
1 requests库的深度应用
网页信息采集
import requests
if __name__=="__main__":
url=""
#将参数封装到字典中
kw=input("enter a word:")
param:{
'query':kw
}
#UA:User-Agent(请求载体的身份标识)
#UA伪装:让爬虫对应的请求载体身份标识伪装成一款浏览器
#UA伪装:将对应的User-Agent封装到一个字典中
headers:{
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:87.0) Gecko/20100101 Firefox/87.0'
}
requests.get(url=url,params=param,headers=headers)
page_text=requests.text
filename=kw+'html'
#保存为文件
with open(filename,'w',encoding='utf-8') as fp:
fp.write(page_text)
print('保存成功!')
重点:
反爬机制:
UA检测:相关的门户网站通过检测请求该网站的载体身份来辨别该请求是否为爬虫程序,如果是,则网站数据请求失败。因为正常用户对网站发起的请求的载体一定是基于某一款浏览器,如果网站检测到某一请求载体身份标识不是基于浏览器的,则让其请求失败。因此,UA检测是我们整个课程中遇到的第二种反爬机制,第一种是robots协议。
反反爬策略:
UA伪装:通过修改/伪装爬虫请求的User-Agent来破解UA检测这种反爬机制。
破解百度翻译-post请求(携带了参数)
-响应数据是json数据
AJAX
AJAX = Asynchronous JavaScript and XML(AJAX = 异步 JavaScript 和 XML。)。
AJAX 不是新的编程语言,而是一种使用现有标准的新方法。
AJAX 是一种用于创建快速动态网页的技术。
通过在后台与服务器进行少量数据交换,AJAX 可以使网页实现异步更新。这意味着可以在不重新加载整个网页的情况下,对网页的某部分进行更新。
传统的网页(不使用 AJAX)如果需要更新内容,必需重载整个网页面。
import requests
import json
if __name__=="__main__":
#1.指定url
post_url='https://fanyi.baidu.com/sug'
#2.UA伪装
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:87.0) Gecko/20100101 Firefox/87.0'
}
#3.post请求参数处理
data={
'kw':'dog'
}
#4.发送请求
response=requests.post(url=post_url,data=data,headers=headers)
#5.获取响应数据
dic_obj=response.json()
#6.持久化存储
fp=open('./dog.json','w',encoding='utf-8')
json.dump(dic_obj,fp=fp,ensure_ascii=False)
print('over')
方法:
json()
json.dump() 主要用来将python对象写入json文件
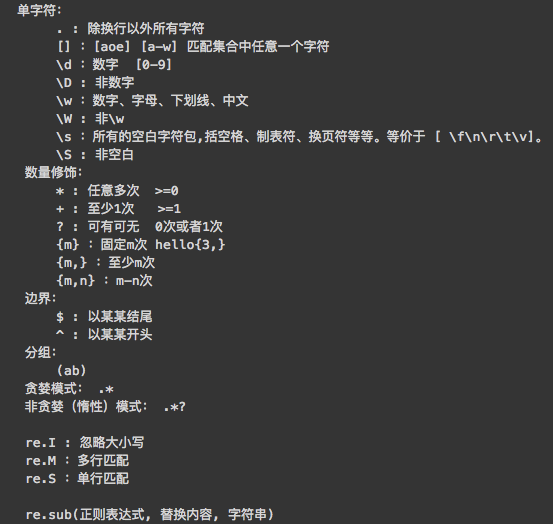
数据解析分类
-
正则
-
bs4
-
xpath(***)
数据解析原理概述
-
解析的局部文本内容都会在标签之间或者标签对应的属性中进行存储
-
1.进行指定标签的定位
-
2.标签或者标签对应的属性中存储的数据进行提取
import requests
if __name__=="__main__":
url="https://doge.zzzmh.cn/wallpaper/origin/b0fced9bf8864e88bb35b437b72f0c14.jpg"
#content 返回二进制形式的图片数据
# text(字符串) content(二进制) json() (
img_data=requests.get(url=url).content
with open ('./test.jpg','wb') as fp:
fp.write(img_data)
import requests
import re
import os
if __name__=="__main__":
if not os.path.exists('./bizhi'):
os.mkdir('./bizhi')
url="https://bz.zzzmh.cn/favorite"
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
}
page_text=requests.get(url=url,headers=headers).text
#print(page_text)
# use the focus crawler to crawl all wallpapers
ex='
关注
打赏
最近更新
- 深拷贝和浅拷贝的区别(重点)
- 【Vue】走进Vue框架世界
- 【云服务器】项目部署—搭建网站—vue电商后台管理系统
- 【React介绍】 一文带你深入React
- 【React】React组件实例的三大属性之state,props,refs(你学废了吗)
- 【脚手架VueCLI】从零开始,创建一个VUE项目
- 【React】深入理解React组件生命周期----图文详解(含代码)
- 【React】DOM的Diffing算法是什么?以及DOM中key的作用----经典面试题
- 【React】1_使用React脚手架创建项目步骤--------详解(含项目结构说明)
- 【React】2_如何使用react脚手架写一个简单的页面?

