
目录
入门
注册模型
构建模型推理代码
创建Flask服务代码
使用Python和Flask发布应用服务
授予应用服务应用程序权限
测试服务
检查应用服务日志
使用Azure机器学习和托管终结点
创建在线端点代码
配置在线端点
创建托管在线端点
测试在线端点
删除Azure资源
下一步
这是3部分系列文章的第1部分,演示如何使用各种Python AI框架构建的AI模型,并使用Azure ML托管终结点部署和扩展它们。在本文中,我们发布了一个XGBoost模型,该模型经过训练可以从著名的MNIST数据集中识别手写数字。我们将Azure App Service与Flask一起使用,然后使用机器学习在线端点。
机器学习(ML)、数据科学和Python语言在过去几年中获得了普及和相关性。截至2021年,Python比Java、C#和 C++等成熟的老前辈更受欢迎。它于2021年11月在TIOBE指数中排名第一,比同年 9 月的第二名有所提升。在StackOverflow的2021年开发者调查中,Python也是第三受欢迎的编程语言。
每当您想到机器学习代码时,您很可能会想到Python。您可以在几乎任何东西上运行Python代码:PC、Mac或Raspberry Pi,配备x86、x86-64、AMD64或ARM/ARM64处理器,在Windows、Linux或macOS操作系统上。
机器学习通常需要强大的处理能力,这可能超出您当前计算机的能力。幸运的是,这无关紧要,只要您可以访问Internet和云。Azure是运行几乎任何规模的Python ML工作负载的好地方。
在之前的系列中,我们使用 Python和Azure服务训练了一些机器学习模型。在这个由三部分组成的系列中,我们会将这些模型发布到Azure。稍后我们将部署PyTorch和TensorFlow模型。但在第一篇文章中,我们将演示如何使用托管端点部署XGBoost模型。
我们的目标是为机器学习模型的实时推理创建自定义Rest API服务。我们将使用经过训练的模型,使用众所周知的MNIST数据集来识别手写数字。
我们将首先使用Python、Flask和Azure App Service发布XGBoost模型。然后,我们将使用相同的模型创建一个在线端点,这是一个相对较新的Azure机器学习功能,目前仍处于预览阶段。
我们依靠Azure CLI编写易于理解和可重复的脚本,我们可以存储这些脚本并与其余代码一起进行版本控制。在专用的GitHub存储库中找到本文的示例代码、脚本、模型和一些测试图像。
入门您需要Visual Studio Code、最新的Python版本(3.7+)和用于Python包管理的Conda来学习本教程。如果您没有其他偏好,请从Miniconda和Python 3.9开始。
安装Conda后,创建并激活一个新环境。
$ conda create -n azureml python=3.9
$ conda activate azureml除了Python和Conda,我们在2.15.0或更高版本中使用带有机器学习扩展的Azure命令行工具:
$ az extension add -n ml -y最后但同样重要的是,如果您还没有Azure帐户,请注册一个。您可以获得免费积分并访问许多服务。
准备好所有这些资源后,登录您的订阅。
$ az login设置以下环境变量以在脚本中使用:
export AZURE_SUBSCRIPTION=""
export RESOURCE_GROUP="azureml-rg"
export AML_WORKSPACE="demo-ws"
export LOCATION="westeurope"如果您没有遵循上一个系列中的示例,您还需要使用以下命令创建 Azure 机器学习工作区:
$ az ml workspace create --name $AML_WORKSPACE --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP --location $LOCATION现在,我们已准备好开始准备我们的模型以进行部署。
注册模型因为我们的模型很小,我们可以将它与我们的应用程序代码捆绑并部署。不过,这不是最佳做法。现实生活中的模型可能非常大。数兆字节——甚至千兆字节——并不罕见!另外,我们应该独立于我们的代码对模型进行版本控制。
因此,我们使用Azure机器学习工作区中内置的模型注册表。我们已经在上一个系列的第一篇文章中保存了我们的模型。如果你还没有,你可以很容易地做到这一点:
$ az ml model create --name "mnist-xgb-model" --local-path "./mnist.xgb_model"
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE请注意,我们将模型的名称从“mnist.xgb_model”更改为“mnist-xgb-model”。模型名称不能包含句点。
每次执行此命令时,它都会添加一个新的模型版本,无论您是否上传相同的文件。
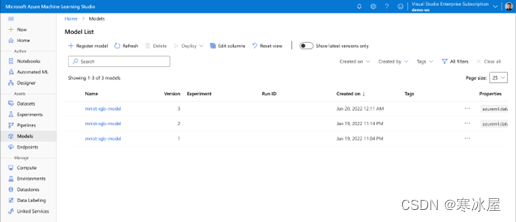
当您登录到Azure Machine Learning Studio时,它应该列出所有版本,如下图所示:
我们的Rest API服务的核心部分是加载模型并对图像数据运行推理的代码。
我们将代码保存在文件inference_model.py中:
import numpy
import xgboost as xgb
from PIL import Image
class InferenceModel():
def __init__(self, model_path):
self.model = xgb.XGBRFClassifier()
self.model.load_model(model_path)
def _preprocess_image(self, image_bytes):
image = Image.open(image_bytes)
# Reshape the image and convert it to monochrome
image = image.resize((28,28)).convert('L')
# Normalize data
image_np = (255 - numpy.array(image.getdata())) / 255.0
# Return image data reshaped to a vector
return image_np.reshape(1, -1)
def predict(self, image_bytes):
image_data = self._preprocess_image(image_bytes)
prediction = self.model.predict(image_data)
return prediction该文件包含一个使用三种方法:__init__、_preprocess_image和predict——调用的InferenceModel类。该__init__方法从文件中加载模型并将其存储以供以后使用。该_preprocess_image方法调整图像大小并将图像转换为模型期望的格式。在我们的例子中,它是一个0.0到1.0范围内的784个浮点数的向量。
该predict方法对提供的图像数据进行推理。
创建Flask服务代码现在我们有了处理预测的代码,我们可以在我们的Rest API中使用它。首先,我们将创建一个定制的Flask服务来处理这项工作。
我们从新文件app.py中的import开始:
import json
from flask import Flask, request
from inference_model import InferenceModel
from azureml.core.authentication import MsiAuthentication
from azureml.core import Workspace
from azureml.core.model import Model在访问我们的Azure机器学习工作区资源时,我们使用MsiAuthentication类进行身份验证。该类MsiAuthentication依赖于Azure Active Directory(AD)中的托管标识。我们将托管标识分配给Azure资源,例如虚拟机(VM)或应用服务。使用托管身份使我们免于维护凭据和机密。
接下来,我们创建一个从Azure机器学习模型注册表加载模型的方法:
def get_inference_model():
global model
if model == None:
auth = MsiAuthentication()
ws = Workspace(subscription_id="",
resource_group="azureml-rg",
workspace_name="demo-ws",
auth=auth)
aml_model = Model(ws, 'mnist-xgb-model', version=1)
model_path = aml_model.download(target_dir='.', exist_ok=True)
model = InferenceModel(model_path)
return model
model = None我们在这个方法中使用一个global变量来确保模型只加载一次。
为了加载模型,我们使用Azure ML Workspace和Model类。最后,我们将下载的模型文件路径传递给InferenceModel类。
有了所有这些部分,我们可以添加代码来为我们的模型提供Flask服务:
app = Flask(__name__)
@app.route("/score", methods=['POST'])
def score():
image_data = request.files.get('image')
model = get_inference_model()
preds = model.predict(image_data)
return json.dumps({"preds": preds.tolist()})在我们使用变量app声明我们的Flask应用程序之后,我们定义了score方法的路由。此方法读取提供的图像,获取推理模型并运行预测。最后,它以JSON格式返回预测结果。
使用Python和Flask发布应用服务我们几乎拥有所有代码,可以使用Python和Flask的App Service在Azure上运行我们的REST API服务。我们需要的最后一个文件是requirements.txt,内容如下:
Flask==1.0.2
gunicorn==19.9.0
xgboost==1.5.0
pillow==8.3.2
numpy==1.19.5
scikit-learn==1.0.1
azureml-core==1.35.0现在我们可以使用Azure CLI发布我们的应用服务应用程序,使用包含我们文件的文件夹中的以下命令:
$ export APP_SERVICE_PLAN=""
$ export APP_NAME=""
$ az webapp up --name $APP_NAME --plan $APP_SERVICE_PLAN --sku F1
--os-type Linux --runtime "python|3.8" --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP请注意,该APP_NAME值必须是全局唯一的,因为它将是服务URL的一部分。
此命令创建应用服务计划和应用服务,将我们的本地文件上传到Azure,然后启动应用程序。但是,这可能需要一段时间,有时它可能会无缘无故地失败。在极少数情况下,即使部署似乎成功完成,该服务也无法将您的代码正确识别为Flask应用程序,从而使该服务无法使用。
如有疑问,您可以在应用程序的部署中心选项卡中查看部署进度并登录:
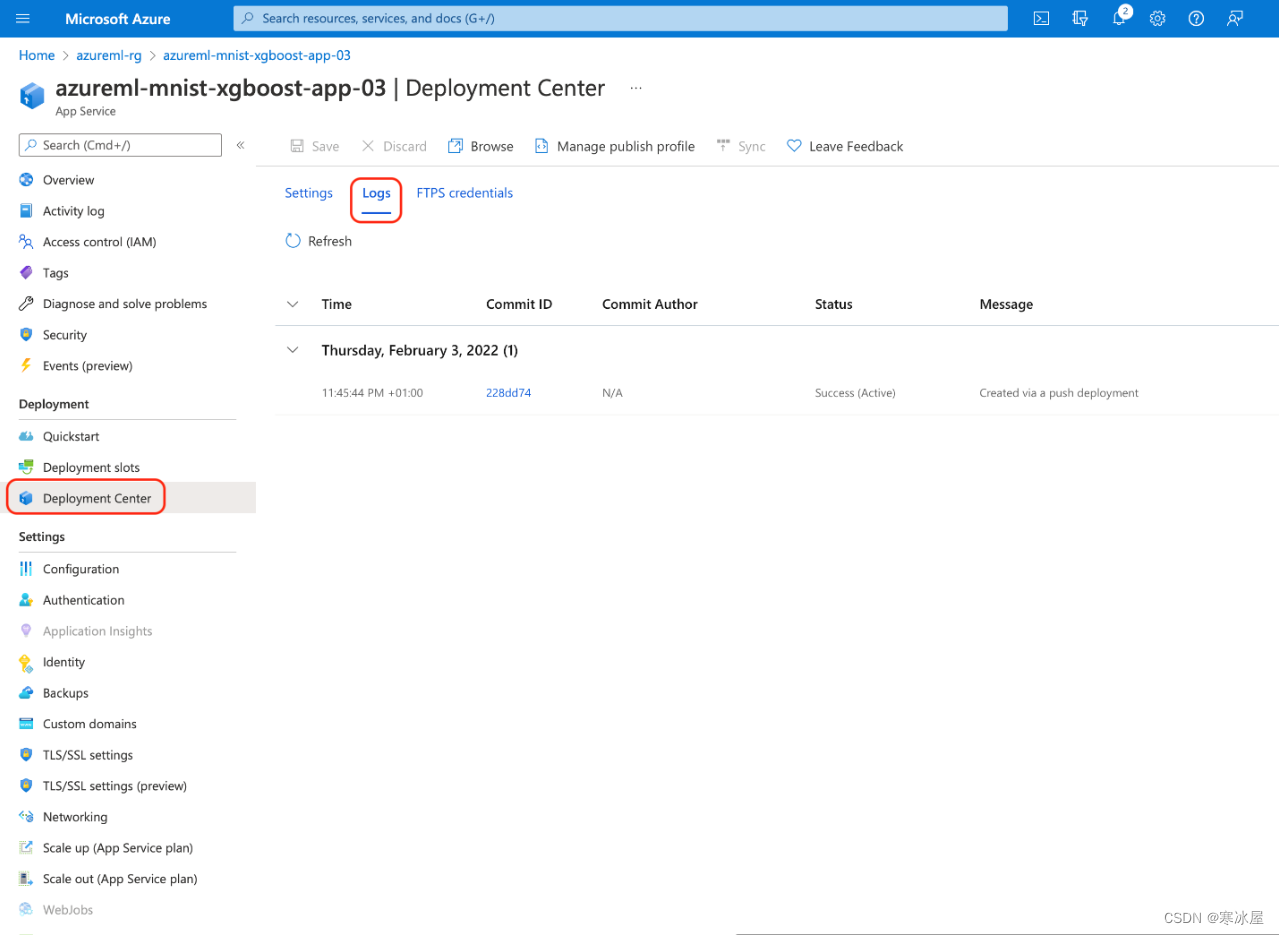
如果出现问题,尤其是与超时相关的问题,只需重试部署步骤。
命令完成后,您应该会得到类似于以下内容的JSON:
{
"URL": "http://.azurewebsites.net",
"appserviceplan": "",
"location": "centralus",
"name": "",
"os": "Linux",
"resourcegroup": "azureml-rg",
"runtime_version": "python|3.8",
"runtime_version_detected": "-",
"sku": "FREE",
"src_path": ""
}记住“URL”值。我们很快就会需要它来调用服务。
授予应用服务应用程序权限我们的服务需要从我们的Azure机器学习工作区下载经过训练的模型。但是,此操作需要授权。我们使用托管身份来避免凭据管理。
为我们的应用程序分配一个新的托管标识很简单。添加以下代码:
$ az webapp identity assign --name $APP_NAME --resource-group $RESOURCE_GROUP完成后,我们应该期待一个JSON。
{
"principalId": "",
"tenantId": "",
"type": "SystemAssigned",
"userAssignedIdentities": null
}当我们有返回的“”值时,我们可以添加所需的权限。
$ az role assignment create --role reader --assignee
--scope /subscriptions/$AZURE_SUBSCRIPTION/resourceGroups/$RESOURCE_GROUP/providers/
Microsoft.MachineLearningServices/workspaces/$AML_WORKSPACE读者角色应该足以满足我们的目的。如果我们的应用程序需要创建额外的资源,我们应该使用贡献者角色。
测试服务使用我们已经用于训练模型的任何图像都不会有趣。所以,让我们使用一些新的。您可以在示例代码文件夹中的test-images/d0.png到d9.png文件中找到它们。它们看起来像这样:
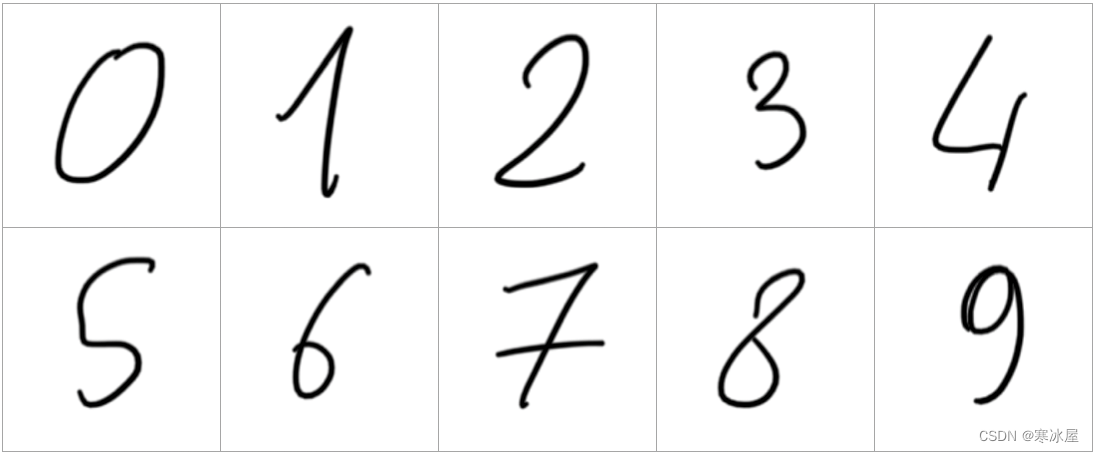
这些图像没有严格的要求。我们服务的代码将重新缩放并将它们转换为预期的大小和格式。
我们需要发送POST请求来调用我们的服务。我们可以使用Postman或curl。我们可以使用以下curl命令直接从命令行执行我们的请求:
$ curl -X POST -F 'image=@./test-images/d6.png' https://$APP_NAME.azurewebsites.net/score如果一切顺利,我们可以期待以下响应:
{"preds": [6]}很好!在我们简单的XGBoost模型中,答案似乎是正确的。不过,这不会成为常态。
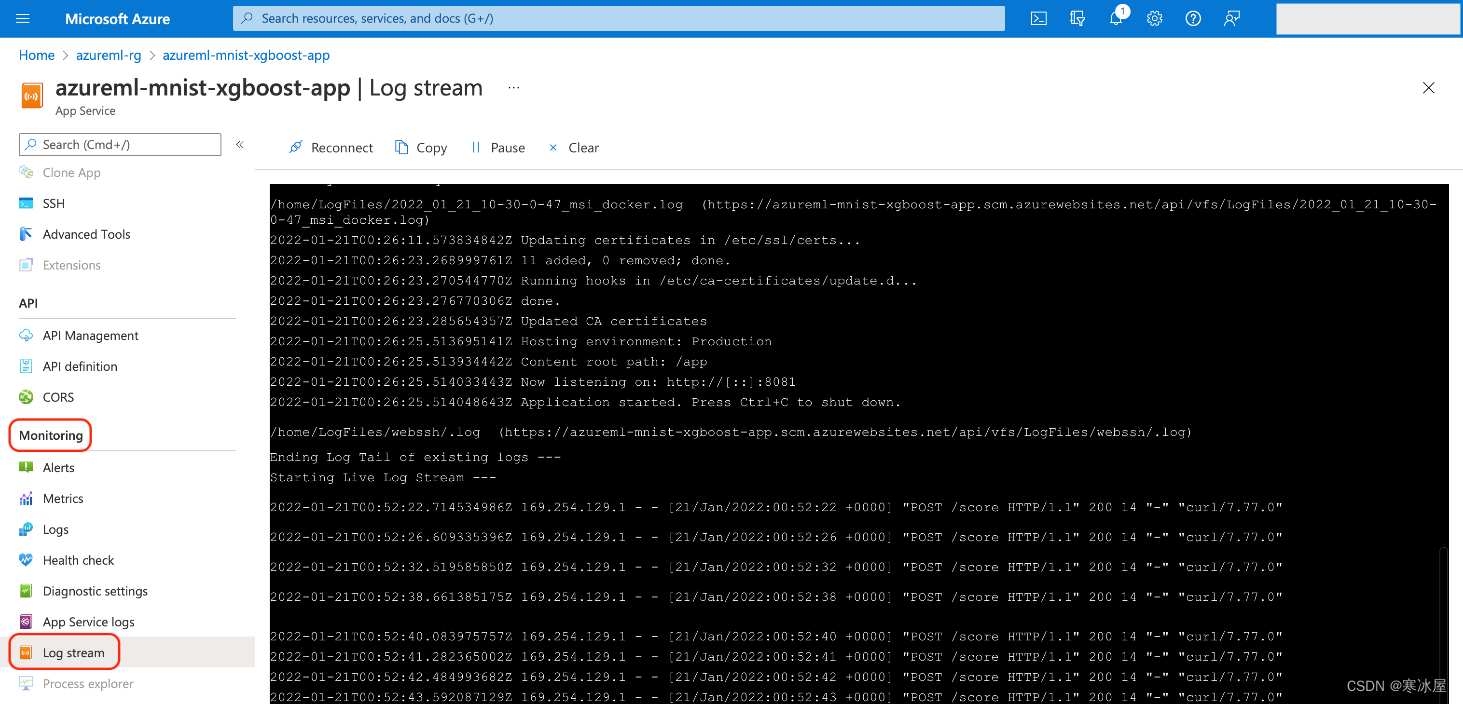
检查应用服务日志如果您遇到任何问题,您可能需要检查您的服务日志。您可以通过Azure门户 监控 > 日志流选项卡执行此操作:
或者,您可以使用Azure CLI访问日志:
$ az webapp log tail --name $APP_NAME --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP使用托管为Azure应用服务的自定义Flask应用程序发布我们的模型非常简单。通过这样做,我们可以体验所有标准应用服务优势,例如手动或自动扩展,具体取决于定价层。
尽管如此,对于应用服务解决方案,我们需要编写和维护与模型推理相关的代码,以及负责将其作为REST服务、安全性和其他较低级别细节的代码。
Azure机器学习(仍处于预览阶段)中可用的新替代方案之一是托管终结点机制。我们将在以下部分中使用我们的模型创建一个在线端点。
创建在线端点代码我们将从Flask应用程序中复制相同的InferenceModel类到新文件夹端点代码中的inference_model.py文件中。
与之前的Flask应用程序一样,我们需要一些代码来定义我们的服务。我们将代码放在endpoint-code/aml-score.py文件中。这一次,我们可能会依赖内置的Azure机器学习机制:
import os
import json
from inference_model import InferenceModel
from azureml.contrib.services.aml_request import rawhttp
from azureml.contrib.services.aml_response import AMLResponse
def init():
global model
model_path = os.path.join(
os.getenv("AZUREML_MODEL_DIR"), "mnist.xgb_model"
)
model = InferenceModel(model_path)
@rawhttp
def run(request):
if request.method != 'POST':
return AMLResponse(f"Unsupported verb: {request.method}", 400)
image_data = request.files['image']
preds = model.predict(image_data)
return AMLResponse(json.dumps({"preds": preds.tolist()}), 200)我们只需要两种方法。init该代码在端点启动时调用第一个, 一次。这是加载我们模型的好地方。我们使用AZUREML_MODEL_DIR环境变量来执行此操作,它指示我们模型文件的位置。
以下run方法非常简单。首先,我们确保只接受POST请求。然后实际逻辑开始:我们从请求中检索图像,然后运行并返回预测。
注意@rawhttp装饰器。我们要求它访问原始请求数据(在我们的例子中是二进制图像内容)。没有它,传递给run方法的request参数将仅限于解析的JSON。
配置在线端点除了代码,我们还需要三个配置文件。第一个,endpoint-code/aml-env.yml,存储Conda环境定义:
channels:
- conda-forge
- defaults
dependencies:
- python=3.7.10
- numpy=1.19.5
- xgboost=1.5.0
- scikit-learn=1.0.1
- pillow=8.3.2
- pip
- pip:
- azureml-defaults==1.35.0
- inference-schema[numpy-support]==1.3.0以下两个包含端点及其部署的配置。
端点配置文件aml-endpoint.yml包含:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: mnistxgboep
auth_mode: key除了端点名称(无论如何我们都可以在脚本中更改)之外,该文件只包含一个有意义的行。它设置auth_mode为key,以便我们在调用端点时使用随机生成的“secret”string作为身份验证令牌。
最后一个文件aml-endpoint-deployment.yml包含以下代码:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: mnistxgboep
model: azureml:mnist-xgb-model:1
code_configuration:
code:
local_path: ./endpoint-code
scoring_script: aml-score.py
environment:
conda_file: ./endpoint-code/aml-env.yml
image: mcr.microsoft.com/azureml/minimal-ubuntu18.04-py37-cpu-inference:latest
instance_type: Standard_F2s_v2
instance_count: 1在部署配置中,我们设置了基本的详细信息,例如模型名称和版本。该code_configuration部分指示我们端点的路径及其主脚本文件。请注意,您需要明确定义模型版本,以便代码自动下载并保存这个确切的模型版本,以便为我们的服务做好准备。
接下来,我们定义Docker镜像、Conda环境配置文件、VM实例大小和实例数。
创建托管在线端点准备好所有这些文件后,我们就可以开始部署了。我们从端点开始:
$ export ENDPOINT_NAME=""
$ az ml online-endpoint create -n $ENDPOINT_NAME -f aml-endpoint.yml
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE与之前的应用服务应用程序名称一样,每个Azure区域的终结点名称必须是唯一的。它将成为URL的一部分,格式如下:
https://..inference.ml.azure.com/score创建端点后,我们终于可以部署我们的推理代码了:
$ az ml online-deployment create -n blue
--endpoint $ENDPOINT_NAME -f aml-endpoint-deployment.yml
--all-traffic --subscription $AZURE_SUBSCRIPTION
--resource-group $RESOURCE_GROUP --workspace-name $AML_WORKSPACE很长一段时间后,该命令应返回确认部署已完成且端点已准备好使用。现在,我们可以检查它是如何工作的。
测试在线端点我们需要端点URL、端点密钥和示例图像来调用我们的端点。我们已经使用了示例图像,因此我们只需要端点URL和密钥。获取它们的一种方法是通过Azure Machine Learning Studio ,从端点的“使用”选项卡:
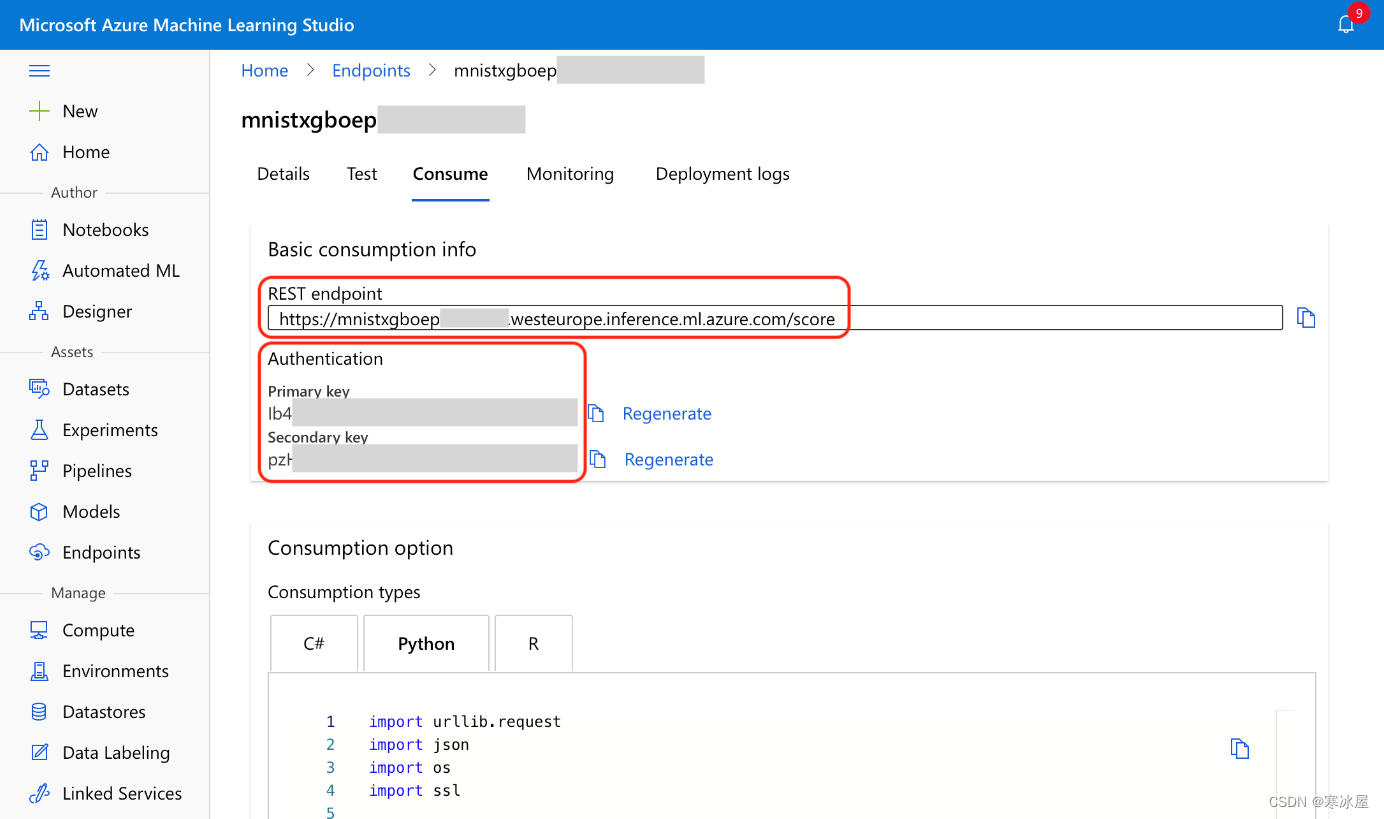
与(几乎)一样,我们也可以使用Azure CLI获取这些值:
$ SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv
--query scoring_uri --resource-group $RESOURCE_GROUP --workspace $AML_WORKSPACE)
$ ENDPOINT_KEY=$(az ml online-endpoint get-credentials --name $ENDPOINT_NAME
--subscription $AZURE_SUBSCRIPTION --resource-group $RESOURCE_GROUP
--workspace-name $AML_WORKSPACE -o tsv --query primaryKey)无论如何,填充SCORING_URI和ENDPOINT_KEY变量后,我们可以调用我们的服务:
$ curl -X POST -F 'image=@./test-images/d6.png'
-H "Authorization: Bearer $ENDPOINT_KEY" $SCORING_URI如果一切顺利,我们应该得到与Flask应用程序相同的答案:
{"preds": [6]}你可以删除不再需要的所有资源以减少Azure费用。请特别记住应用服务计划和托管终结点(尽管我们在此示例中使用了免费的应用服务计划)。
下一步我们已经成功发布了一个XGBoost模型,该模型经过训练可以识别手写数字,使用Flask和App Service,并管理在线端点。下面的文章与此类似,但我们将使用PyTorch而不是XGBoost,使用FastAPI而不是Flask。 此外,我们将快速浏览FastAPI代码以专注于一些额外的托管在线端点功能。
继续阅读本系列的第二部分,了解如何部署和扩展PyTorch模型。
要了解如何使用在线端点(预览版)部署机器学习模型,请查看使用在线端点部署机器学习模型并对其进行评分。
https://www.codeproject.com/Articles/5328263/Deploying-Models-at-Scale-on-Azure-Part-1-Deployin

