
欢迎点击「算法与编程之美」↑关注我们!
本文首发于微信公众号:"算法与编程之美",欢迎关注,及时了解更多此系列文章。
你是否还在用老套的方式网页打开数据?你是否想要打造一个属于自己的翻译程序?
看完这篇博客实现你的梦想,打造一个属于自己的翻译器。
首先要导入两个库爬虫库(requests)和json库。Requests库就不多讲了,了解爬虫的观众老爷们都懂用于爬取网络数据,Json库再这个程序的主要作用是解析爬取的json文件,达到提取数据的作用。
接下来开始打开百度翻译网页获取网页翻译的地址,在获取网页地址时要注意那部分或是在哪里获取有效地址。接着在网页中我们鼠标右键单机网页内任意一处弹出对话框选择“检查”选项
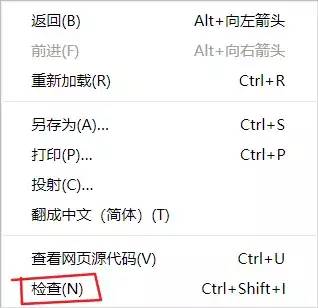
接着通过在网页中输入翻译的内容再进行下图所示的所有操作
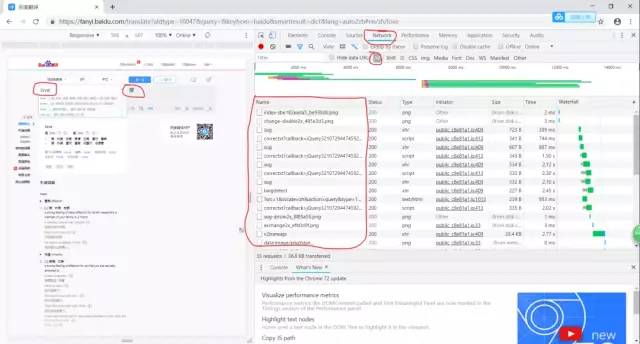
完成上一步操作我们通过逐个点击Name列的信息查找到我们所需要得到的信息如下图所示
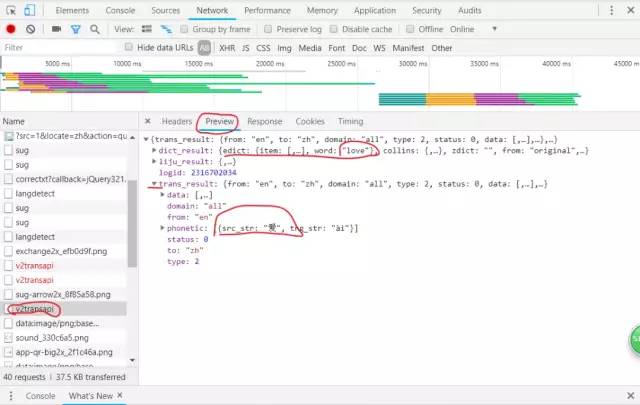
看到有我们想要的信息就说明我们找对地方了,我们开始点击Headers观察显示的信息如图,请求方式为post,所以我们需要找到爬虫需要的代理(User-Agent)和Form data表单。通过post请求返回爬取的数据。
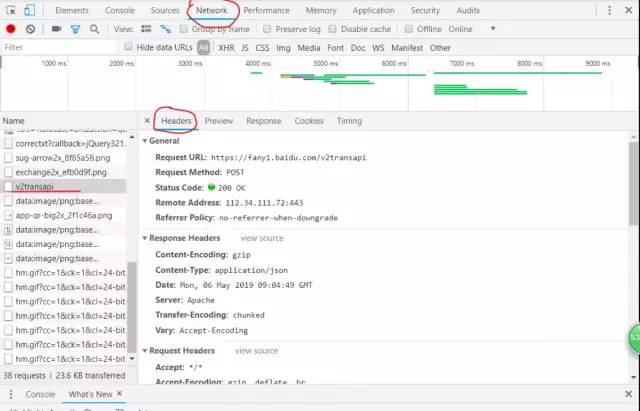
到这里我们只用到了requests库接下来我们就要用到json库了,爬取返回的数据需要用到json.loads()函数处理,得到如下图所属的信息。
注:json.loads()函数的作用:将已编码的 JSON 字符串解码为 Python 对象。
在这里我们可以看到这里面有我们输入翻译的内容和结果。我们最后就通过索引列表字典和列表的下标返回翻译结果。
完整的代码如下图所示(此程序代码运行只能由中文翻译成英文)
#导入需要用到的库request库爬取网络数据,json库转换文件格式
import requests
import json
while True:
string=input("请输入待翻译的内容:")
#百度翻译的网址
url="https://fanyi.baidu.com/transapi"
#构建头部,构建form表单数据发送post请求
headers={"User-Agent": "Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Mobile Safari/537.36"}
data={
"from": "zh",
"to": "en",
"query":string,
"transtype": "realtime",
"simple_means_flag": "3",
"sign": "198772.518981",
"token": "65430217bbbc3c3c3e8eee164650cefd"
}
response=requests.post(url=url,data=data,headers=headers)
html=response.content.decode()
#得到的html是json文件格式的内容,所以之后用json提取数据
html=json.loads(html)
rep=html["data"][0]["dst"]
print("翻译的结果:",rep)
代码写完了,最后之差将代码转化为桌面程序。那么如何实现呢?
这里我们需要安装python的另外两个第三方库pywin32和pyinstaller,安装的具体操作我们不详细说明,不懂的读者可以去百度一下。
安装完成我们要进入cmd窗口里面进入上述程序的文件夹,代码如下

程序运行完成会在代码文件夹下生成多个文件,而打包成的exe文件就存在与dist文件下。
希望大家喜欢这篇博客,如果正在看博客的你也觉得博客不错,就点赞留言转发吧。谢谢大家关注。
where2go 团队
微信号:算法与编程之美

长按识别二维码关注我们!
温馨提示:点击页面右下角“写留言”发表评论,期待您的参与!期待您的转发!

