
- 01 引言
- 02 pod生命周期
- 03 pod重启策略
- 04 pod健康检查和服务可用性检查
- 4.1 方式一:ExecAction
- 4.2 方式二:TCPSocketAction
- 4.3 方式三:HTTPGetAction
- 4.4 其它
- 05 文末
声明:本文为《Kubernetes权威指南:从Docker到Kubernetes实践全接触(第5版)》的读书笔记
本文主要讲解pod的生命周期、重启策略、健康检查及服务可用性检查。
02 pod生命周期pod在整个生命周期中被系统定义为各种状态,熟悉pod的各种状态对于理解如何设置pod的调度策略、重启策略是很有必要的,pod状态如下:
状态值描述PendingAPI Server已经创建了pod,但在pod内还有一个或多个容器的镜像没有创建,包括正在下载镜像的过程Runningpod内所有容器均已创建,且至少有一个容器处于运行状态、正在启动状态或正在重启状态Succeededpod内所有容器均成功执行后退出,且不会在重启 Failedpod内所有容器均已退出,但至少有一个容器为退出失败状态Unknown 由于某种原因无法获取该Pod的状态,可能由于网络通信不畅导致的 03 pod重启策略pod的重启策略(RestartPolicy)应用于pod内的所有容器,并且仅在pod所处的 node 上 由kubelet 进行判断和重启操作。
当某个容器异常退出或者健康检查 失败时,kubelet将根据RestartPolicy的设置进行相应的操作,pod的重启策略包括Always、OnFailure和Never(默认值为Always):
kubelet重启失效容器的时间间隔以symc-frequency乘以2n来计算,例如1、 2、4、8倍等,最长延时5min,并且在成功重启后的10min后重置该时间。
pod的重启策略与控制方式息息相关,当前可用于管理pod的控制器包括 ReplicationController、Job、DaemonSet,还可以通过kubelet管理(静态 pod)。每种控制器对Pod的重启策略要求如下:
结合pod的状态和重启策略,常见的状态转换场景如下: 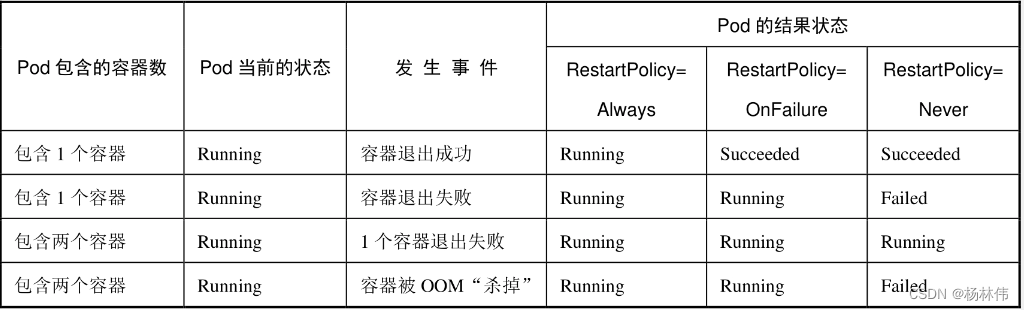
Kubernetes对Pod的健康状态可以通过三类探针来检查:LivenessProbe、 ReadinessProbe及StartupProbe,其中最主要的探针为LivenessProbe与 ReadinessProbe,kubelet会定期执行这两类探针来诊断容器的健康状况。
探针作用LivenessProbe探针用于判断容器是否存活(Running状态),如果LivenessProbe探针探测到容器不健康,则kubelet“将“杀掉”该容器,并根据容器的重启策略做相应的处理。如果一个容器不包含LivenessProbe探针,那么kubelet认 为该容器的LivenessProbe探针返回的值永远是SuccessReadinessProbe探针用于判断容器服务是否可用(Ready状态),达到Ready状态的Pod才可以接收请求。对于被Service管理的Pod、Service与PodEndpoint的关联关系也将基于Pod是否Ready进行设置。如果在运行过程中Ready 状态变为False,则系统自动将其从Service的后端Endpoint列表中隔离出去,后续再把恢复到Ready状态的Pod加回后端Endpoint列表。这样就能保证客户端在访问Service时不会被转发到服务不可用的Pod实例上。需要注意的是ReadinessProbe也是定期触发执行的,存在于Pod的整个生命周期中StartupProbe探针某些应用会遇到启动比较慢的情况,例如应用程序启动时需要与远程服务器建立网络连接,或者遇到网络访问较慢等情况时,会造成容器启动缓慢,此时ReadinessProbe就不适用了,因为这属于“有且仅有一次” 的超长延时,可以通过StartupProbe探针解决该问题以上探针均可配置以下三种实现方式。
4.1 方式一:ExecActionExecAction在容器内部运行一个命令,如果该命令的返回码为0,则 表明容器健康。
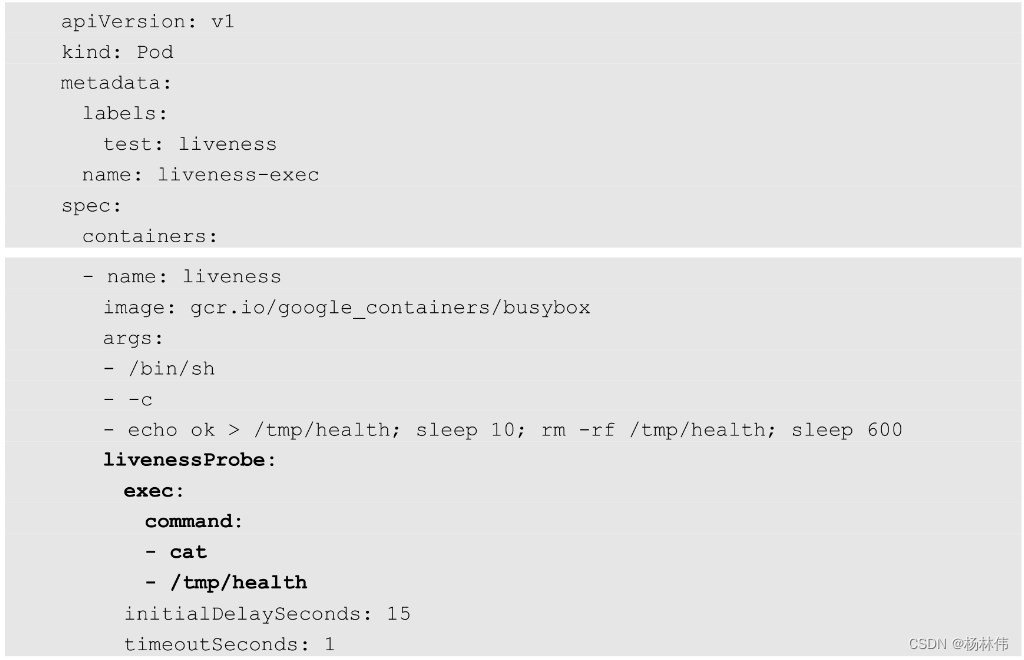
举例:通过运行cat/tmp/health命令来判断一个容器运行是否正常。在该pod运行后,将在创建/tmp/health文件10s后删除该文件,而LivenessProbe健康检查的初始探测时间(initialDelaySeconds)为15s,探测结果是Fail,将导致kubelet “杀掉” 该容器并重启它:
TCPSocketAction通过容器的IP地址和端口号执行TCP检查,如果能够建立TCP连接,则表明容器健康。
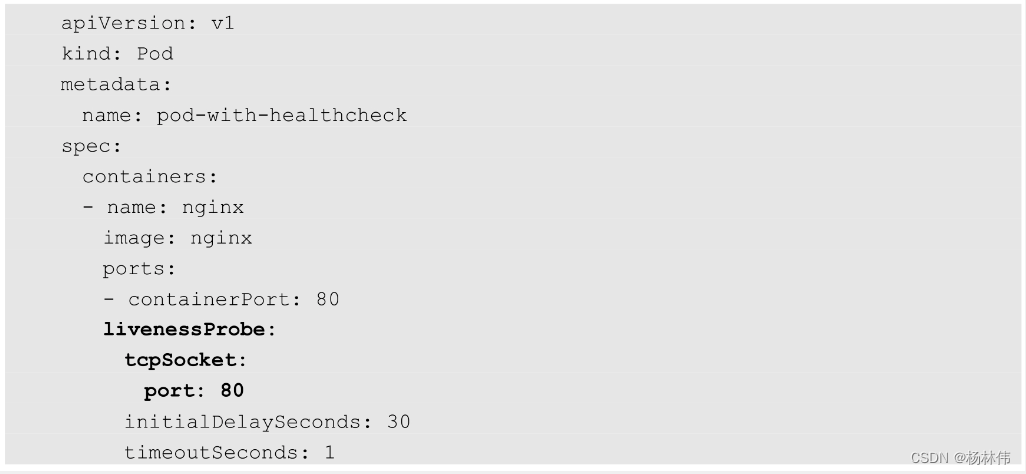
举例:通过与容器内的localhost:80建立TCP连接进行健康检查:
HTTPGetAction通过容器的IP地址、端口号及路径调用HTTP Get方 法,如果响应的状态码大于等于200且小于400,则认为容器健康。
举例:kubelet定时发送HTTP请求到localhost:80/_status,/healthz来进行容器应用的健康检查:

对于每种探测方式,都需要设置initialDelaySeconds和timeoutSeconds两个参数,它们的含义分别如下。
参数含义initialDelaySeconds启动容器后进行首次健康检查的等待时间,单位为stimeoutSeconds健康检查发送请求后等待响应的超时时间,单位为s ,当超时发生时,kubelet会认为容器已经无法提供服务,将会重启该容器如下代码片段是StartupProbe探针的一个参考配置,可以看到,这个Pod可以有长达30×10=300s的超长启动时间: 
Kubernetes的Pod可用性探针机制可能无法满足某些复杂应用对容器内服务可 用状态的判断,所以Kubernetes从1.11版本开始,引入了Pod Ready++特性对Readiness探测机制进行扩展,在1.14版本时达到GA稳定版本,称其为Pod Readiness Gates。
Pod Readiness Gates给予了Pod之外的组件控制某个Pod就绪的能力,通过Pod Readiness Gates机制,用户可以设置自定义的Pod可用性探测方式来告诉Kubernetes某个Pod是否可用,具体使用方式是用户提供一个外部的控 制器(Controller)来设置相应Pod的可用性状态。
举例:Pod的Readiness Gates在Pod定义中的ReadinessGate字段进行一个类型为www.example.com/feature-l的新Readiness Gate:  新增的自定义
新增的自定义Condition的状态(status)将由用户自定义的外部控制器设置(默认值为False)Kubernetes将在判断全部readinessGates条件都为True时, 才设置Pod为服务可用状态(Ready为True)。
本文主要讲解pod生命周期、重启策略及健康检查,希望能帮助到大家,谢谢大家的阅读,本文完!

