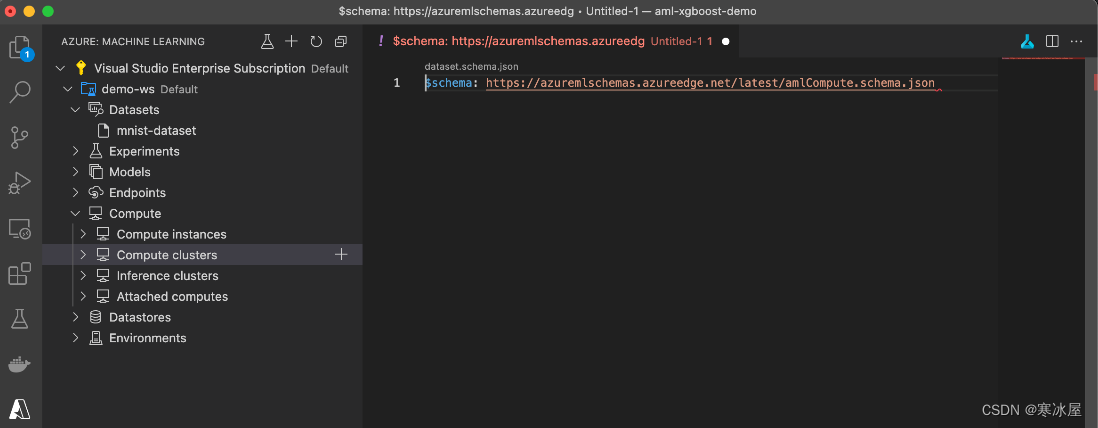
幸运的是,对引用的JSON模式的简短研究以及AmlCompute类文档使我们能够填写它:
$schema: https://azuremlschemas.azureedge.net/latest/compute.schema.json
name: ami-comp-cpu-01
type: amlcompute
size: Standard_DS3_v2
min_instances: 0
max_instances: 1
idle_time_before_scale_down: 3600
location: westeurope您可以选择您的值,例如名称、大小、实例数等。在上面的示例中,我们确保最多运行单个且相对较小的虚拟机。这对我们的目的来说已经绰绰有余了,但您可能需要从更大型号的可用尺寸中选择更重要的东西。
和数据集一样,如果点击右上角的蓝色符号不起作用,我们可以直接使用Azure CLI。如果我们将计算定义保存到aml-compute-cpu.yml文件中,则命令应如下所示:
$ az ml compute create --file aml-compute-cpu.yml --subscription $SUBSCRIPTION
--resource-group $GROUP --workspace-name $WORKSPACE不必担心Azure成本。只要您让min_instances变量等于0,运行此脚本只会创建计算定义,而不是计算VM本身。
准备培训代码配置好数据集和计算后,我们终于可以准备训练代码了。我们将训练代码存储在code/train.py文件中。
通常,我们从导入开始:
import os
import argparse
import gzip
import struct
import mlflow
import numpy as np
from azureml.core import Run
from azureml.core.model import Model
import xgboost as xgb
from sklearn.metrics import accuracy_score然后,我们定义帮助方法来处理Azure:机器学习工作区和参数解析。在我们的例子中,我们只有一个参数,data,它包含我们数据集文件的路径:
def get_aml_workspace():
run = Run.get_context()
ws = run.experiment.workspace
return ws
def parse_arguments():
parser = argparse.ArgumentParser()
parser.add_argument('--data', type=str, required=True)
args = parser.parse_known_args()[0]
return args现在,我们可以定义数据集加载方法。此方法是特定于数据集的,我们主要从Azure开放数据集 示例中借用它。当然,在使用自己的数据时需要替换它。
def load_dataset(dataset_path):
def unpack_mnist_data(filename: str, label=False):
with gzip.open(filename) as gz:
struct.unpack('I', gz.read(4))
n_items = struct.unpack('>I', gz.read(4))
if not label:
n_rows = struct.unpack('>I', gz.read(4))[0]
n_cols = struct.unpack('>I', gz.read(4))[0]
res = np.frombuffer(gz.read(n_items[0] * n_rows * n_cols), dtype=np.uint8)
res = res.reshape(n_items[0], n_rows * n_cols) / 255.0
else:
res = np.frombuffer(gz.read(n_items[0]), dtype=np.uint8)
res = res.reshape(-1)
return res
X_train = unpack_mnist_data(os.path.join(dataset_path, 'train-images.gz'), False)
y_train = unpack_mnist_data(os.path.join(dataset_path, 'train-labels.gz'), True)
X_test = unpack_mnist_data(os.path.join(dataset_path, 'test-images.gz'), False)
y_test = unpack_mnist_data(os.path.join(dataset_path, 'test-labels.gz'), True)
return X_train, y_train, X_test, y_test接下来,我们可以添加方法来训练和保存我们的模型。为了缩短训练时间,我们减少了max_depth和n_estimators参数的值。当然,这种减少会对我们模型的质量产生负面影响,因此如果您希望获得更好的结果,请随意尝试这些值。
def create_model():
return xgb.XGBClassifier(use_label_encoder=False, max_depth=3, n_estimators=10)
def train_model(X, y, model_filename):
model = create_model()
model.fit(X, y, eval_metric='mlogloss', verbose=True)
model.save_model(model_filename)训练后,我们使用测试数据评估模型。下面的代码说明了如何加载和使用我们的模型进行推理:
def evaluate_model(X, y, model_filename):
model = create_model()
model.load_model(model_filename)
preds = model.predict(X)
accscore = accuracy_score(y, preds)
mlflow.log_metric('accuracy', accscore)请注意最后一条语句中使用MLflow日志记录。这是推荐的方法,它允许在云和本地运行中使用相同的代码。
训练后,我们可以注册模型以备将来使用:
def register_model(ws, model_filename):
model = Model.register(
workspace=ws,
model_name=model_filename,
model_path=model_filename
)有了所有的部分,我们现在把它们放在一起:
def main():
args = parse_arguments()
ws = get_aml_workspace()
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
mlflow.start_run()
X_train, y_train, X_test, y_test = load_dataset(args.data)
model_filename = "mnist.xgb_model"
train_model(X_train, y_train, model_filename)
evaluate_model(X_test, y_test, model_filename)
register_model(ws, model_filename)
if __name__ == "__main__":
main()我们有我们的数据、计算定义和训练代码。要运行代码,我们必须决定使用哪个环境。我们可以使用自定义的Conda环境或Docker镜像。或者,我们可以使用Microsoft创建和策划的环境之一。在我们的例子中,我们选择后者。
如果您决定使用带有GPU的计算集群,请记住选择支持GPU和Nvidia CUDA驱动程序的环境。如果没有,您将支付GPU时间而无法使用它。
要开始处理我们的训练作业定义,我们单击Visual Studio Code机器学习扩展的Experiments节点。然后我们选择Command Job。它创建以下模板:
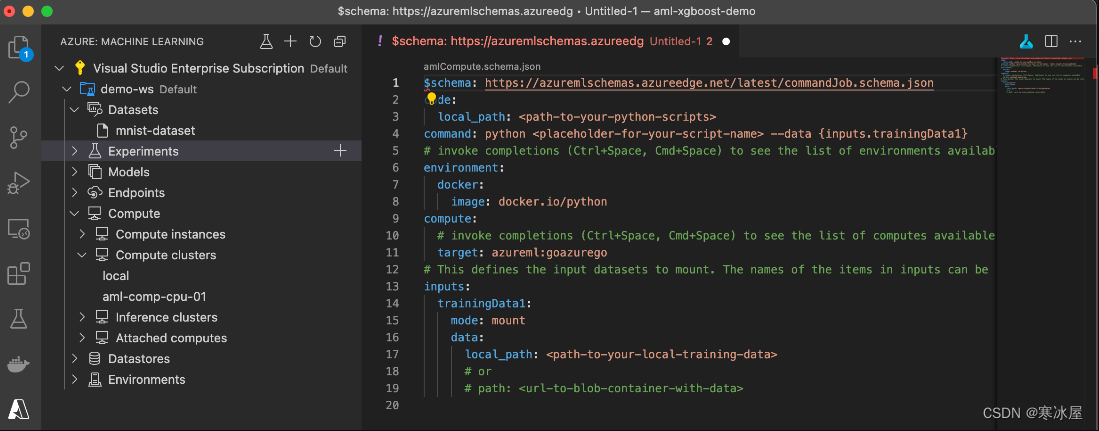
除了Command Jobs,我们还可以创建Sweep Job或Pipeline Job。Sweep Jobs通过使用预定义范围内的各种值运行多个实验来自动进行最佳超参数搜索。Pipeline Job允许我们创建复杂的多步骤实验。在我们的例子中,一个简单的命令作业就可以解决问题。
为了定义我们的训练,我们用以下内容填充模板:
$schema: https://azuremlschemas.azureedge.net/latest/commandJob.schema.json
code:
local_path: code/train
command: python train.py --data ${{inputs.mnist_data}}
environment: azureml:AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu:12
compute: azureml:aml-comp-cpu-01
inputs:
mnist_data:
dataset: azureml:mnist-dataset:1
mode: ro_mount
experiment_name: my-mnist-experiment在aml-job-train.yml文件中,我们设置了训练代码的路径并定义了运行它的命令。我们还选择了一个精心策划的环境来使用:AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu:12,它具有我们需要的所有依赖项。
我们选择要使用的计算定义并定义输入参数(inputs/ mnist_data)。请注意数据集的显式版本。我们使用(inputs/mnist_data/dataset: azureml:mnist-dataset:1.) 您可以删除:1后缀以使用最新版本或在需要时更新此值。
现在我们准备好训练了!
开始模型训练与之前的所有步骤一样,要开始训练,我们可以依赖Visual Studio Code机器学习扩展,也可以直接使用Azure CLI运行代码:
$ az ml job create --file aml-job-train.yml --subscription $SUBSCRIPTION
--resource-group $GROUP --workspace-name $WORKSPACE如果我们使用扩展程序执行作业,在日志中我们会得到以下格式的RunId(guid)和WebView URL:https://ml.azure.com/runs/?wsid=/subscriptions//resourcegroups/azureml-rg/workspaces/demo-ws。
单击此链接会将我们带到ml.azure.com控制台中的运行:
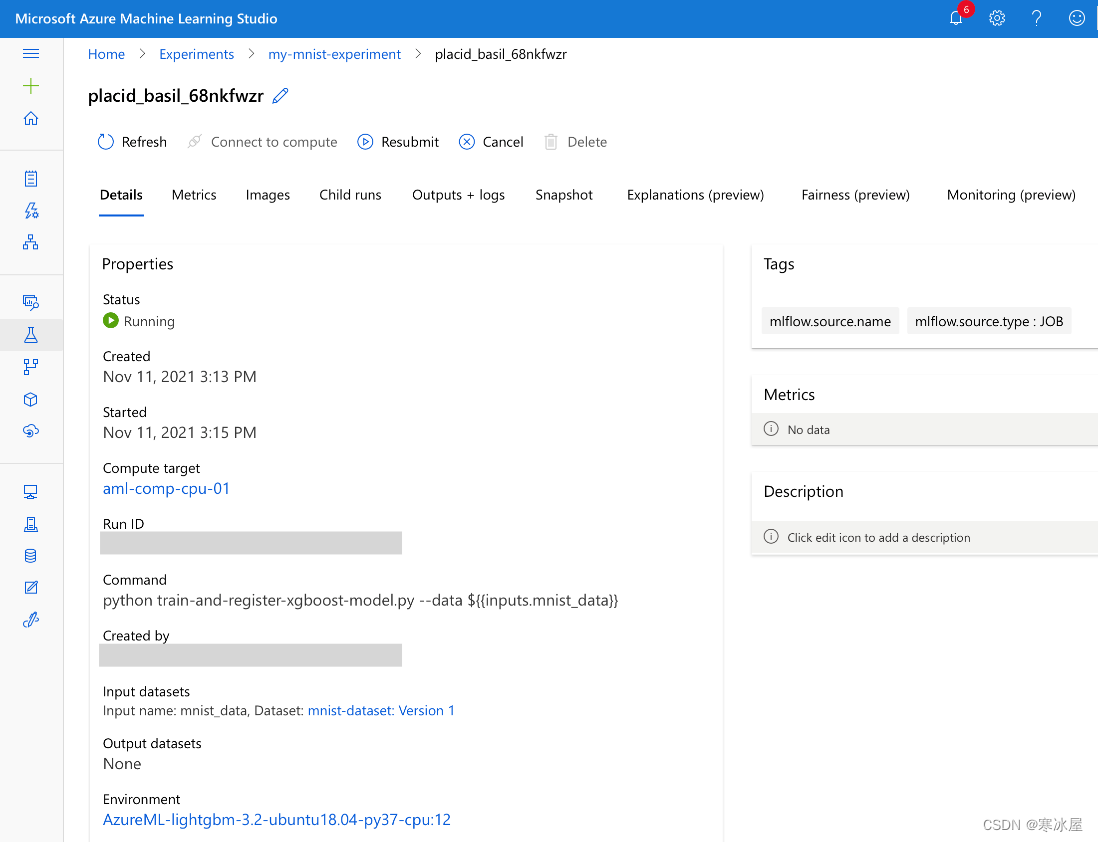
在我们的简单案例中,训练本身并不需要很长时间。最长的时间很可能是准备计算。但是,如果我们使用自定义环境,它可能会更长,因为我们必须在第一次使用之前构建它的镜像。
如前所述,我们还可以在不离开Visual Studio Code的情况下监控工作进度。例如,可以直接从实验节点下的工作室访问日志:

如果你不熟悉Azure机器学习,日志文件的数量可能会令人困惑。如果一切顺利,最重要的文件是70_driver_log.txt。它包括在计算实例中运行的训练代码生成的所有日志、控制台输出和错误。
请注意,根据您在Azure区域中的部署情况,您可能必须使用具有不同日志文件结构的不同Azure ML运行时来处理您的训练。如果您更喜欢旧版本,请确保将以下几行添加到您的培训作业定义中:
environment_variables:
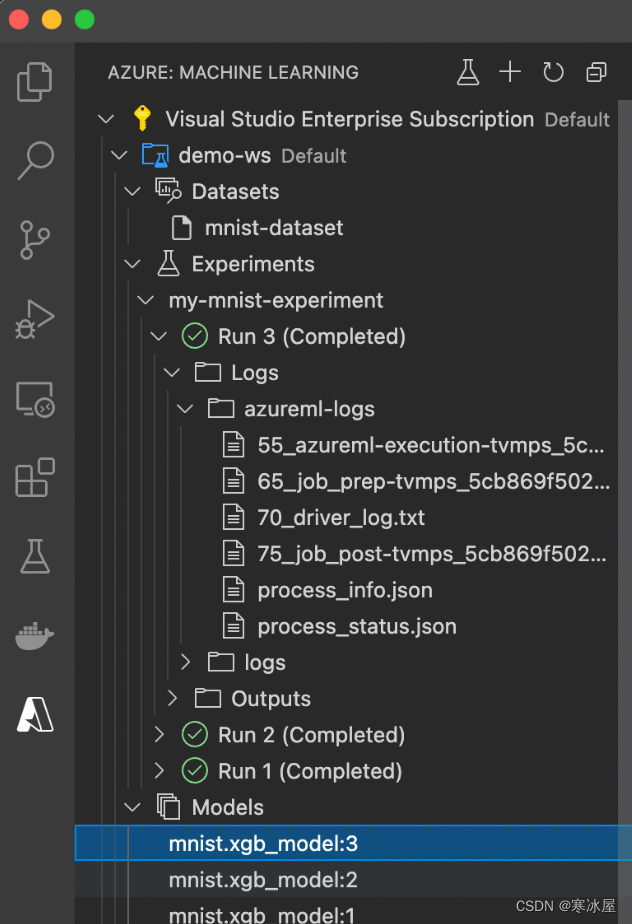
AZUREML_COMPUTE_USE_COMMON_RUNTIME: "false"训练作业完成后,我们应该在每次运行后看到新注册的模型或模型版本:
让我们回到Microsoft Azure 机器学习工作室Web 门户。我们可以检查其他详细信息,包括我们的模型在测试数据集上的准确性,记录在训练结束时:
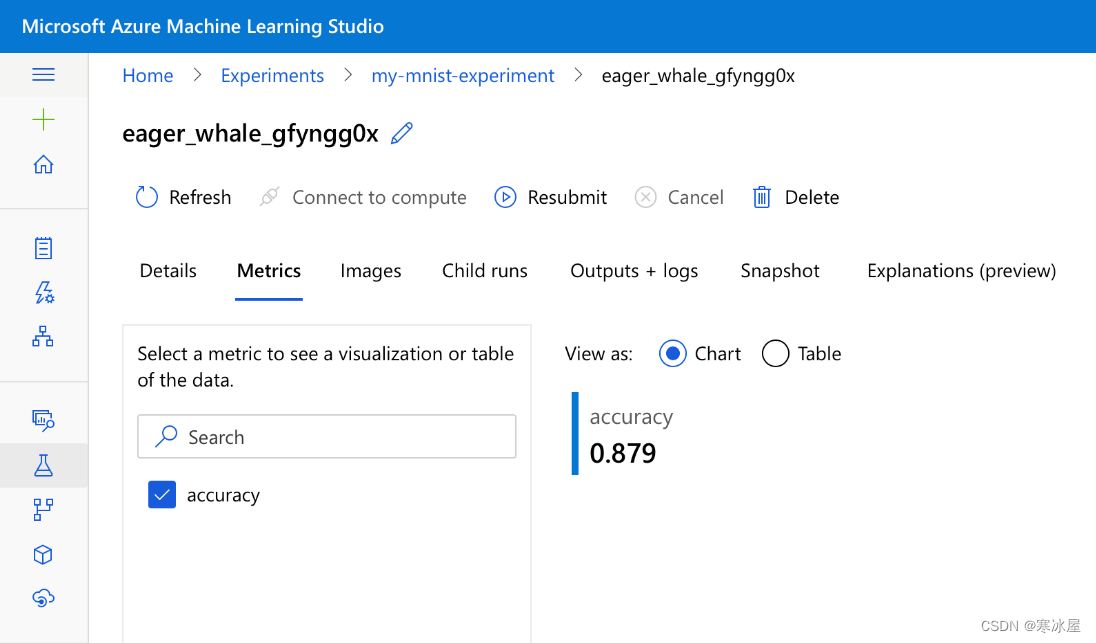
结果还不错,但与最先进的结果(即1.0)相去甚远。让我们记住,我们使用了一个配置受限的简单模型。我们相信您可以毫不费力地显着改善它!
下一步本文展示了如何在不离开Visual Studio Code的情况下使用Azure云训练XGBoost模型以识别手写数字。如果您将MNIST数据集替换为其他图像,则可以使用这种方法来训练任何图像分类任务。但是,XGBoost模型可能不是最好的模型。
以下文章向您展示了如何使用自定义PyTorch模型执行类似操作,即使您没有Visual Studio Code。
若要了解开始使用Azure机器学习所需的一切,请查看快速入门:创建工作区资源。
https://www.codeproject.com/Articles/5321611/Python-Machine-Learning-on-Azure-Part-1-Creating-a

