
欢迎点击「算法与编程之美」↑关注我们!
本文首发于微信公众号:"算法与编程之美",欢迎关注,及时了解更多此系列文章。
初识爬虫
入门编程的小白们总是对计算机领域的各种“黑科技”感到好奇,其中“爬虫”对于小白来说算是一个高大上的技术,所以今天我将为大家揭开爬虫神秘的面纱,同时带领大家和我一起写一个简单爬虫小程序。下面就让我们我们一起来学习爬虫吧。
爬虫的定义
网络爬虫是一种按照一定的规则自动爬取爬取网络信息的程序或者脚本。简单来说,网络爬虫就是就是根据一定的算法实现编程开发,主要通过URL实现数据的抓取和发掘。
爬虫的类型和原理
通用爬虫又称全网爬虫,爬行对象从一些初始URL扩充到整个网站。其实现的原理如图:
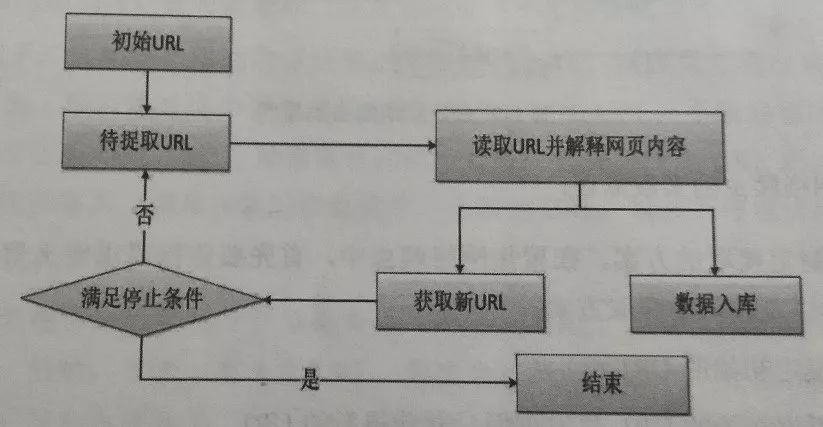
首先获取初始化URL。初始化的URL地址可以人为的指定,也可以由用户指定的某个或者几个初始爬取网页决定。然后根据初始的URL地址爬取页面的信息,之后解析网页信息内容,将网页存储到原始数据库中,并且在当前获取的网页信息里发现新的URL地址,存放于一个URL队列里面。下面再从URL队列当中读取新的URL,从而获取新的网页信息,同时在新的网页中获得新的URL,并重复上述的爬取过程,满足爬虫系统设置的停止条件时,爬取停止。
聚焦网络爬虫又称主题网络爬虫,是选择性地爬行根据需求的主题相关页面的网络爬虫。
聚焦网络爬虫的执行原理和过程与通用爬虫大致相同,在通用爬虫的基础上增加两个步骤:定义爬取目标和筛选过滤URL,原理大致如图:
 增量式网络爬虫是指对已下载网页采取增量式更新和只爬行新产生或者已经发生变化的网页的爬虫,它能够在一定程度上保证所爬行的页面尽可能是新的页面。
增量式网络爬虫是指对已下载网页采取增量式更新和只爬行新产生或者已经发生变化的网页的爬虫,它能够在一定程度上保证所爬行的页面尽可能是新的页面。
深层网络爬虫是大部分内容不能通过静态URL获取的、隐藏在搜索表单后的、只有用户提交一些关键词才能获得的网络页面。
实践操作
在了解完了网络爬虫的原理我们下面就进入实战环节吧

运行程序后会在文件同级目录下生成爬取的文件。大家赶紧试试吧。
下周将为大家讲解urllib,并且将持续更新相关的爬虫文章哦,希望大家多多关注,一起点个赞吧。
主 编 | 张祯悦
责 编 | 官学琦
where2go 团队
微信号:算法与编程之美

长按识别二维码关注我们!
温馨提示:点击页面右下角“写留言”发表评论,期待您的参与!期待您的转发!

