
目录
例子
工作示例
在BigQuery上运行
注意
在这篇文章中,我们将了解如何调查或“调试” BigQuery的使用情况。
本文首次出现在Pascal Landau ¯\_(ツ)_/¯ | pascallandau.com上的BigQuery:通过INFORMATION_SCHEMA监控查询成本。
Google BigQuery中的成本监控可能是一项艰巨的任务,尤其是在不断发展的组织和许多(独立)有权访问数据的利益相关者中。如果您的组织不使用预留插槽(统一费率定价),而是按处理的字节数计费(按需定价),成本可能会很快失控,我们需要调查或“调试”的方法BigQuery用法以了解:
- 谁以高成本运行查询
- 确切的查询是什么
- 这些查询何时运行(它们甚至可能定期运行)
以前,我们必须通过Stackdriver手动设置查询日志记录,如采用实用的BigQuery成本监控方法一文中所述,但在2019年底,BigQuery引入了INFORMATION_SCHEMA视图作为测试版功能,其中还通过INFORMATION_SCHEMA.JOBS_BY_包含有关BigQuery作业的数据*查看并于2020年6月16日正式发布 (GA)。
例子SELECT
creation_time,
job_id,
project_id,
user_email,
total_bytes_processed,
query
FROM
`region-us`.INFORMATION_SCHEMA.JOBS_BY_USER
SELECT * FROM `region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
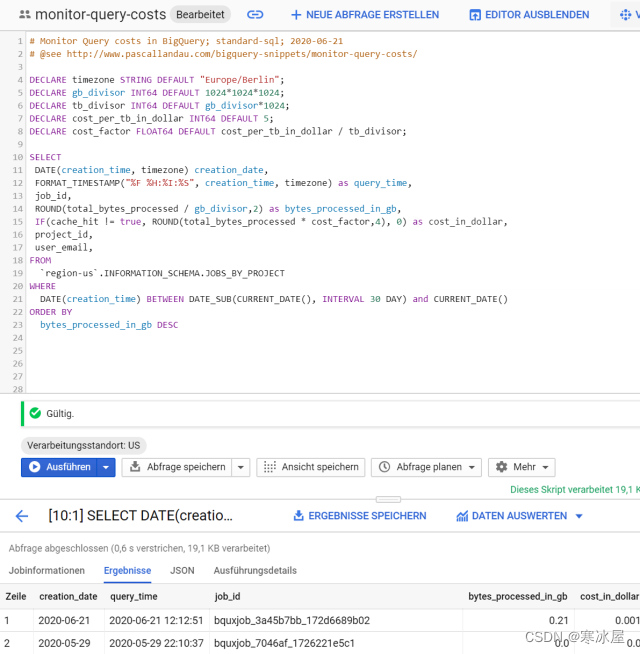
SELECT * FROM `region-us`.INFORMATION_SCHEMA.JOBS_BY_ORGANIZATION# Monitor Query costs in BigQuery; standard-sql; 2020-06-21
# @see http://www.pascallandau.com/bigquery-snippets/monitor-query-costs/
DECLARE timezone STRING DEFAULT "Europe/Berlin";
DECLARE gb_divisor INT64 DEFAULT 1024*1024*1024;
DECLARE tb_divisor INT64 DEFAULT gb_divisor*1024;
DECLARE cost_per_tb_in_dollar INT64 DEFAULT 5;
DECLARE cost_factor FLOAT64 DEFAULT cost_per_tb_in_dollar / tb_divisor;
SELECT
DATE(creation_time, timezone) creation_date,
FORMAT_TIMESTAMP("%F %H:%I:%S", creation_time, timezone) as query_time,
job_id,
ROUND(total_bytes_processed / gb_divisor,2) as bytes_processed_in_gb,
IF(cache_hit != true, ROUND(total_bytes_processed * cost_factor,4), 0) as cost_in_dollar,
project_id,
user_email,
FROM
`region-us`.INFORMATION_SCHEMA.JOBS_BY_USER
WHERE
DATE(creation_time) BETWEEN DATE_SUB(CURRENT_DATE(), INTERVAL 30 DAY) and CURRENT_DATE()
ORDER BY
bytes_processed_in_gb DESC- 此查询将从INFORMATION_SCHEMA.JOBS_BY_USER视图中为当前所选项目中已在美国地区运行的所有作业选择成本监控方面最有趣的字段。
- cost_in_dollar是通过计算TB中的total_bytes_processed并将结果乘以5.00美元(对应于今天2020-06-22的成本)来估算的。此外,我们仅在查询未从缓存中回答时才考虑这些成本(请参阅cache_hit != true条件)。
- 将creation_time转换为我们当地的时区。
- 通过使用WHERE子句对分区列creation_time进行过滤,结果被限制在过去30天。
- 随意替换JOBS_BY_PROJECT为JOBS_BY_USER或JOBS_BY_ORGANIZATION
在BigQuery界面中打开
在玩转INFORMATION_SCHEMA视图时,我遇到了几个问题:
- 不同的视图需要不同的权限。
- 视图是区域化的,即我们必须为区域添加前缀(参见region-us视图规范),并且必须在该区域中运行作业(例如,从BigQuery UI通过More > Query Settings > Processing location)
- 不能在查询中混合多个区域,因为处理location US的查询只能访问location US中的资源。虽然这对积极使用不同位置的组织非常有帮助,但这样的事情是不可能的:
SELECT * FROM
(SELECT * `region-us`.INFORMATION_SCHEMA.JOBS_BY_ORGANIZATION)
UNION ALL
(SELECT * `region-eu`.INFORMATION_SCHEMA.JOBS_BY_ORGANIZATION)- 目前仅保留过去180天的数据。
- 该JOBS_BY_USER视图似乎根据电子邮件地址“匹配”用户。我的用户电子邮件地址是一个@googlemail.com地址;在用户列中,它存储为@gmail.com。因此,我在使用JOBS_BY_USER是没有得到结果。
- JOBS_BY_USER和JOBS_BY_PROJECT将默认使用当前选择的项目。可以通过以下方式指定不同的项目(例如,other-project ):
SELECT * FROM `other-project.region-us`.INFORMATION_SCHEMA.JOBS_BY_PROJECT- 完整query版不可用JOBS_BY_ORGANIZATION。
由于技术限制,本文限制为40000个字符。阅读BigQuery的完整内容:通过INFORMATION_SCHEMA监控查询成本
本文最初发布于BigQuery: Monitor Query Costs via INFORMATION_SCHEMA | pascallandau.com
https://www.codeproject.com/Articles/5331050/BigQuery-Monitor-Query-Costs-via-INFORMATION-SCHEM

