
本课程共七个章节,课程地址:7周成为数据分析师(完结)_哔哩哔哩_bilibili
- 数据分析思维
- 业务知识
- Excel
- 数据可视化
- SQL
- 统计学
- Python
- Python的数据科学环境(P86)
- Python基础(P87-P97)
- 数据分析常用包:Numpy和Pandas(P98-P112)
- Python连接数据库(P113-P114)
- 数据分析案例(P115-P124)
- 数据可视化:Matplotlib和Seaborn(P125-P138)
- 数据分析平台(P139-P143)
目录(P103-P112)
第七周:Python(P86-P143)
三、数据分析常用包:Numpy和Pandas(P98-P112)
(四)pandas高阶(P103开始)
(五)pandas筛选
(六)pandas聚合(类似SQL中的group by)
(七)pandas多表关联
(八)pandas多重索引
(九)pandas预处理函数
(十)pandas apply
(十一)pandas 数据透视
三、数据分析常用包:Numpy和Pandas(P98-P112) (四)pandas高阶(P103开始)1. 读csv文件
import pandas as pd
# sep="\t"表示分隔符为\t,默认为,
# names=list("abcdefg")表示列名设置为abcdefg,此时原本的列名会变成第一行数据
df = pd.read_csv("dataAnalyst.csv", encoding="gbk", sep="\t", names=list("abcdefg"))
df
- 若只想预览前n行数据:
df.head(n) # n默认为5
- 若只想预览最后n行数据:
df.tail(n) # n默认为5
2. 更改某一列的数据类型
- 如把 top列 的数据类型从 int64 改为object(字符串)
df.top = df.top.astype('str')
3. 增加一列
df['avg_2'] = (df.bottom + df.top)/2
4. 查找符合要求的数据
- 平均薪资 > 15的那些岗位所在的城市
df.query('avg>15').city
- 平均薪资 > 15且在上海的岗位
df[(df.city=="上海")&(df.avg>15)]
5. 行列转置
df.T
1. 排序
- 按值进行排序
# 根据平均薪资排序(默认升序) df.sort_values(by='avg') # 写法2 df.avg.sort_values() # 降序 df.sort_values(by='avg', ascending=False) # 多条件排序 df.sort_values(['avg','city'], ascending=False)
- 按索引进行排序
df.sort_index()
- 排名
df['rank'] = df.avg.rank(ascending=False) # 降序后,avg越高,rank越前,符合正常认知 df
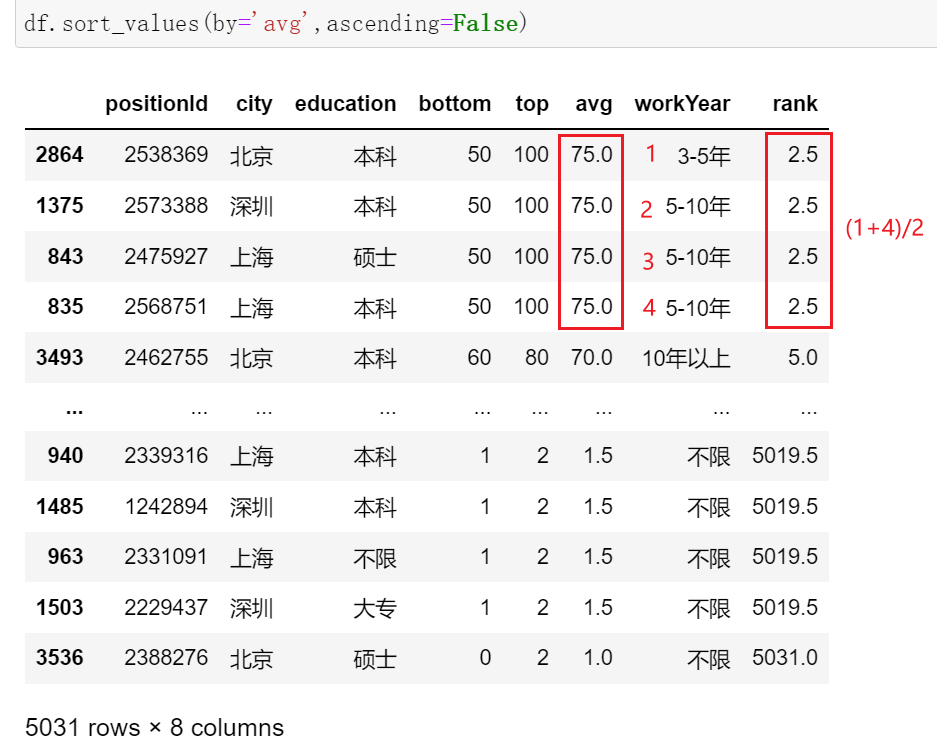 method参数默认值为 average
method参数默认值为 average
df['rank'] = df.avg.rank(ascending=False,method='min') df
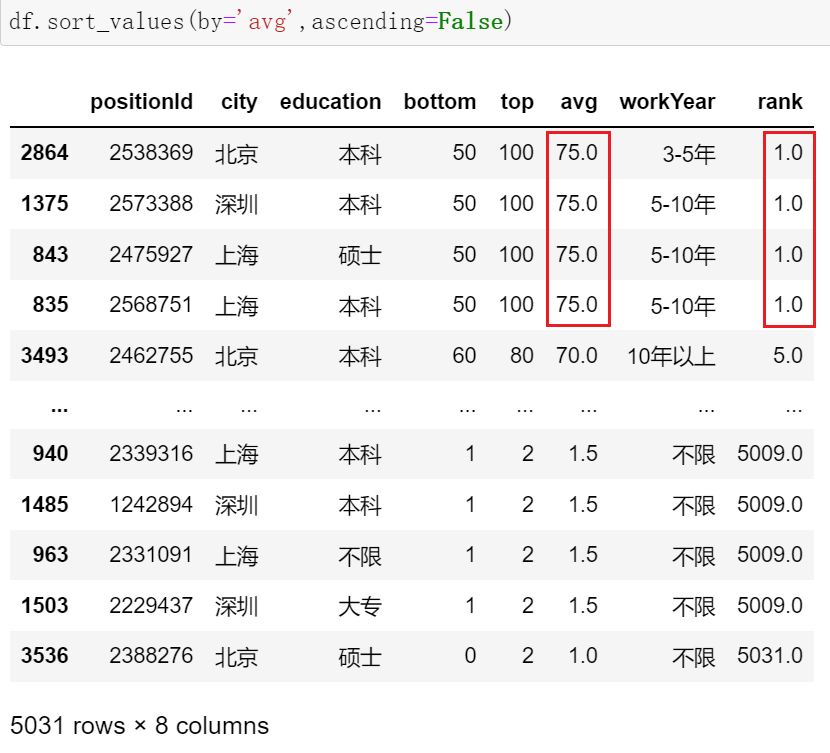
method还有 max、first(不考虑并列情况,值一样时按index排序)等
2. 重复值检测
- 查看总共有多少个唯一值
df.city.unique()

- 对唯一值出现次数进行计数
df.workYear.value_counts()

3. 描述性统计
df.describe()
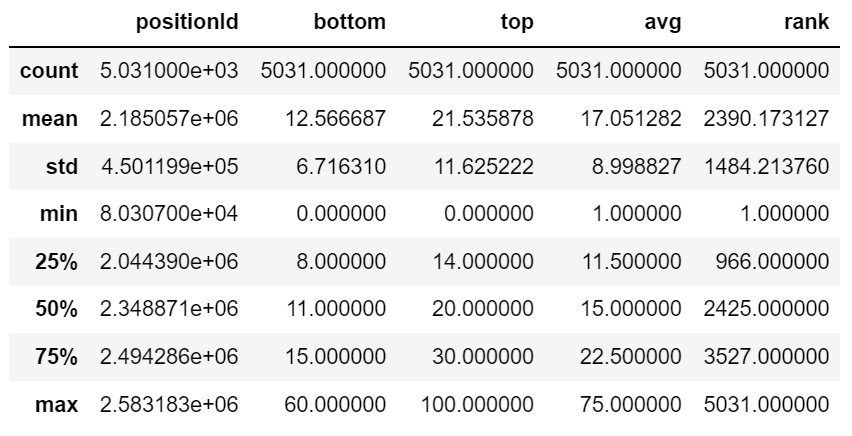
- 只想对某一列做描述性统计
df.avg.describe()
- 直接对 DataFrame 进行 count、max、min、sum、mean、median、std(标准差)、var(方差) 等也可以
df.count()
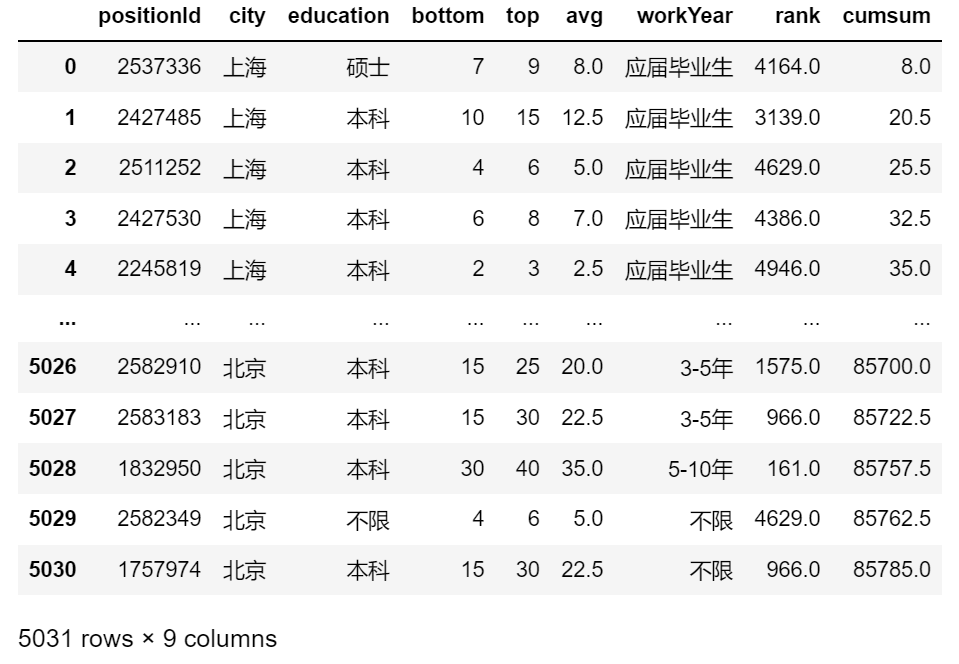
4. 累加
df['cumsum'] = df.avg.cumsum()
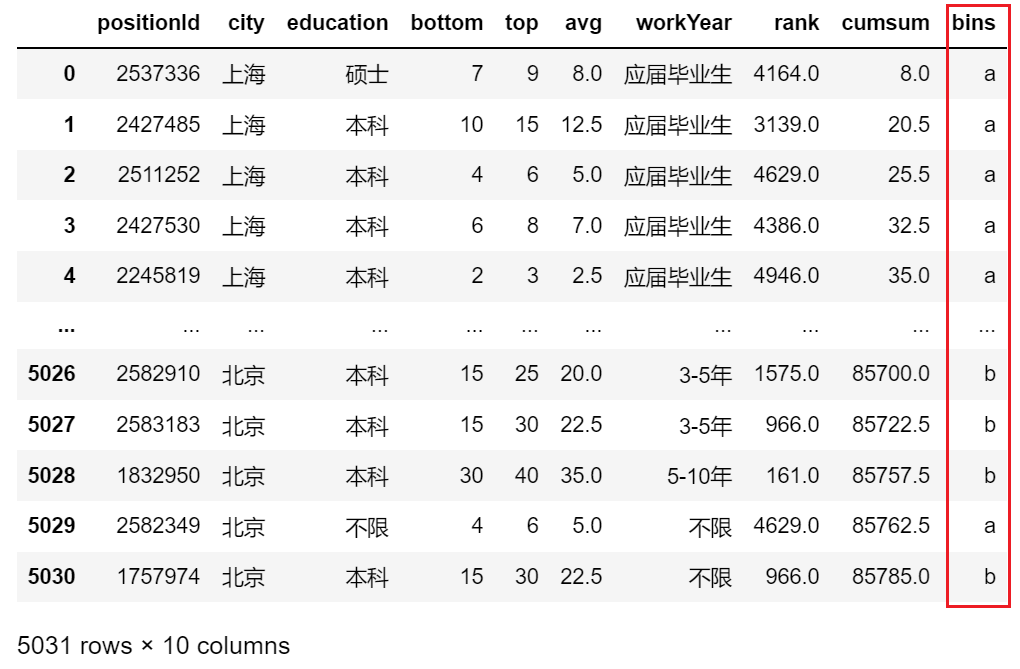
5. 分桶(必须是pd.cut(),而不是df.cut())
- 均匀分
df['bins'] = pd.cut(df.avg, bins=4, labels=list('abcd'),include_lowest=True) # 把avg均匀地四等分
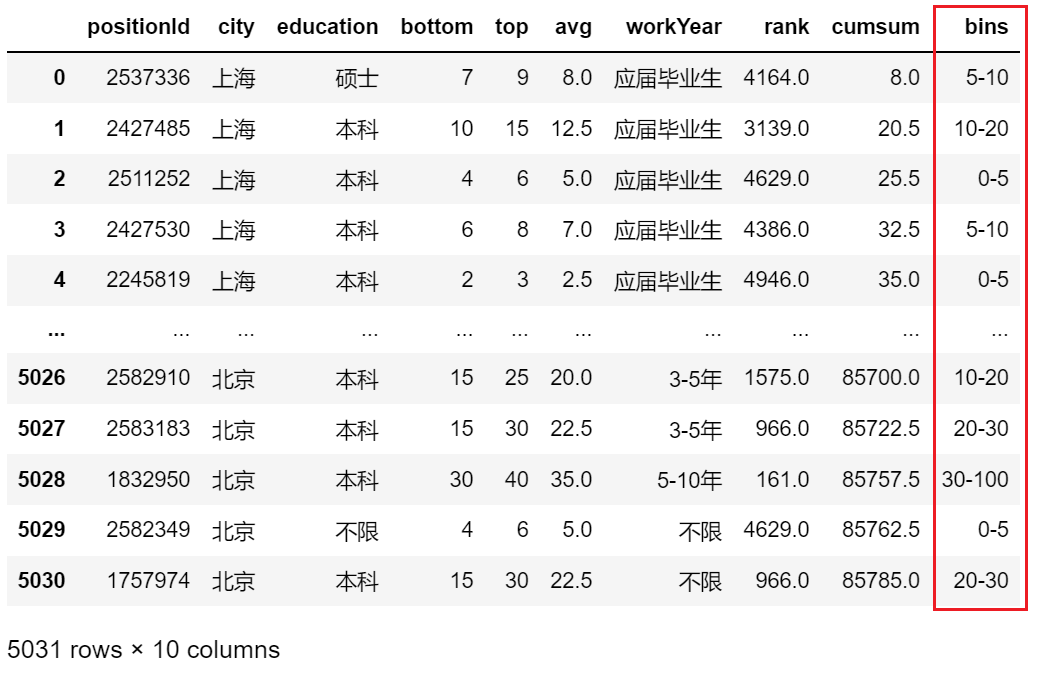
- 人工划分区间
df['bins'] = pd.cut(df.avg, bins=[0,5,10,20,30,100],labels=['0-5','5-10','10-20','20-30','30-100'])
- pd.qcut() 按分位数划分
df.groupby(by = 'city').count() # count()不对空值进行计数
1. 单字段聚合
- 统计不同城市平均薪资的最大值
df.groupby(by='city').avg.max()
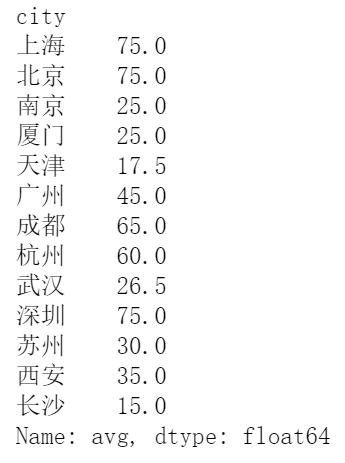
- 统计每个城市有多少元素
for k in df.groupby(by='city'):
print(k[0],len(k[1]))

- 统计不同城市最大薪资与最小薪资的差值
for k,v in df.groupby(by='city'): # k为city,v为每个city下的DataFrame
print(k,max(v.avg)-min(v.avg))
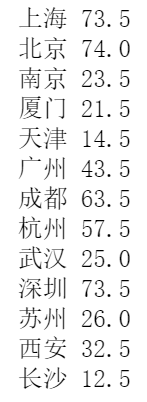
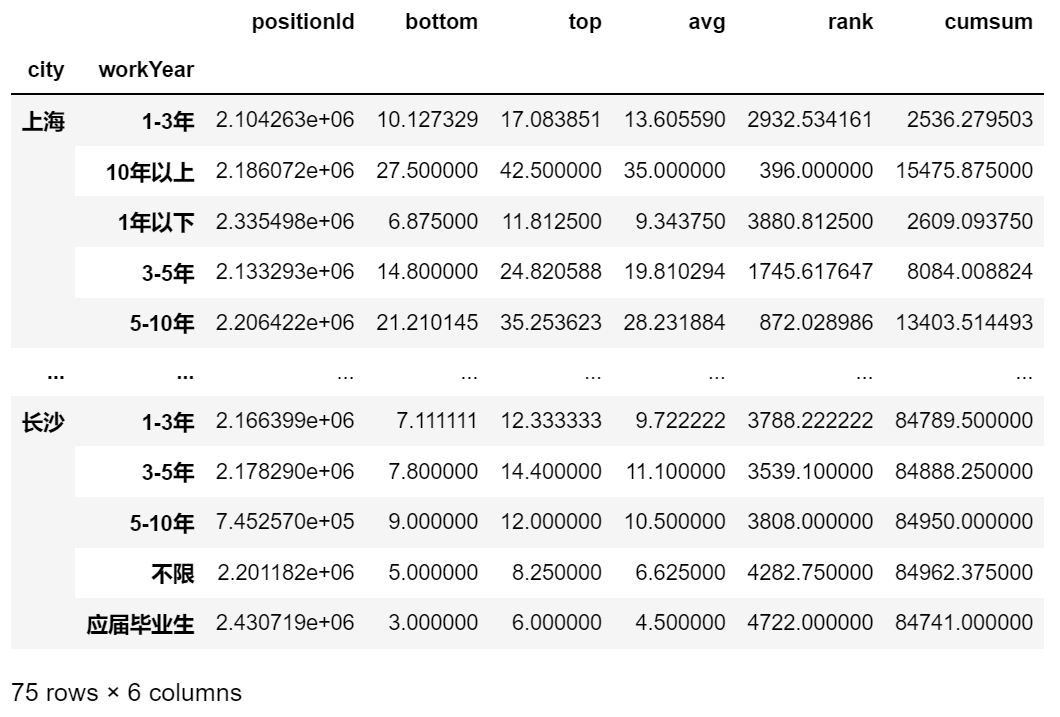
2. 多字段聚合(多重索引)
- 不同城市下不同工作年限的平均薪资的平均值
df.groupby(by=['city','workYear']).mean()
两张表:position_gbk.csv 和 company_utf.csv
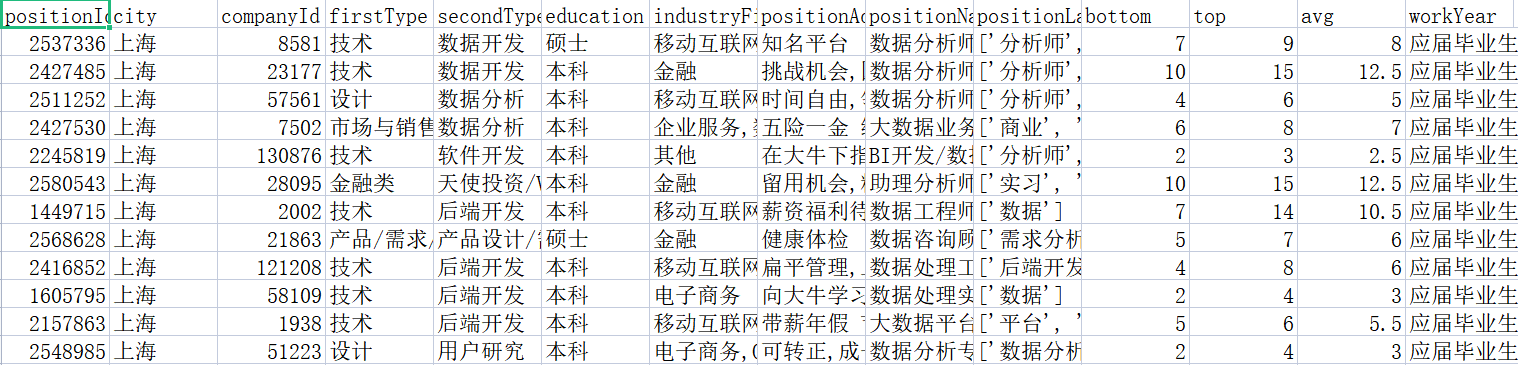 position_gbk.csv
position_gbk.csv company_utf.csv
company_utf.csv
pandas里有三种关联的方法:
- concat:字段全部合并,数据全部堆叠,没有默认为NaN(类似于SQL中的union)
- join:根据索引
- merge:根据具体某一列
1. merge()
position.merge(right=company, how='inner', on='companyId')
df.merge(right= , how= , on= , left_on= , right_on= )
- right:要和哪张表关联
- how:关联方式(inner默认、left、right)
- on:具体通过哪几列进行join(会自动只保留一列)
- left_on & right_on:两张表没有共同字段,连接两表时,左表的字段名和右表的字段名(都会保留)
更改字段名称:
- rename()
- columns()
将 company 表的 companyId 改为 id:
col = list(company.columns) col[0] = 'id' company.columns = col
此时联立两表:
position.merge(right=company, how='inner', left_on='companyId', right_on='id')
注:若是 pd.merge(),pd.merge(left=, right= , how= , on= , left_on= , right_on= )
2. join()
company.join(position)
3. concat()
pd.concat([company,position]) # 上下拼接 pd.concat([company,position],axis=1) # 左右拼接
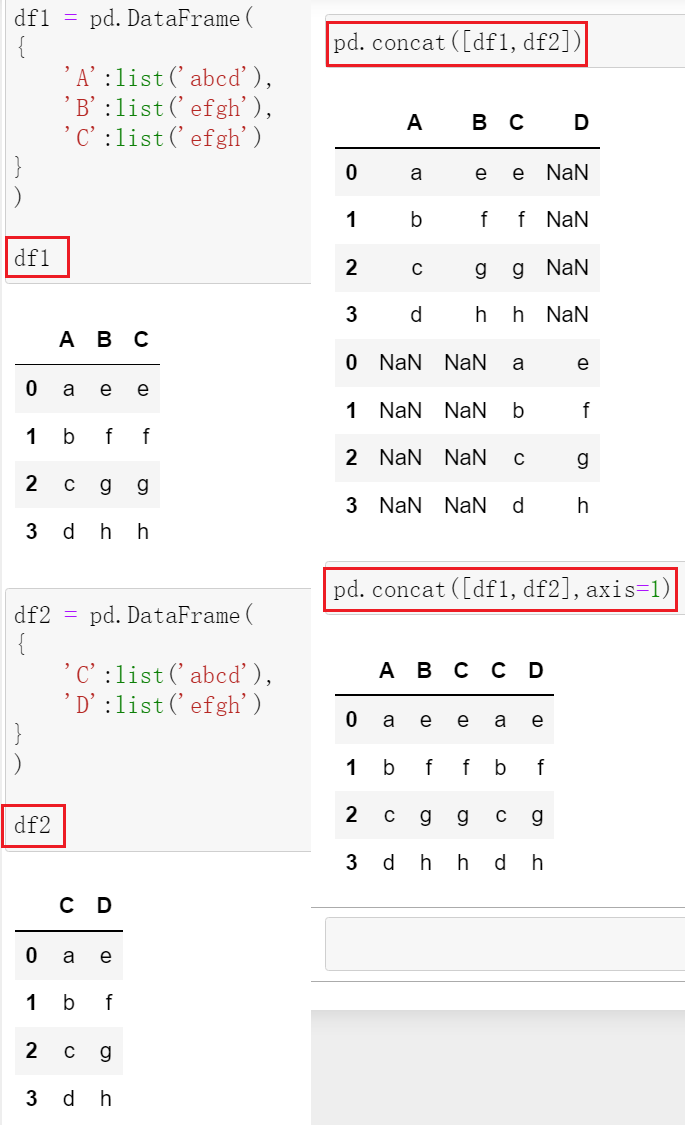
应用场景:所有月份的销售明细(字段相同)拼接
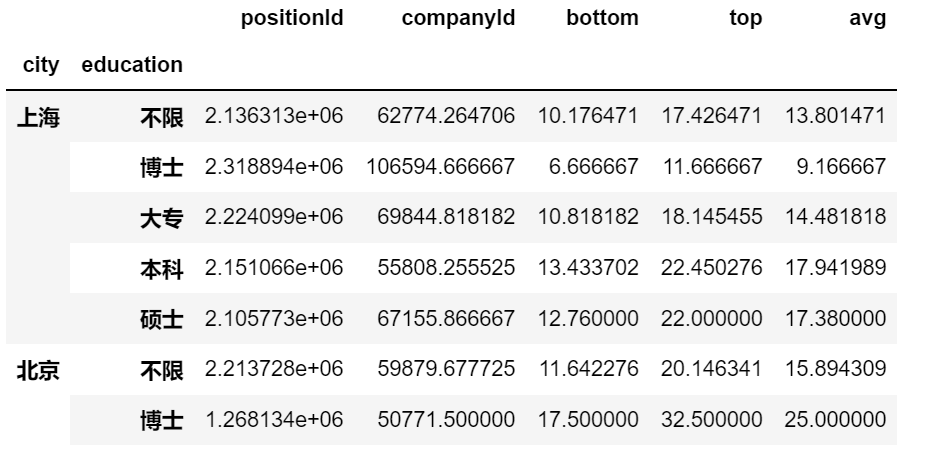
(八)pandas多重索引position = pd.read_csv('position_gbk.csv',encoding='gbk')
position.groupby(by = ['city','education']).mean()
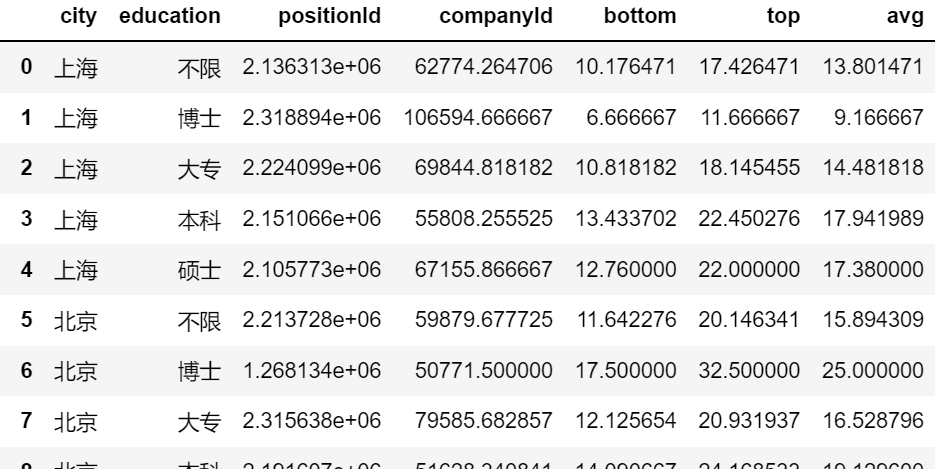
position.groupby(by = ['city','education']).mean().reset_index()
1. Series格式的索引

2. DataFrame格式的索引
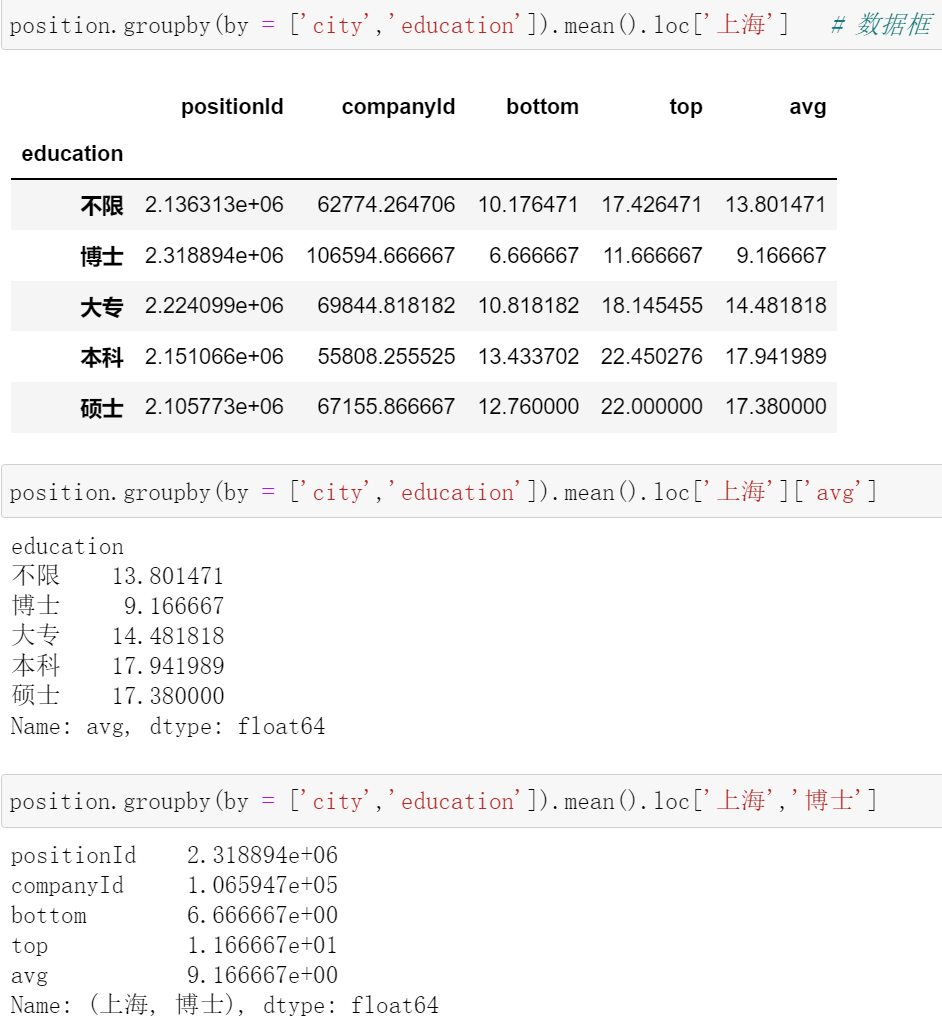
3. 不借助 group by 怎么设置多重索引?
position.sort_values(by=['city','education']).set_index(['city','education'])
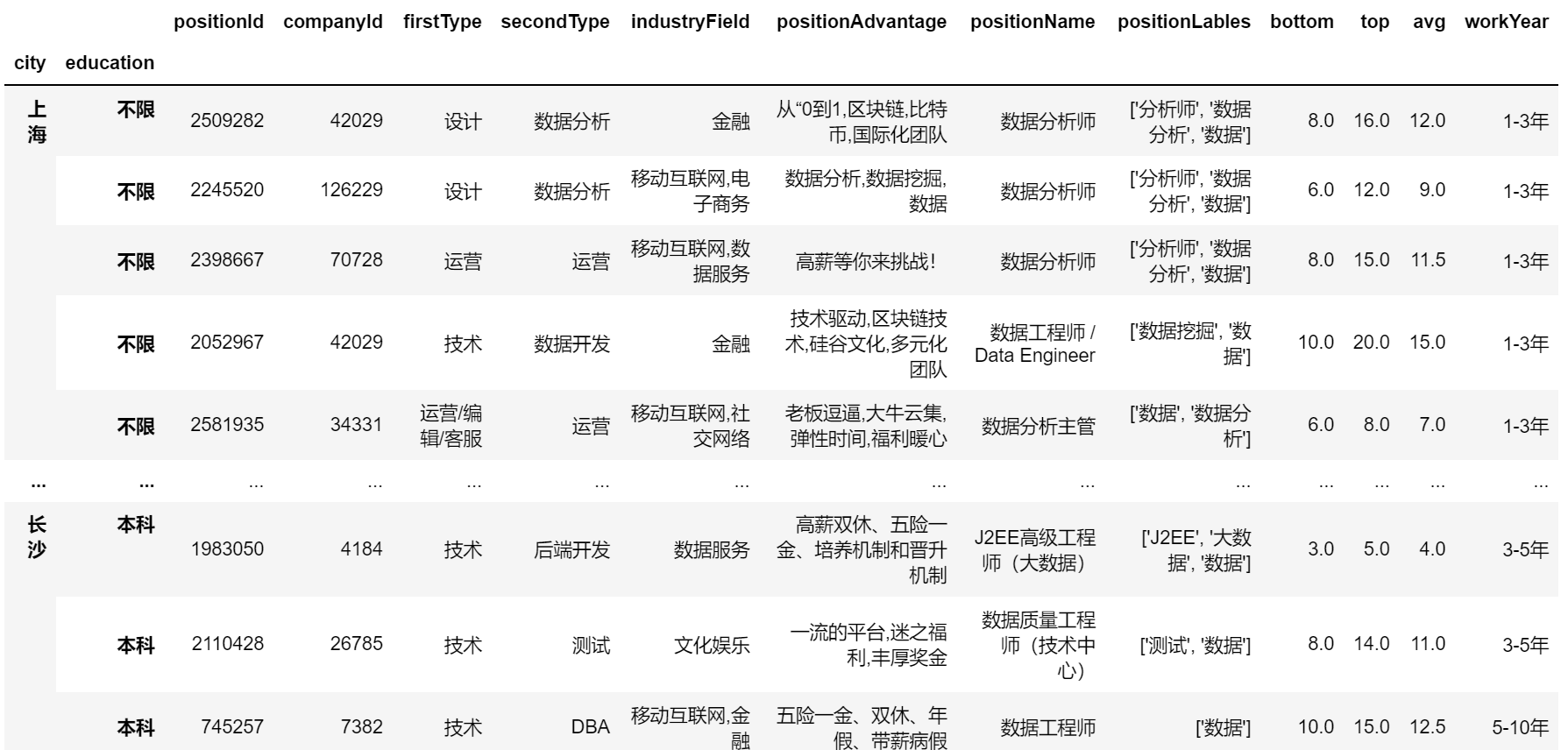
1. 文本函数
position = pd.read_csv('position_gbk.csv',encoding='gbk')
position.positionLables.str.count('分析师') # 统计“分析师”出现次数
position.positionLables.str.find('数据') # “数据”一词的出现位置,-1表示未出现

去掉外面的 [ ]:
position.positionLables.str[1:-1]
再去掉双引号:
position.positionLables.str[1:-1].str.replace("'","")

2. 空值
import numpy as np
position = pd.read_csv('position_gbk.csv',encoding='gbk')
position.loc[position.city == '深圳','city'] = np.NaN # 把“深圳”全部替换为NaN
对空值进行填充:
position = position.fillna('abc')
# 写法2
position.city = position.city.fillna('abc')
删除NaN:
position.dropna() # 删除所有有空值的行 position.dropna(axis=1) # 删除所有有空值的列
3. 重复值
- 过滤出重复数据
position[position.duplicated()]
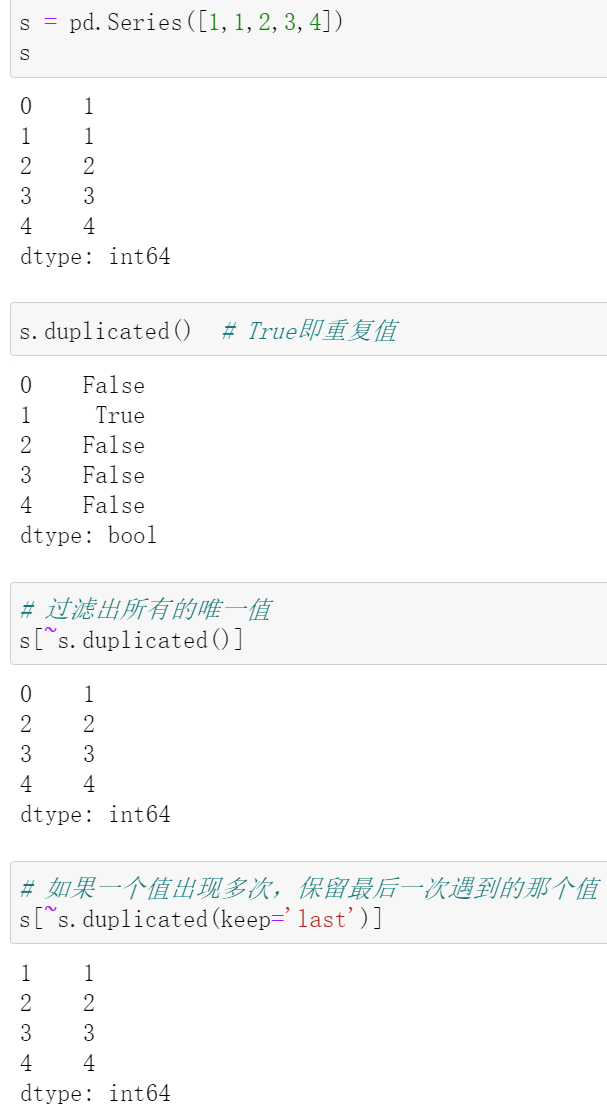
- 删除重复数据
s.drop_duplicates()

- 把一个自定义函数应用到所有行/列中
- 既可以针对Series,又可以针对DataFrame
1. 在 avg 列后面加上 k
position.avg.astype('str') + 'k'
# 写法2:
position.avg.apply(lambda x:str(x)+'k') # 匿名函数
# 写法3:
def func(x):
return str(x)+'k'
position.avg.apply(func)
position.apply(func, axis=)
- axis=0:应用函数对所有列
- axis=1:应用函数对所有行
2. 将 avg 列根据 20 划分档次
def func():
if x.avg>20:
return '20+k'
else:
return '0-20k'
positon.apply(func, axis=1) # 逐行
# 写法2
def func(x):
if x>20:
return '20+k'
else:
return '0-20k'
position.apply(lambda x:func(x.avg), axis=1)
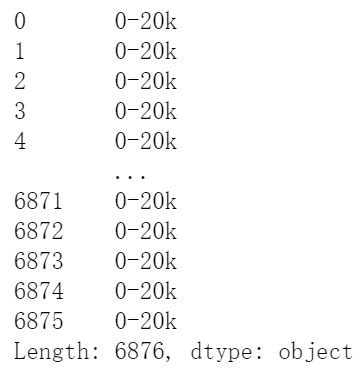
3. 将 avg 列平方
position.avg.apply(lambda x:x*x)
4. apply与聚合函数
注:position.groupby('city') 之后,每个 city 都形成一个DataFrame
position.sort_values('avg',ascending=False)[:5] # 降序
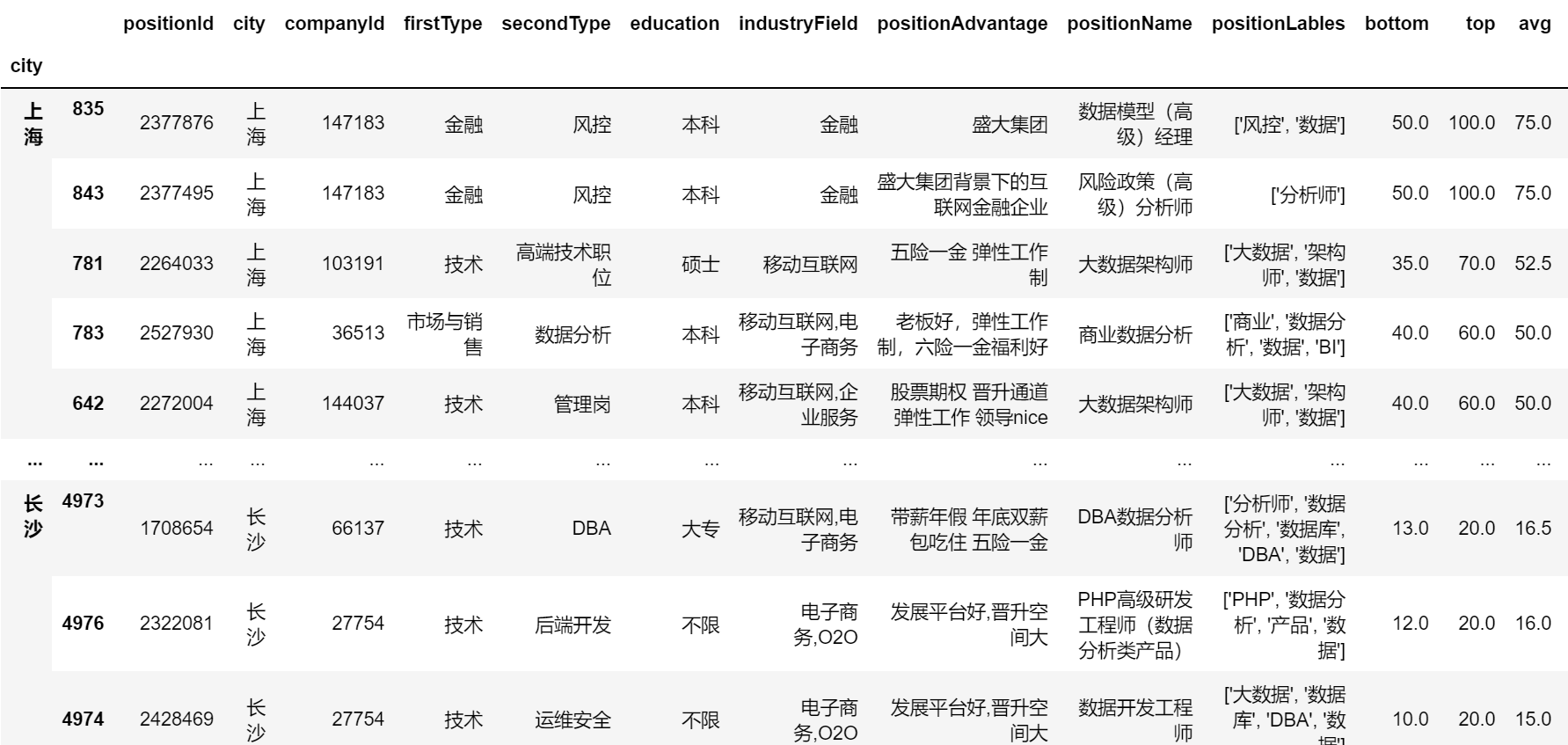
求出不同城市下薪资排名前五的岗位:
def func(x):
r = x.sort_values('avg', ascending=False)
return r[:5]
position.groupby('city').apply(func)
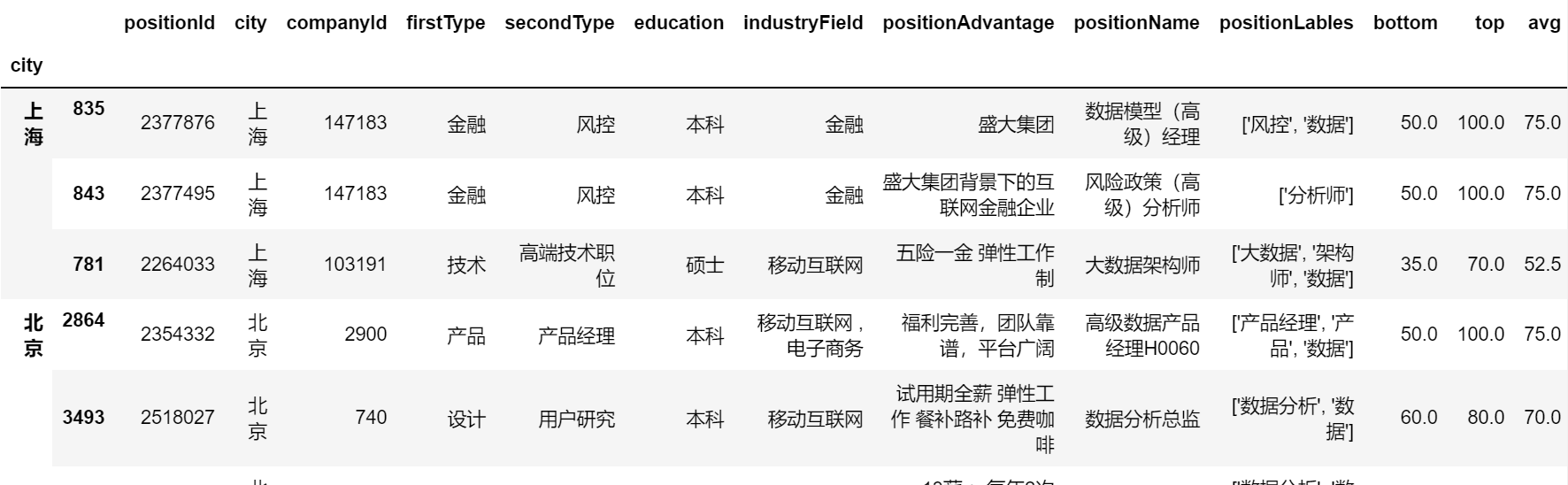
求出不同城市下薪资排名前n的岗位:
def func(x,n):
r = x.sort_values('avg', ascending=False)
return r[:n]
position.groupby('city').apply(func,n=3)
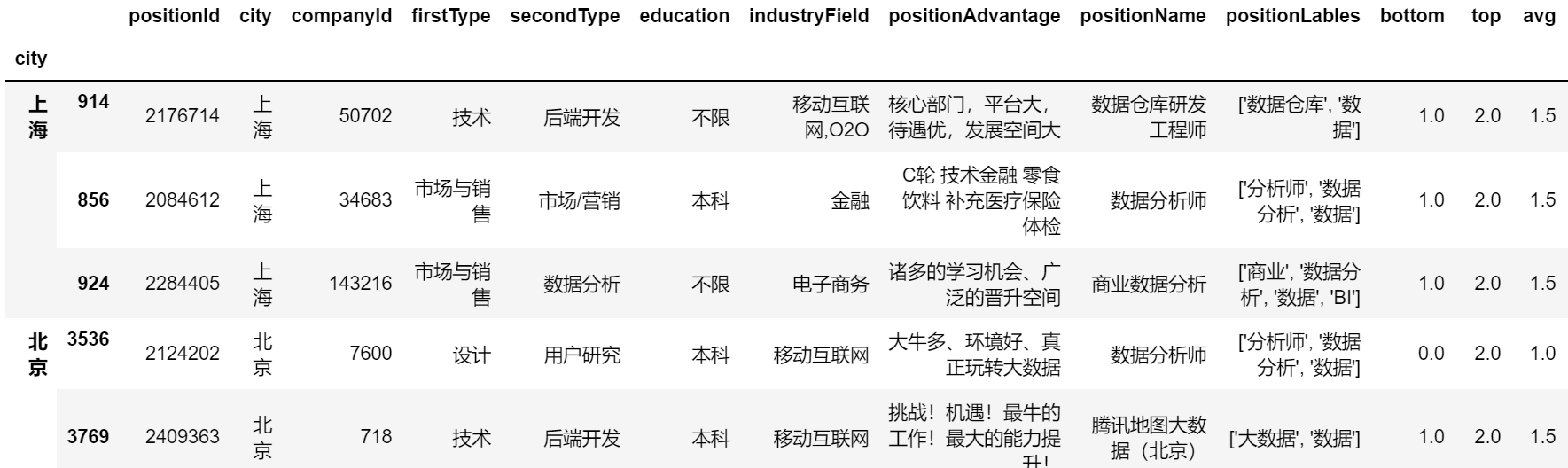
变为升序:
def func(x,n, asc=False):
r = x.sort_values('avg', ascending=asc)
return r[:n]
position.groupby('city').apply(func,n=3,asc=True)
5. agg()函数(不涉及形状变化)
position.groupby('city').agg(sum)
# 平均值是 .agg('mean'),等价于 .mean()
# 也可以同时运用多个函数 .agg(['sum','mean'])
# 也可以使用自定义函数 .agg(lambda x:max(x)-min(x))
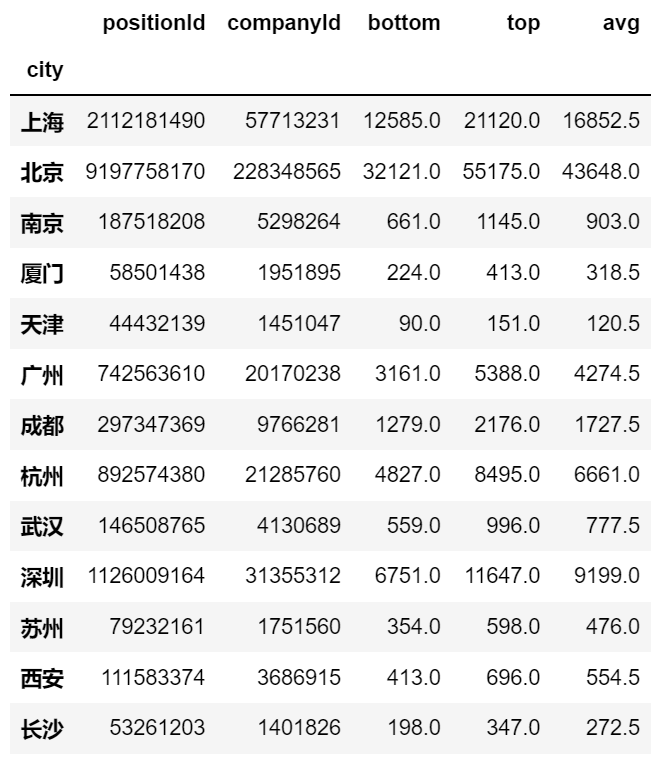
position.pivot_table(values= , index= , columns= , aggfunc= , fill value= , margins= , dropna= )
- aggfunc 默认为 'mean'
- margins 默认为 False,即在下面加一个汇总项
- dropna 默认为 True,即砍掉空值
position.pivot_table(index='city', columns='workYear', values='avg') # 支持多重索引,如:index=['city','education'],values=['top','avg']
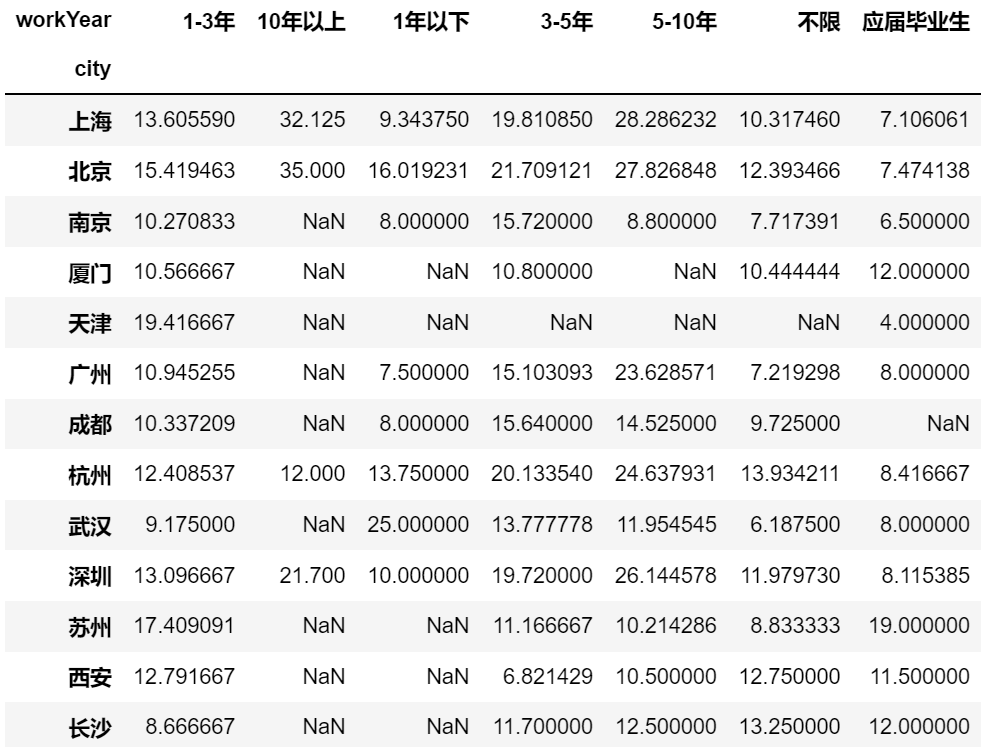
position.pivot_table(index = ['city','education'],
columns = 'workYear',
values = ['top','avg'],
aggfunc = [np.mean, np.sum])
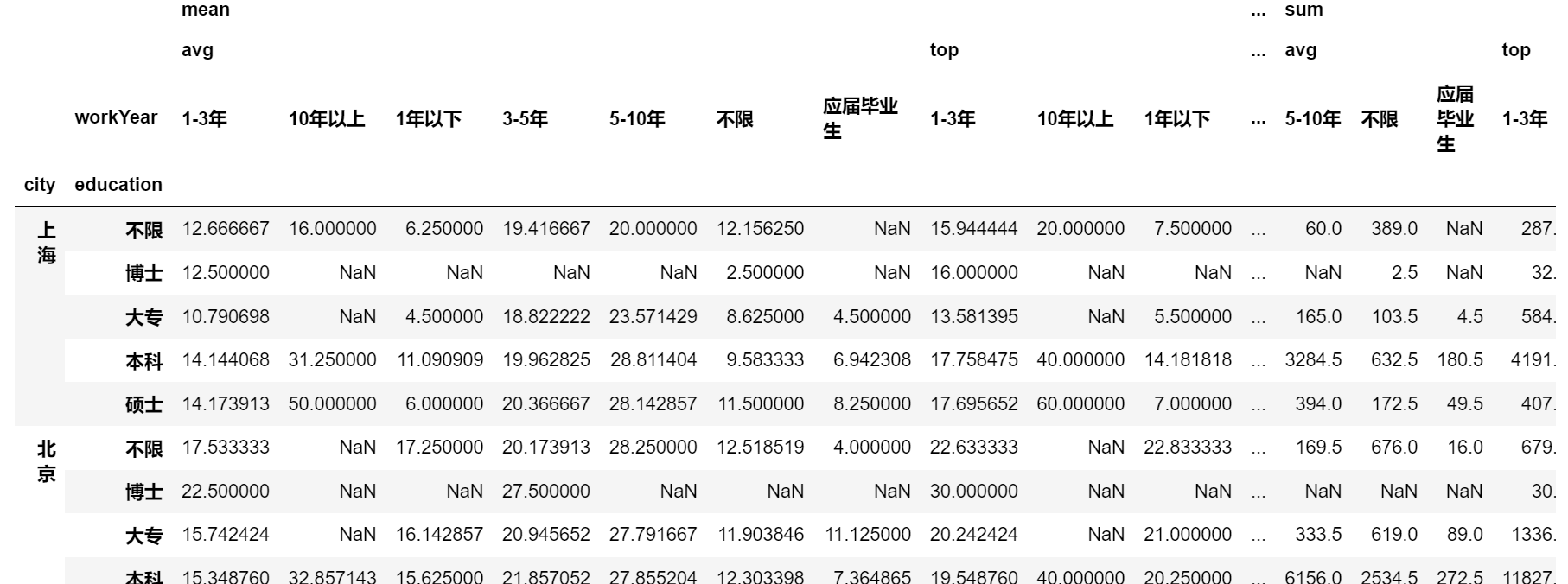
对上表可以进行不断地切片:
position.pivot_table(index = ['city','education'],
columns = 'workYear',
values = ['top','avg'],
aggfunc = [np.mean, np.sum])['mean']['avg'].loc['上海']
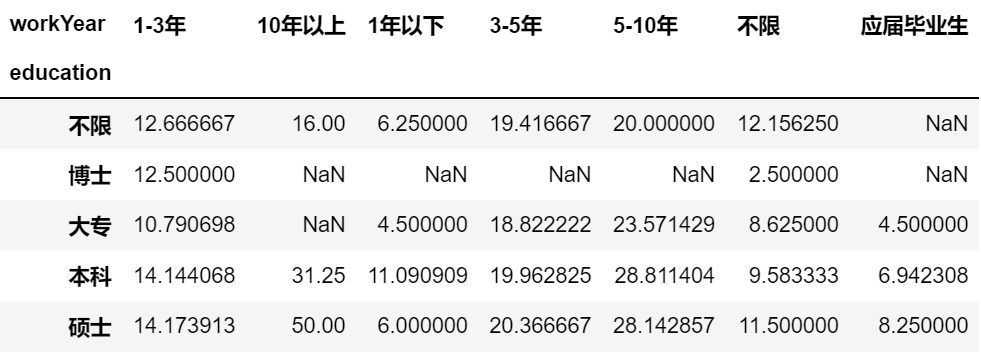
对 avg 求平均,对 top 求和:
position.pivot_table(index = ['city','education'],
columns = 'workYear',
values = ['top','avg'],
aggfunc = {'avg':np.mean,'top':np.sum}) # 字典的形式
输出为csv:
.reset_index().to_csv('test.csv')

