
目录
IP代理
代理的使用
Cookie
Cookie 使用方法
2.Cookie作为参数传入
3.使用session模块
Cookie 获取 requests中CookieJar的处理方法
ca 认证
MD5算法
IP代理- 透明代理:你可以直接“隐藏”你的IP地址,但还可以查到你是谁。
- 匿名代理:别人只知道你使用了代理,无法知道你真的是谁。
- 高匿名代理:别人根本无法发现你是用在代理
毫无疑问,高匿名代理效果最好
代理的使用import requests
url = "http://www.baidu.com"
proxies = {
"http":"http://222.78.6.70:8083", #ip 和 端口
#"https":"代理 地址"
}
respense = requests.get(url, proxies=proxies)
'''测试ip是否能用 返回200说明正常'''
print(respense.status_code)
国内高匿名免费代理
CookieCookie是一个存放对象的容器,里面都是 key:value 键值对形式的数据。cookie是被保存在浏览器上。
你进入某个网站,需要登录密码和帐号。你初次注册之后,登录,进入网站主页面。这时你的计算机就会自动保存一个cookie信息,该信息中包含你初次登录的账号和密码,当你下一次再登录这个网站时浏览器会自动取出计算机中相关的cookie信息,这样就不会出现登录页面而是直接跳转到网站主页。

Cookie 在登录的时候起作用
通过requests爬虫 爬取到登录之后的页面的数据,就必须要带着Cookie
Cookie 使用方法 1.把cookie放在headers里面import requests
url = "https://www.csdn.net/?spm=1001.2014.3001.4476"
# 将Cookie放在headers里面
headers = {
'user-agent': '对应的value值',
'cookie':'对应的value值'
}
respense = requests.get(url,headers=headers)
print(respense.status_code)
#生成html文件到本地
with open('rr.html','w',encoding='utf-8') as f:
f.write(respense.content.decode())
有cookie值后,进入页面不需要重新登录
无cookie值,还需要重新登录
2.Cookie作为参数传入import requests
url = "https://www.csdn.net/?spm=1001.2014.3001.4476"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36',
}
cookie = 'uuid_tt_dd=10_19936603830-1640090478464-699242; __gads=ID=08bc21f3f805f66c-225eb98181cf00ee:T=1640090802:RT=1640090802:S=ALNI_MbQm95Nqj2fxWZvf2AyYmK_5gxYxw; _ga=GA1.2.605852524.1640163067; p_uid=U010000; UserName=qq_61768489; UserInfo=aeffff694eab449aa402afd89623ce91; UserToken=aeffff694eab449aa402afd89623ce91; UserNick=ThnPkm; AU=8DC; UN=qq_61768489; BT=1640163165491; ssxmod_itna=Qqmx9D0DcADtiQiGHD8zRvh+Rw5BIhIKffXL5D/zWmDnqD=GFDK40ooOfKeo4e43inBT3hq0A7GhW=njbouN3Am4hc3bDCPGnDBFxQKmDYYkDt4DTD34DYDihQGIDieDF8NvzkDbxYQDYqGRDB=XzqDfmqGW8MQDmuNDGqKUD7QDIL=SBSrx6eDSKGU5zA=DjqTD/bxarA=oH6ae0wUrdaK4/DDH/Oy59AGsP+wPTgQ4oeGuDG=xkqGmlRR1hTXPZE343E548i4PF2wKDYvGci+x3ixR5Dx3If+5t0xRoV5QmAvdiDDAzGq7B4eGD4D=; ssxmod_itna2=Qqmx9D0DcADtiQiGHD8zRvh+Rw5BIhIKffX5G9ixkDBq+D7PdpgxmxGC8r+x8rFIFRSZirL5VKeM2GhVfxSoiItTb6gW3Q=ApkL6/RPw0wFclZ7dxe6Qld4O3TsejMbs=7b7fzcYVgwfBgvyQ+is9S0z0+XzSOmFlOE+Sbj73SAnfoToOquXDfYIIkRmFb3rvhoHbM6G9o=iLw0zR2oKT4euU3Y/0qa/mEreq8UCO+ysm2Gw7eaCdCNo2d35Hz8OMODq9oEzAG4viTrveQrbxqUEgCSXvIYRz7535WX+BMhm4Ro4FdZq0mxgXOcX2Gp/1UACmNgwAnNm1AQWimlKOppSYiotLwo0TDA59+pBvUjp2mPTtA6B5vQRn1fE=f=iYW6w6=Y0hTRlpr1ABrd62mNWfSxWxhNop2+7KagqqgeGCUTRvohvIm=372oIpeEvnYYGfG0QXxgwN7r4DF=c=BCbAfGq4+jEDLSFoPtBDFf9Qpep7P0XFF4BcDRcRjQqOELK7UIrKHfBfYPw6IG4DQKPR2rnHQ8D49RD30QGDbGmA6i0tiHBCqtZaorEMQy+h5Kqfrbb8Zkf1Q/GyGWK6GG3us710pLx/ijohGUrWiDxjbbthQli=YG4W/qjatKTAHuvuHbSUy508WDDFqD+cKAkzH0xeB=2hmNKsmmq5ODEQN5rHlkKY0OhkjxNj1uh/D1K7qB=QYNQD8yxRqhq/cPCDYYDD===; Hm_up_6bcd52f51e9b3dce32bec4a3997715ac=%7B%22islogin%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isonline%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isvip%22%3A%7B%22value%22%3A%220%22%2C%22scope%22%3A1%7D%2C%22uid_%22%3A%7B%22value%22%3A%22qq_61768489%22%2C%22scope%22%3A1%7D%7D; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=6525*1*10_19936603830-1640090478464-699242!5744*1*qq_61768489; c_dl_fref=https://so.csdn.net/so/search; c_dl_prid=1640503329187_668180; c_dl_rid=1640503332439_816509; c_dl_fpage=/download/weixin_38691319/13997089; c_dl_um=distribute.pc_search_result.none-task-download-2%7Eall%7Esobaiduweb%7Edefault-4-3943976.nonecase; c_first_ref=default; c_first_page=https%3A//blog.csdn.net/qq_61768489%3Fspm%3D1000.2115.3001.5343; c_segment=10; dc_sid=46b2120c6e3ba1aea095f96c5073417c; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1640250895,1640334225,1640502965,1640601079; c_hasSub=true; referrer_search=1640601277733; dc_session_id=10_1640603806712.255614; c_utm_term=cookie%E6%94%BE%E5%9C%A8headers%E9%87%8C%E9%9D%A2; c_utm_medium=distribute.pc_search_result.none-task-blog-2%7Eall%7Esobaiduweb%7Edefault-7-118465755.first_rank_v2_pc_rank_v29; c_page_id=default; log_Id_click=89; csrfToken=UW4wle5djZMlBgVuP3qa7zQZ; c_pref=https%3A//blog.csdn.net/qq_61768489%3Fspm%3D1000.2115.3001.5343; c_ref=https%3A//blog.csdn.net/qq_61768489%3Fspm%3D1001.2014.3001.5343; dc_tos=r4rv07; log_Id_pv=88; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1640605113; log_Id_view=350'
# 创建cookie列表
cookie_list = cookie.split('; ')
# 定义cookie字典
cookies = {}
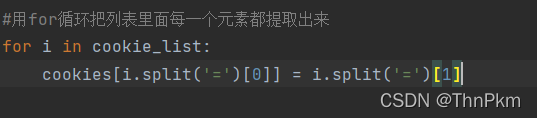
#用for循环把列表里面每一个元素都提取出来
for i in cookie_list:
cookies[i.split('=')[0]] = i.split('=')[1]
respense = requests.get(url,headers=headers,cookies=cookies)
print(respense.status_code)
#生成html文件到本地
with open('rr.html','w',encoding='utf-8') as f:
f.write(respense.content.decode())
cookie是这种形式,

split()方法是用来拆分字符串的,返回的数据类型是列表,当传入参数时,必须指定分割符。
split()方法详解
经过以上代码拆分后 得到是cookie字典

Session是另一种记录客户状态的机制,不同的是Cookie保存在客户端浏览器中,而Session保存在服务器上
客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上。这就是Session。客户端浏览器再次访问时只需要从该Session中查找该客户的状态就可以了
使用session登录开心网
import requests
# 使用requests生成一个session对象
session = requests.session()
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
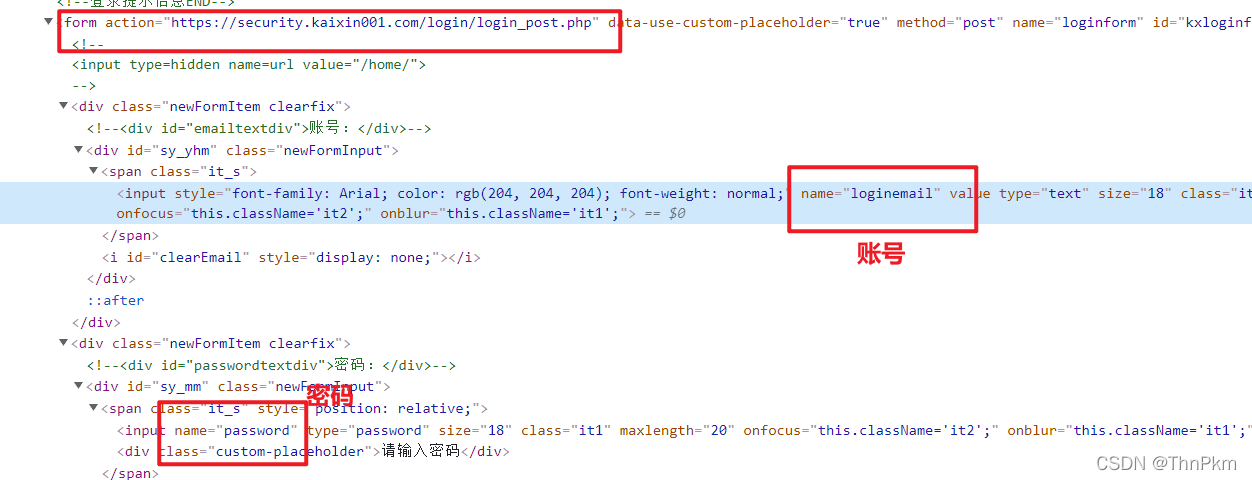
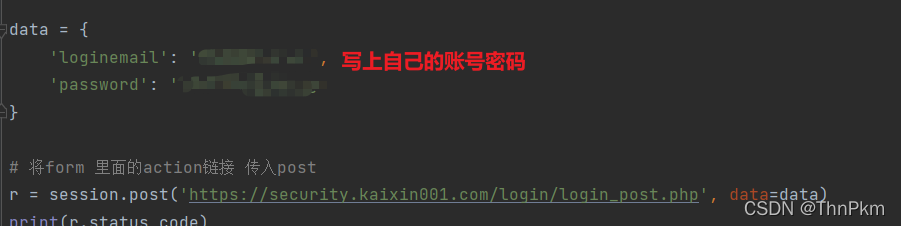
data = {
'loginemail': '你的账号',
'password': '你的密码'
}
# 将form 里面的action链接 传入post
respense = session.post('https://security.kaixin001.com/login/login_post.php', headers=headers, data=data)
# 保存网页到本地
with open('kx.html','w',encoding='utf-8') as f:
f.write(respense.content.decode())
运行后打开得到已经登录进去的首页
我们想要获取百度的cookie
import requests url = 'https://baidu.com' #发送请求,获取response response = requests.get(url) print(type(response.cookies))
得到RequestsCookieJar这么一个对象
要想获取里面的内容
import requests
url = 'https://baidu.com'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
#发送请求,获取response
response = requests.get(url,headers=headers)
print(type(response.cookies))
#使用方法从cookie jar中提取数据
from requests import utils
cookies = requests.utils.dict_from_cookiejar(response.cookies)
print(cookies)
返回可以用的cookie数据
ca 认证
某些https网站会出现如下报错
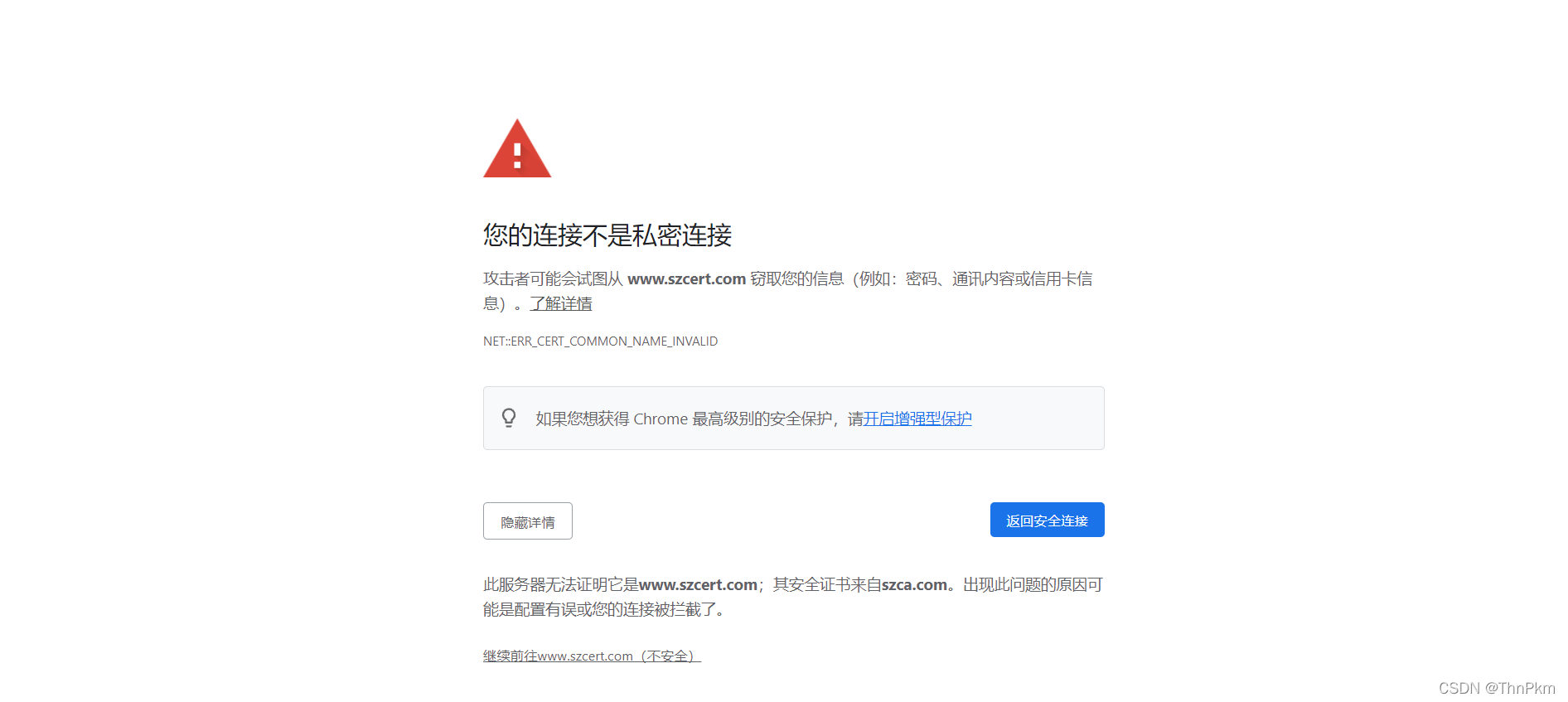
https 中的‘s’ 是SSL证书,只是没有经过ca的认证,所以也是可以进去的
用爬虫 爬取这种类型网站时
import requests url = 'https://www.szcert.com/' response = requests.get(url) print(response.status_code)
直接获取状态,会报错SSLError,认证失败

如何绕过认证呢 用 verify = False
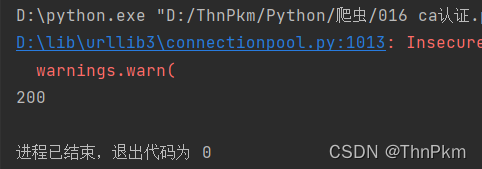
import requests url = 'https://www.szcert.com/' response = requests.get(url,verify=False) print(response.status_code)
成功,爆红只是警告 不影响 运行
MD5算法
MD5信息摘要算法,一种被广泛使用的密码散列函数,可以产生出一个128位(16字节)的散列值(hash value),用于确保信息传输完整一致。
import hashlib # 定义一个字符串 str01 = "python12345" # 表示用md5算法,生成一个md5对象 md5 = hashlib.md5() # 更新一下你要加密的数据,转换成二进制 md5.update(str01.encode()) #使用hexdigest方法获取 result = md5.hexdigest() print(result)
运行后得到
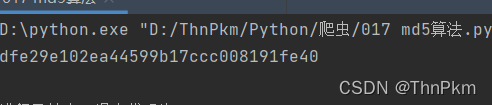
不论加密数据有多大,加密结果都是一样的长度
被称为信息摘要,一般作用于验证
比如:在网盘上传一个之前上传过的文件,无论文件大小都会秒传
这是因为网盘内会校验被md5加密过的数据,一样的话直接上传

