
欢迎点击「算法与编程之美」↑关注我们!
本文首发于微信公众号:"算法与编程之美",欢迎关注,及时了解更多此系列文章。
《权利的游戏》、《天赋异禀》等耳熟能详的美剧,面对如此繁多的美剧,此时不禁会问自己,我喜欢看什么美剧呢?
这是一个非常难以回答的问题,原因在于不同的人会有不同的偏好。为了简化问题的求解,我们将尝试用Python语言进行数据分析来回答"我喜欢看什么美剧",先限定下主题就是我自己。
为了搞明白我喜欢看什么美剧,前提是要知道目前有哪些美剧,然后才能在这些美剧中根据条件筛选出我喜欢看的。所以第一件事要做的就是采集基本的数据。
Python实现数据采集需要用到的第三方库有requests和bs4,其中requests用来处理HTTP请求,bs4中的BeautifulSoup用来解析下载的HTML代码从中得到想要的数据。
1. 安装第三方库。
利用包管理软件pip来完成第三方库的安装。
pip install requests pip install bs4
2. 利用requests库下载HTML代码。
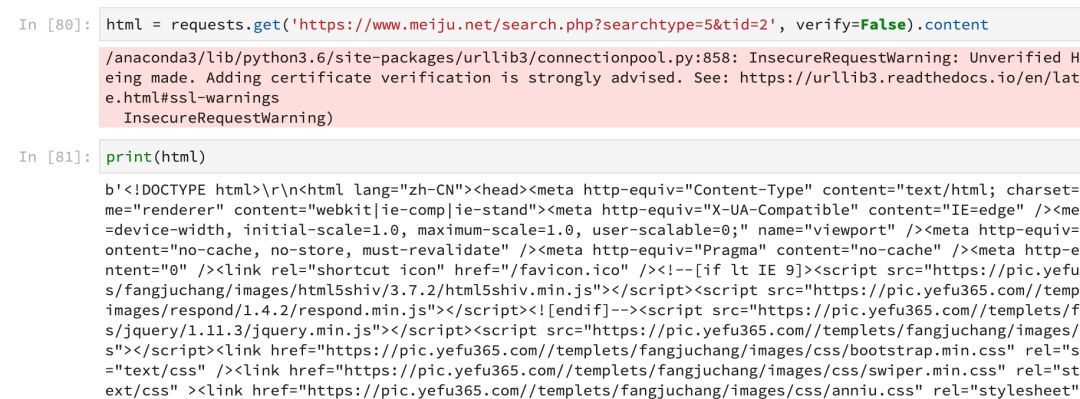
html = requests.get('https://www.meiju.net/search.php?searchtype=5&tid=2', verify=False).content
3. 利用BeautifulSoup解析HTML。
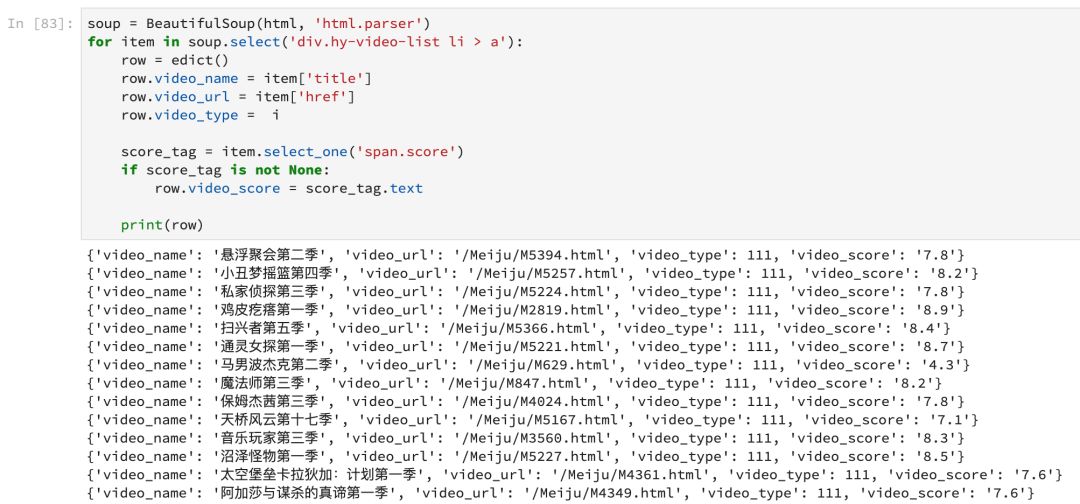
soup = BeautifulSoup(html, 'html.parser')
for item in soup.select('div.hy-video-list li > a'):
row = edict()
row.video_name = item['title']
row.video_url = item['href']
row.video_type = i
score_tag = item.select_one('span.score')
if score_tag is not None:
row.video_score = score_tag.text
print(row)
4. 批处理所有列表。
for i in tqdm(range(1, 112)):
url = 'https://www.meiju.net/search.php?page={}&searchtype=5&tid=2'.format(i)
soup = BeautifulSoup(requests.get(url, verify=False).content, 'html.parser')
for item in soup.select('div.hy-video-list li > a'):
row = edict()
row.video_name = item['title']
row.video_url = item['href']
score_tag = item.select_one('span.score')
if score_tag is not None:
row.video_score = score_tag.text
print(row)
结语
where2go 团队
微信号:算法与编程之美

一个专注于分享算法思想的公众号!
温馨提示:点击页面下方“留言”发表评论,期待您的参与!期待您的转发!

