一、概述: 如果你的Oracle数据库性能低下,行链接和行迁移可能是其中的原因之一。我们能够通过合理的设计或调整数据库来阻止这个现象。 行链接和行迁移是能够被避免的两个潜在性问题。我们可以通过合理的调整来提高数据库性能。本文主要描述的是: 什么是行迁移与行链接 如何判断行迁移与行链接 如何避免行迁移与行链接
当使用索引读取单行时,行迁移影响OLTP系统。最糟糕的情形是,对所有读取操作而言,增加了额外的I/O。行链接则影响索引读和全表扫描。 注:在翻译行(row)时使用记录来描述(便于理解),如第一行,使用第一条记录。
二、Oralce 块
操作系统块的大小是操作系统读写的最小操作单元,也是操作系统文件的属性之一。当创建一个数据库时,选择一个基于操作系统块的
整数倍大小作为Oracle数据库块的大小。Oracle数据库读写操作则是以Oracle块为最小单位,而非操作系统块。一旦设置了Oracle数据块的大小,
则在整个数据库生命期间不能被更改(除 Oracle 9i之外)。因此为Oracle数据库定制合理的Oralce块大小,象预期数据库总大小以及并发用户数这些
因素应当予以考虑。
数据库块由下列逻辑结构(在整个数据库结构下)

头部 头部包含一些常用信息,象块地址,段的类型(表段、索引段等)。也包含一些表、实际数据行的地址信息等。 空闲空间 用于保留给后续DML(update/insert)操作的空间。通常受pctfree和pctused参数的影响。 数据 实际的数据内容 FREELIST, PCTFREE, PCTUSED 当创建或修改任意表,索引时。Oracle使用两个存储参数来控制空间的分配 PCTFREE 为已存在数据将来更新需要保留空闲空间的百分比 PCTUSED 新插入数据可使用空间的最小百分比,该值决定块何时回收到 freelist 结构中 FREELIST Oracle通过维护该列表来记录或更新所有可用的数据块 Oracle 首先在freelist列表上搜索可用的空闲数据块,搜索成功之后将数据插入到那个空闲块。块在free list 列表中的可用性由pctfree 参数值来决定。起初一个空块在freelist列表上列出,并且会一直保留,直到到空闲空间达到pctfree设定的值。 当一个块被使用且达到pctfree设定的值之后则该块从freelist列表被移除,而当数据块的可用空间低于PCTUSED值的时候,该块又会回收, 即重新回到freelist列表。 Oracle使用freelist方式以提高数据库性能。因此,每一个insert 操作,Oracle 仅仅需要搜索freelist结构,而不是搜索所有数据块。
三、行迁移:
当一个行上的更新操作(原来的数据存在且没有减少)导致当前的数据不能在容纳在当前块,我们需要进行行迁移。一个行迁移意味着整
行数据将会移动,仅仅保留的是一个转移地址。因此整行数据都被移动,原始的数据块上仅仅保留的是指向新块的一个地址信息。
 迁移行不影响全表扫描
当使用全表扫描时,转移地址被忽略。因为我们最终能够获得所有的数据,所以能够忽略其转移地址。因此行迁移并不会对全表扫描产
生额外的操作。
迁移行对索引读产生额外的I/O
当使用索引读取数据时将产生额外的I/O。这是由于索引告诉我们通过文件X,块Y,slot槽Z可以获得该行数据。但是当我们根据地址信息
达到所在位置时,从其转移地址得知,其真实的数据是存储在文件A,块B,slot槽C上。因此为了寻找该行数据不得不产生额外的逻辑或物理I/O。
迁移行不影响全表扫描
当使用全表扫描时,转移地址被忽略。因为我们最终能够获得所有的数据,所以能够忽略其转移地址。因此行迁移并不会对全表扫描产
生额外的操作。
迁移行对索引读产生额外的I/O
当使用索引读取数据时将产生额外的I/O。这是由于索引告诉我们通过文件X,块Y,slot槽Z可以获得该行数据。但是当我们根据地址信息
达到所在位置时,从其转移地址得知,其真实的数据是存储在文件A,块B,slot槽C上。因此为了寻找该行数据不得不产生额外的逻辑或物理I/O。
四、行链接
当一行数据太大而不能在一个单数据块容纳时,行链接由此产生。举例来说,当你使用了4kb的Oracle 数据块大小,而你需要插入一行 数据是8k,Oracle则需要使用3个数据块分成片来存储。因此,引起行链接的情形通常是,表上行记录的大小超出了数据库Oracle块的大小。 表上使用了LONG 或 LONG RAW数据类型的时候容易产生行链接。其次表上多于255列时Oracle会将这些过宽的表分片而产生行链接。因此, 与行迁移所不同的是,行迁移是将数据存放到另外一个块,而行链接是数据同时位于多个数据块。

行链接有着不同于行迁移的影响,取决于我们所需的数据。如果我们有一行数据有两个列且跨越两个数据块。假定使用下面的查询: SELECT column1 FROM table 列1位于第一块,它将不会引起任何table fetch continued row 。由于不需要获得第2列的信息,因此行链接没有任何影响。然而,如 果我们使用下面的查询: SELECT column2 FROM table 由于 column2 在块2且是一个链接行,因此将产生table fetch continued row 五、示例样本:
- --下面的引用Tom Kyte的例子来展示行迁移和行链接. 我们使用了一个4k 的 blocksize.
- SELECT name,value
- FROM v$parameter
- WHERE name = 'db_block_size';
- NAME VALUE
- -------------- ------
- db_block_size 4096
- --使用固定列宽的char类型来创建下面的表
- CREATE TABLE row_mig_chain_demo (
- x int PRIMARY KEY,
- a CHAR(1000),
- b CHAR(1000),
- c CHAR(1000),
- d CHAR(1000),
- e CHAR(1000)
- );
- --上面的这个表很容易产生行链接和行迁移。我们使用了5个列 a,b,c,d,e,以便于整个行的长度增长达到或超过5k以确保产生真实的行链接。
- INSERT INTO row_mig_chain_demo (x) VALUES (1);
- INSERT INTO row_mig_chain_demo (x) VALUES (2);
- INSERT INTO row_mig_chain_demo (x) VALUES (3);
- COMMIT;
- --a,b,c,d,e列我们并没有兴趣查看,而仅仅是提取他们。由于他们的确太宽,我们在查询结果中没有显示这些列。
- column a noprint
- column b noprint
- column c noprint
- column d noprint
- column e noprint
- SELECT * FROM row_mig_chain_demo;
- X
- ----------
- 1
- 2
- 3
- 检查行链接
- SELECT a.name, b.value
- FROM v$statname a, v$mystat b
- WHERE a.statistic# = b.statistic#
- AND lower(a.name) = 'table fetch continued row';
- NAME VALUE
- ---------------------------------------------------------------- ----------
- table fetch continued row 0
- --现在正如我们所期待的那样,按插入的顺序返回的结果(对这个查询Oracle使用了全表扫描)。也如我们所预料的那样table fetch continued row 为零值。
- --这个数据是现在是如此的小,我们知道三行数据填充到一个数据块,没有行链接。
 六、演示行迁移
六、演示行迁移
- --接下来,我们基于指定的方式做一些更新来演示行迁移的问题以及他如何影响全扫描。
- UPDATE row_mig_chain_demo SET a = 'z1', b = 'z2', c = 'z3' WHERE x = 3;
- COMMIT;
- UPDATE row_mig_chain_demo SET a = 'y1', b = 'y2', c = 'y3' WHERE x = 2;
- COMMIT;
- UPDATE row_mig_chain_demo SET a = 'w1', b = 'w2', c = 'w3' WHERE x = 1;
- COMMIT;
- --注意更新的顺序,最后一行我们首先更新,而第一行则最后更新它。
- SELECT * FROM row_mig_chain_demo;
- X
- ----------
- 3
- 2
- 1
- SELECT a.name, b.value
- FROM v$statname a, v$mystat b
- WHERE a.statistic# = b.statistic#
- AND lower(a.name) = 'table fetch continued row';
- NAME VALUE
- ---------------------------------------------------------------- ----------
- table fetch continued row 0
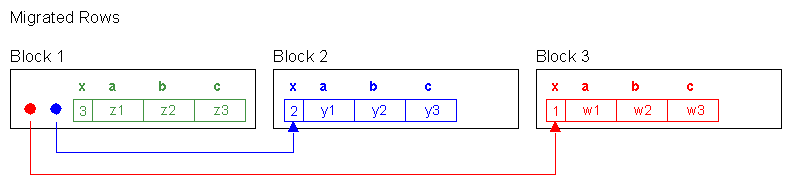
- --有趣的是,返回的结果是倒序的。是由于我们首先更新了第三行。此时并没有行迁行,但是它填充了整个数据块1。随着第二行的更新,它
- --不得不迁移到第2块,由于第3行几乎占用了整个块。当我们更新第一行的时候,它迁移到块3。最终使第三行数据保留在第一块。
- --因此,当oralce使用全表扫描时,它首先发现第3条记录在数据块1,第2条记录在数据块2,第1条记录在数据块3。当进行表扫描时,它忽略
- --第一块的头部信息是记录1,记录2的rowid信息。这就是为什么table fetch continued row依旧是零值的原因。此时没有行链接。
- --让我们来看一看对table fetch continued row的影响
- SELECT * FROM row_mig_chain_demo WHERE x = 3;
- X
- ----------
- 3
- SELECT a.name, b.value
- FROM v$statname a, v$mystat b
- WHERE a.statistic# = b.statistic#
- AND lower(a.name) = 'table fetch continued row';
- NAME VALUE
- ---------------------------------------------------------------- ----------
- table fetch continued row 0
- --这是一个索引范围扫描方式,然后根据主键获得rowid。此时并没有增加table fetch continued row的值,因此记录3并没有发生行迁移。
- UPDATE row_mig_chain_demo SET d = 'z4', e = 'z5' WHERE x = 3;
- COMMIT;
- --update之后记录3新增的内容不在填充到数据块1,因为列d和e之和是5k,因此行链接产生了。
- SELECT x,a FROM row_mig_chain_demo WHERE x = 3;
- X
- ----------
- 3
- SELECT a.name, b.value
- FROM v$statname a, v$mystat b
- WHERE a.statistic# = b.statistic#
- AND lower(a.name) = 'table fetch continued row';
- NAME VALUE
- ---------------------------------------------------------------- ----------
- table fetch continued row 1
- --当从记录3的头部提取列x和列a的时候,将不会产生table fetch continued row,也没有额外的I/O产生。
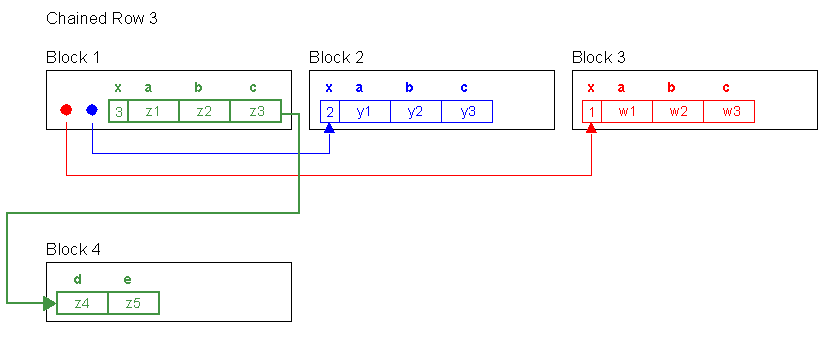
- SELECT x,d,e FROM row_mig_chain_demo WHERE x = 3;
- SELECT a.name, b.value
- FROM v$statname a, v$mystat b
- WHERE a.statistic# = b.statistic#
- AND lower(a.name) = 'table fetch continued row';
- NAME VALUE
- ---------------------------------------------------------------- ----------
- table fetch continued row 2
- --现在当我们通过主键索引扫描从记录3的尾部提取数据时,这将增加table fetch continued row的值。因为需要从行的头部和尾部获取数据来组合。
- --现在来看看全表扫描是否也有相同的影响。
- SELECT * FROM row_mig_chain_demo;
- X
- ----------
- 3
- 2
- 1
- SELECT a.name, b.value
- FROM v$statname a, v$mystat b
- WHERE a.statistic# = b.statistic#
- AND lower(a.name) = 'table fetch continued row';
- NAME VALUE
- ---------------------------------------------------------------- ----------
- table fetch continued row 3
- --此时table fetch continued row的值被增加,因为不得不对记录3的尾部进行融合。而记录1和2即便是存在迁移现象,但由于是全表扫描,
- --因此不会增加table fetch continued row的值。
- SELECT x,a FROM row_mig_chain_demo;
- X
- ----------
- 3
- 2
- 1
- SELECT a.name, b.value
- FROM v$statname a, v$mystat b
- WHERE a.statistic# = b.statistic#
- AND lower(a.name) = 'table fetch continued row';
- NAME VALUE
- ---------------------------------------------------------------- ----------
- table fetch continued row 3
- --当需要提取的数据是整个表上的头两列的时候,此时table fetch continued row也不会增加。因为不需要对记录3进行数据融合。
- SELECT x,e FROM row_mig_chain_demo;
- X
- ----------
- 3
- 2
- 1
- SELECT a.name, b.value
- FROM v$statname a, v$mystat b
- WHERE a.statistic# = b.statistic#
- AND lower(a.name) = 'table fetch continued row';
- NAME VALUE
- ---------------------------------------------------------------- ----------
- table fetch continued row 4
- --但是当提取列d和e的时候,table fetch continued row的值被增加。通常查询时容易产生行迁移即使是真正存在行链接,因为我们的查询
- --所需的列通常位于表的前几列。
八、如何鉴别行链接和行迁移
- --聚合统计所创建的表,这也将使得重构整行而发生table fetch continued row
- SELECT count(e) FROM row_mig_chain_demo;
- COUNT(E)
- ----------
- 1
- SELECT a.name, b.value
- FROM v$statname a, v$mystat b
- WHERE a.statistic# = b.statistic#
- AND lower(a.name) = 'table fetch continued row';
- NAME VALUE
- ---------------------------------------------------------------- ----------
- table fetch continued row 5
- --通过analyze table来校验表上的链接数
- ANALYZE TABLE row_mig_chain_demo COMPUTE STATISTICS;
- SELECT chain_cnt
- FROM user_tables
- WHERE table_name = 'ROW_MIG_CHAIN_DEMO';
- CHAIN_CNT
- ----------
- 3
- --3条记录是链接的。显然,他们中的两条记录是迁移(记录1,记录2)和一记录是链接(记录3).
- --实例启动后的table fetch continued row的总数
- --视图v$mystat告诉我们自从实例启动后,所有的表上共有多少次为table fetch continued row.
- sqlplus system/<password>
- SELECT 'Chained or Migrated Rows = '||value
- FROM v$sysstat
- WHERE name = 'table fetch continued row';
- Chained or Migrated Rows = 31637
- --上面的查询结果表明,可能有1个表上存在行链接被fetch了31637次,也可能有31637个表,每个表上有一个行链接,每次fetch一次。也有
- --可能是上述情况的组合。
- --31637次也许是好的,也许是坏的,仅仅是一个值而已。
- --这取决于
- --数据库启动了多久?
- --这个值占总提取数据百分比的多少行?
- --假如它占据了你从表上fetch的0.001%,则无关紧要。
- --因此,比较table fetch continued row与总提取的记录数是有必要的
- SELECT name,value FROM v$sysstat WHERE name like '%table%';
- NAME VALUE
- ---------------------------------------------------------------- ----------
- table scans (short tables) 124338
- table scans (long tables) 1485
- table scans (rowid ranges) 0
- table scans (cache partitions) 10
- table scans (direct read) 0
- table scan rows gotten 20164484
- table scan blocks gotten 1658293
- table fetch by rowid 1883112
- table fetch continued row 31637
- table lookup prefetch client count 0
九、一个表上链接的行是多少?
- --通过对表analyze后(未analyze是空值),可以从数据字典user_tales获得链接的记录数。
- ANALYZE TABLE row_mig_chain_demo COMPUTE STATISTICS;
- SELECT chain_cnt,
- round(chain_cnt/num_rows*100,2) pct_chained,
- avg_row_len, pct_free , pct_used
- FROM user_tables
- WHERE table_name = 'ROW_MIG_CHAIN_DEMO';
- CHAIN_CNT PCT_CHAINED AVG_ROW_LEN PCT_FREE PCT_USED
- ---------- ----------- ----------- ---------- ----------
- 3 100 3691 10 40
- --PCT_CHAINED 为100%,表明所有的行都是链接的或迁移的。
十、列出链接行
当使用analyze table中的list chained rows子句能够列出一个表上的链接行。该命令的结果是将所有的链接上存储到一个由list chained rows子句 显示指定的表中。 这些结构有助于决定是否将来有足够的空间实现行更新。 创建CHAINED_ROWS 表 创建一个用于存储analyze ... list chained rows命令结果的表,可以执行位于$ORACLE_HOME/rdbms/admin目录下的UTLCHAIN.SQL或UTLCHN1.SQL 脚本。 这个脚本会在当前schema下创建一个名为chained_rows的表 create table CHAINED_ROWS ( owner_name varchar2(30), table_name varchar2(30), cluster_name varchar2(30), partition_name varchar2(30), subpartition_name varchar2(30), head_rowid rowid, analyze_timestamp date );
当chained_rows表创建后,可以使用analyze table命令来指向该表作为输出。
十一、如何避免行链接和行迁移 增加pctfree能够帮助避免行链接。如果我们为块留下更多的可用空间,则行上有空间满足将来的增长。也可以对那些有较高删除率的表采用重新组织 或重建表索引来避免行链接与行迁移。如果表上有些行被频繁的删除,则数据块上会有更多的空闲空间。当被插入的行后续扩展,则被插入的行可能会 分布到那些被删除的行上而仍然没有更多空间来用于扩展。重新组织表则确保主要的空闲空间是完整的空块。 ALTER TABLE ... MOVE 命令允许对一个未分区或分区的表上的数据进行重新分配到一个新的段。也可以分配到一个有配额的不同的表空间。该命令也允许 你在不能使用alter table的情形下来修改表或分区上的一些存储属性。也可以使用ALTER TABLE ... MOVE 命令中的compress关键字在存储到新段时使用压缩选项。
-
name="code" class="sql">1. ALTER TABLE MOVE
关注打赏



微信扫码登录