
从前面的分析我们知道,当下载的连接URL去重之后,就需要把URL放到下载器里进行下载,这样才会得到网页相关的数据,比如HTML、图片、脚本等等。然后我们根据网页再来抽取相关的数据,或者获得图片。接着下来,我们更进一步地来了解下载器是怎么样把URL的内容获取回来,明白整个数据取得的过程,对于我们了解爬虫过程也是有重要意义的。
从下图就可以了解整个下载器的初始化过程:
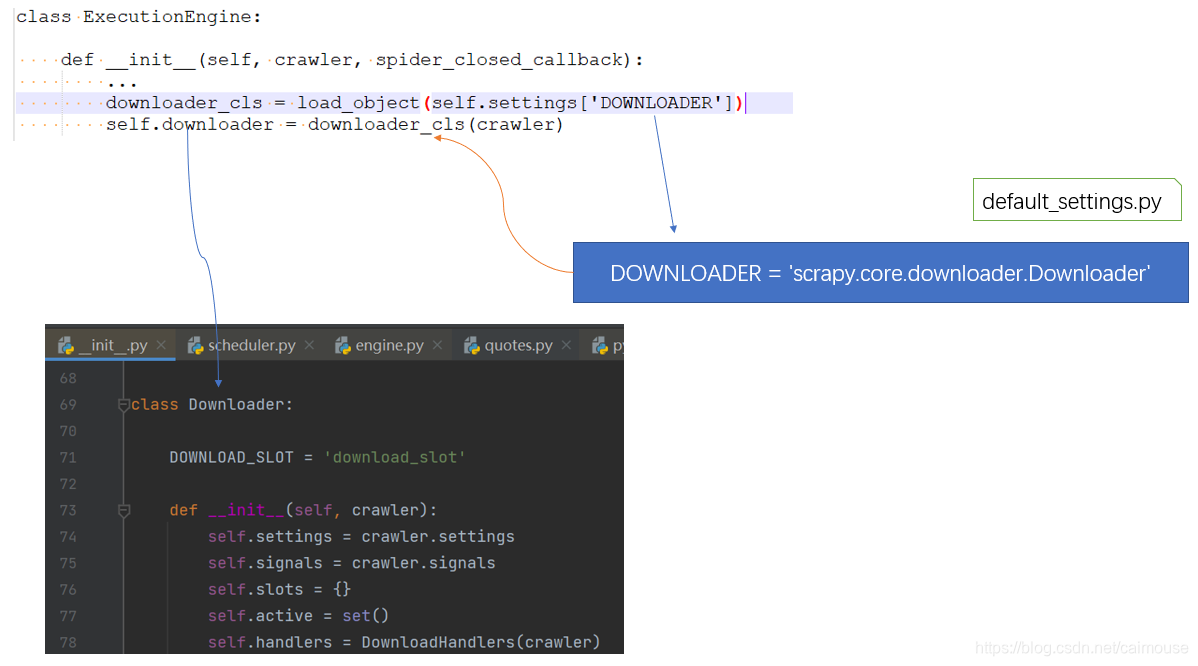
先从引擎的构造函数里进行初始化,它是从缺省的配置文件里加载参数DOWNLOADER,而这个参数里保存的是scrapy.core.downloader.Downloader,也就是下面的包目录:

