
本课程共七个章节,课程地址:7周成为数据分析师(完结)_哔哩哔哩_bilibili
- 数据分析思维
- 业务知识
- Excel
- 数据可视化
- SQL
- 统计学
- Python
- Python的数据科学环境(P86)
- Python基础(P87-P97)
- 数据分析常用包:Numpy和Pandas(P98-P112)
- Python连接数据库(P113-P114)
- 数据分析案例(P115-P124)
- 数据可视化:Matplotlib和Seaborn(P125-P138)
- 数据分析平台(P139-P143)
目录
第七周:Python(P86-P143)
六、数据可视化:Matplotlib和Seaborn
(一)Pandas自带的可视化
- 折线图 plot
- 柱形图/条形图 bar
- 直方图 hist
- 箱线图 box
- 密度图 kde
- 面积图 area
- 散点图 scatter
- 散点图矩阵 scatter_matrix
- 饼图 pie
(二)Matplotlib
- 饼图 plt.pie()
- 折线图 plt.plot()
- 图表元素
- 同时画多条折线图
- 添加图例
- 绘制子图subplot
(三)Seaborn(高级图像)
分布
- distplot 概率分布图
- kdeplot 概率密度图
- jointplot 联合密度图(两个变量)
- pairplot 多变量图(多个变量)
分类
- boxplot 箱线图
- violinplot 提琴图
- barplot 柱形图
- factorplot 因子图
线性
- lmplot 回归图
- heatmap 热力图
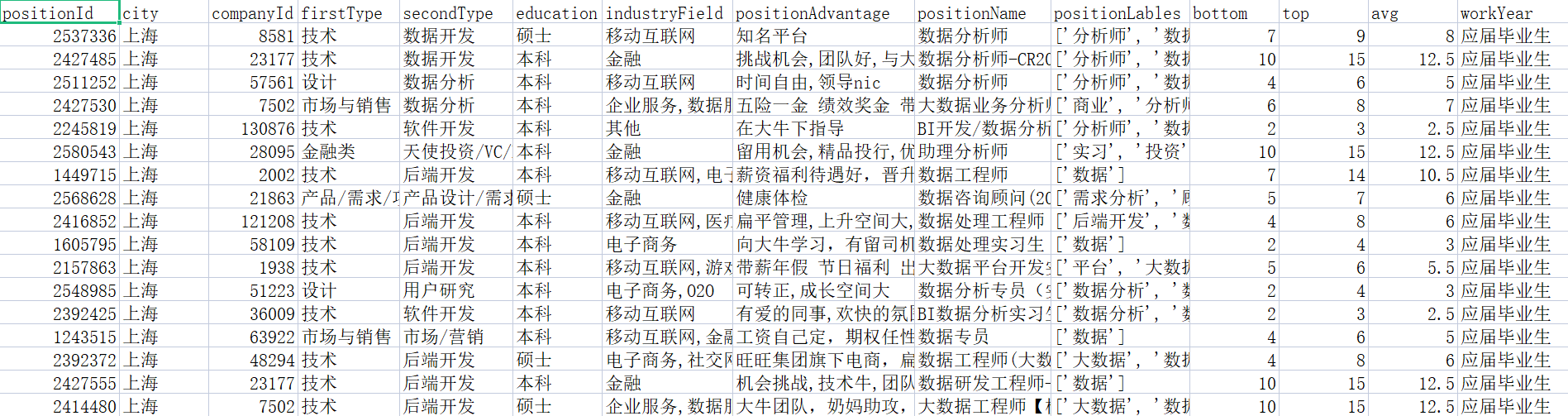
import pandas as pd
df = pd.read_csv('position_gbk.csv', encoding='gbk')
%matplotlib inline
- 折线图 plot
- 柱形图/条形图 bar
- 直方图 hist
- 箱线图 box
- 密度图 kde
- 面积图 area
- 散点图 scatter
- 散点图矩阵 scatter_matrix
- 饼图 pie
1. 折线图 plot
df.avg.plot()
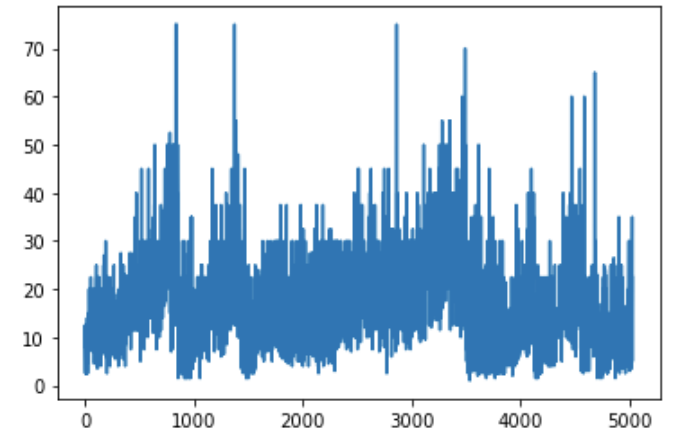
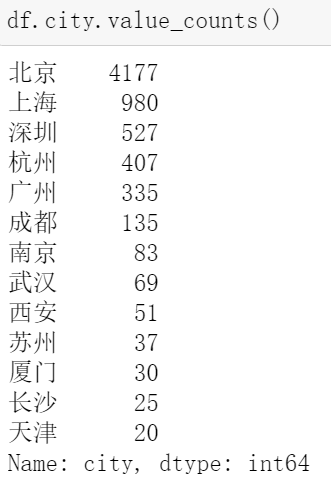
# 统计不同薪资的出现次数 df.avg.value_counts().sort_index().plot()
为什么要加 .sort_index()? —— 使索引(即第一列)从低到高排序
2. 柱形图/条形图 bar
# 法1 df.avg.value_counts().sort_index().plot(kind='bar') # 法2 df.avg.value_counts().sort_index().plot.bar()
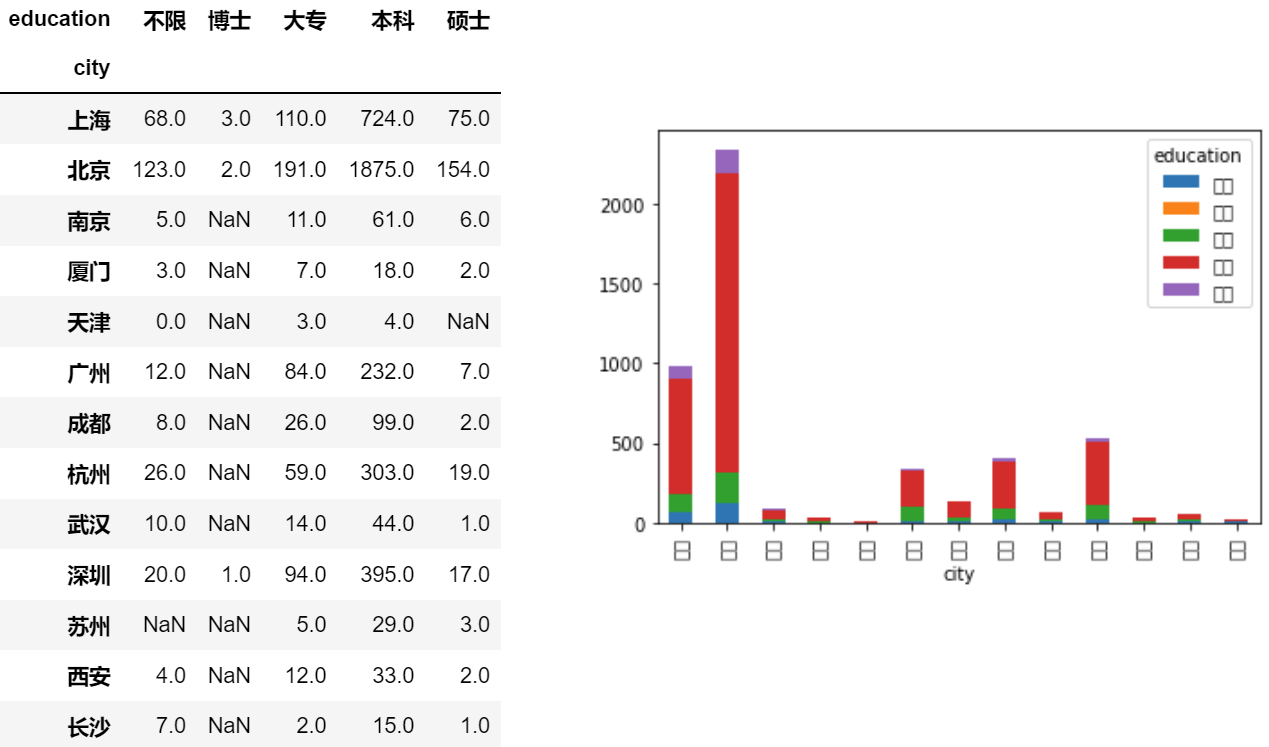
- 堆积柱形图
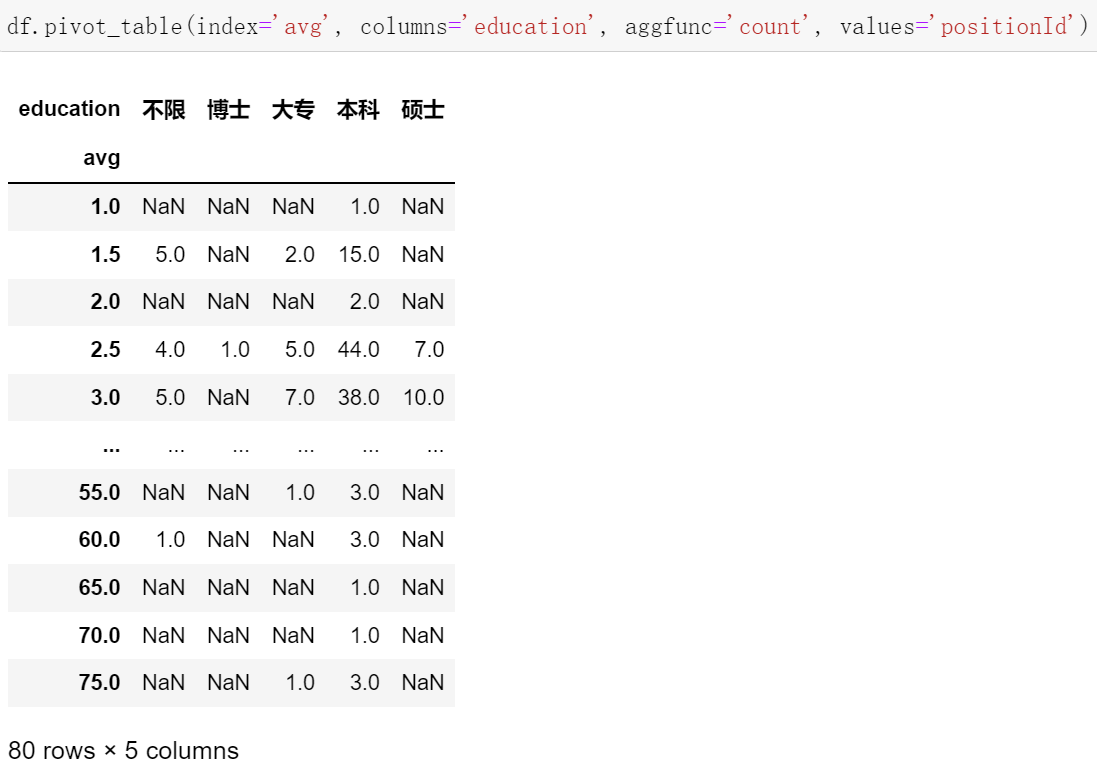
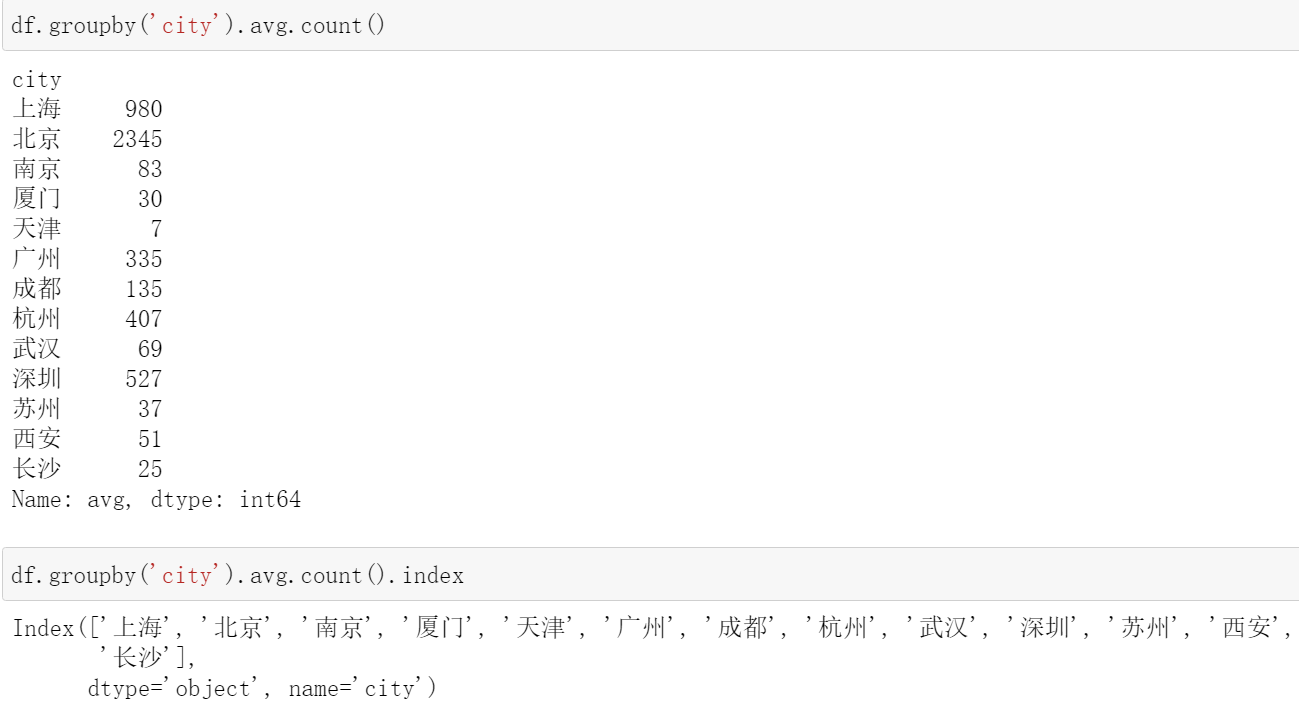
df.pivot_table(index='city', columns='education', values='avg', aggfunc='count').plot.bar(stacked=True)
- 百分比堆积柱形图
需要数据处理时用apply函数变化一下,没有直接的参数可以使用
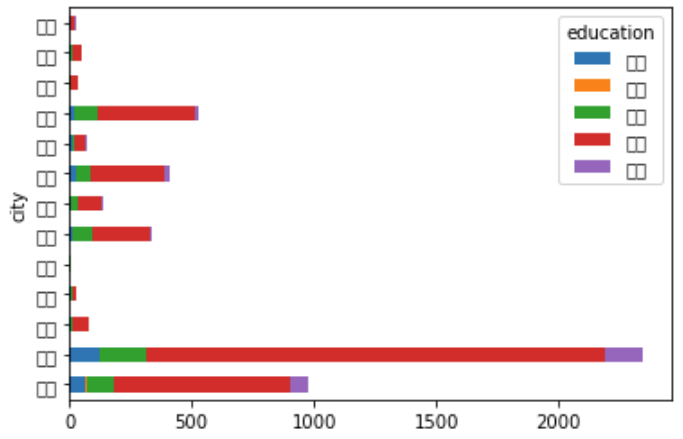
- 变为横向(条形图)
df.pivot_table(index='city', columns='education', values='avg', aggfunc='count').plot.barh(stacked=True) # h为水平轴的意思
3. 直方图 hist
# 带网格 df.avg.hist() # 不带网格 df.avg.plot.hist() # 参数 bins:切多少个箱体
- 多重直方图:在一张图里展示多个直方图,要使用多列(education 和 avg)
df.groupby('education').apply(lambda x:x.avg).unstack().T.plot.hist(alpha = 0.8) # 透明度
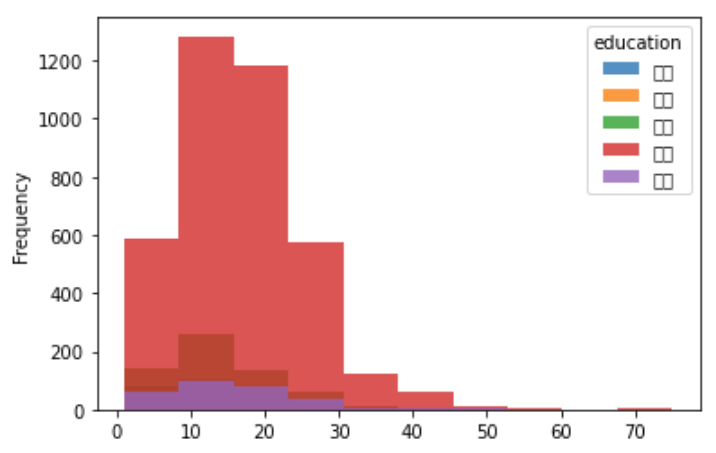
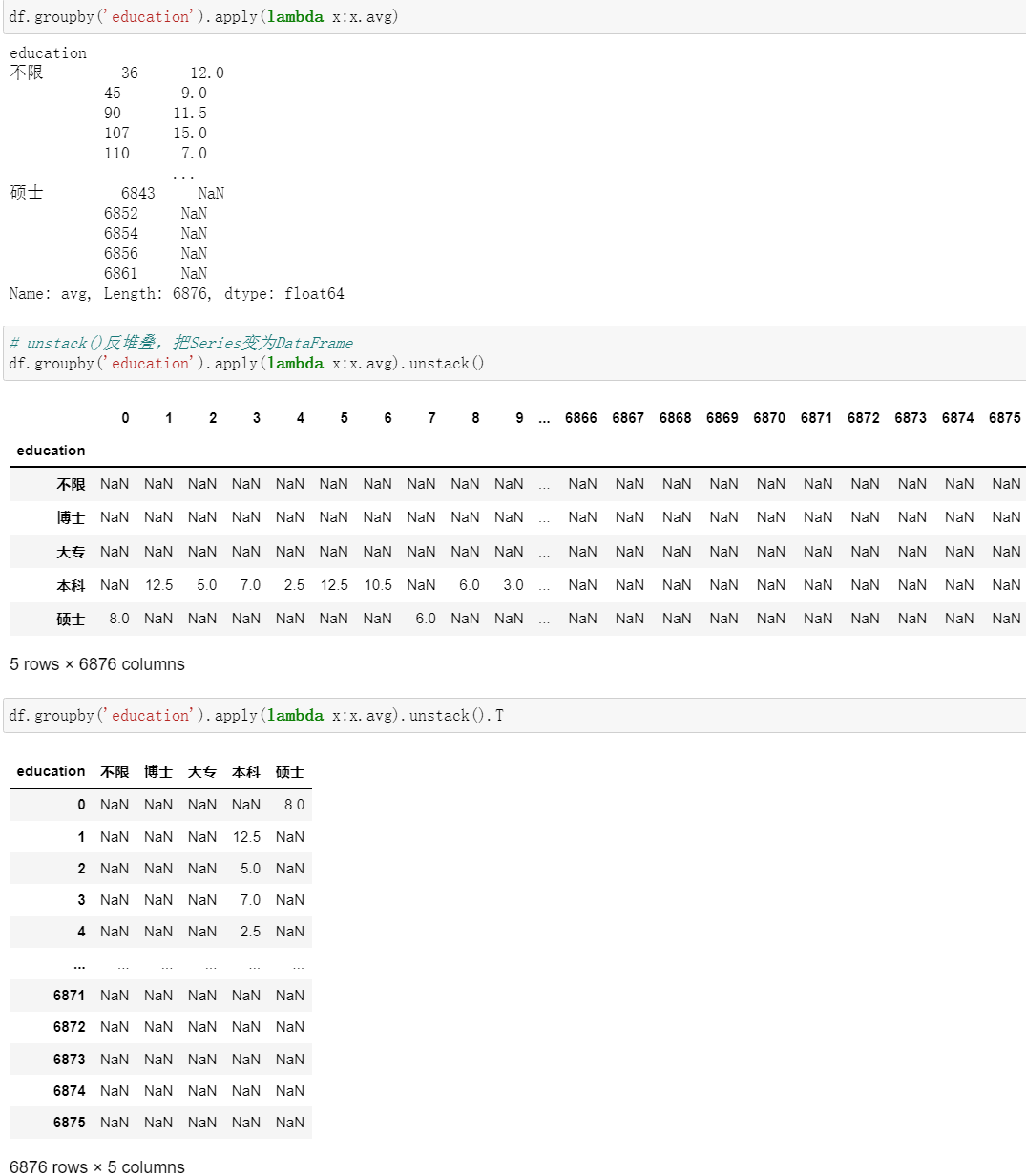
- 堆叠多重直方图:
df.groupby('education').apply(lambda x:x.avg).unstack().T.plot.hist(alpha = 0.5, stacked=True, bins=30)
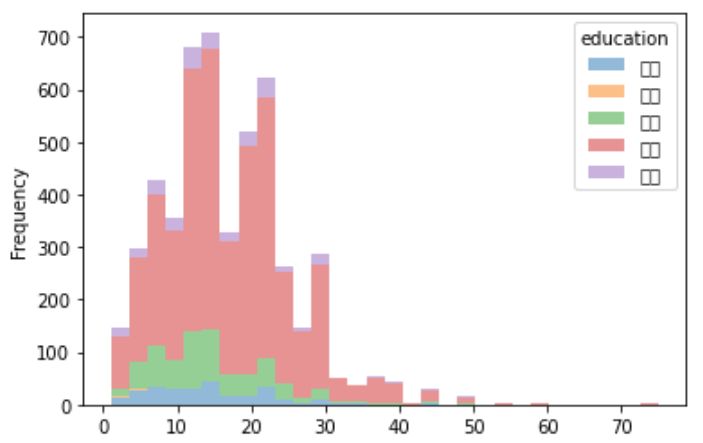
- 变为水平条形图:
df.groupby('education').apply(lambda x:x.avg).unstack().T.plot.hist(alpha = 0.5, stacked=True, bins=30, orientation = 'horizontal')
4. 箱线图 box
# 箱体:列
df.groupby('education').apply(lambda x:x.avg).unstack().T.plot.box()
# 法2
df.boxplot(column = 'avg', by = 'education')
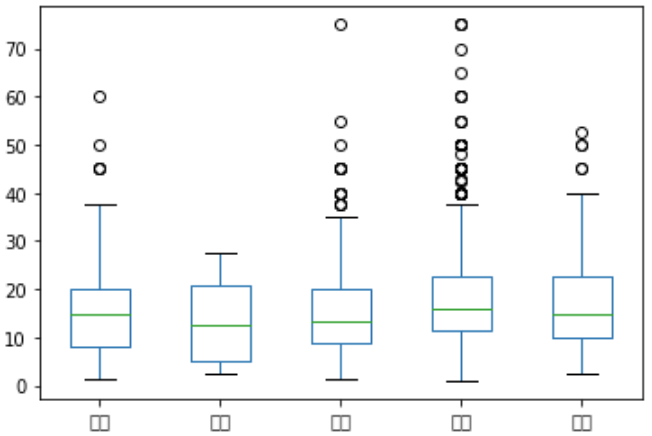
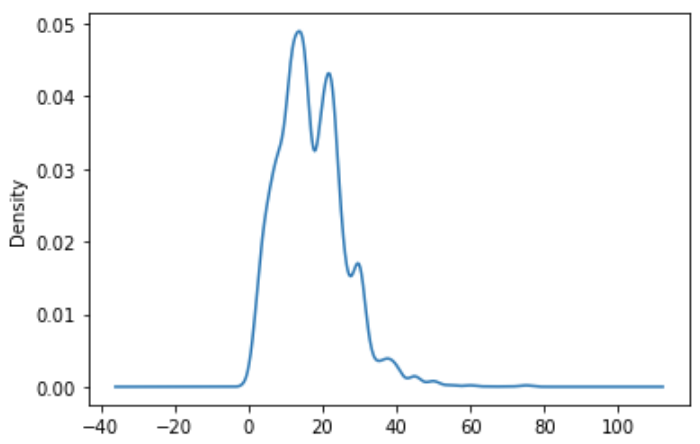
5. 密度图 kde
df.avg.plot.kde() # 薪资落在某个区间范围的概率(面积)
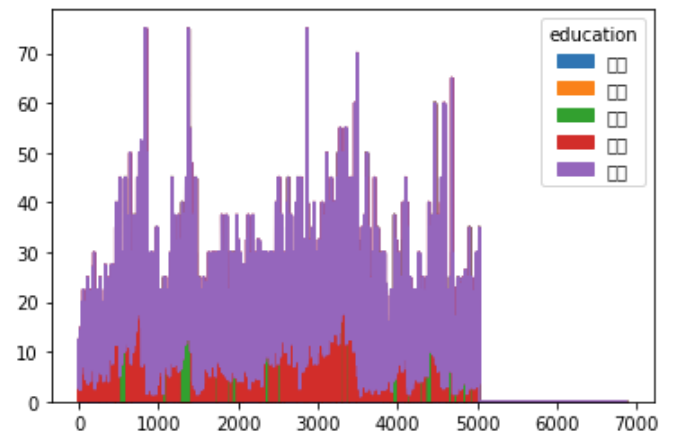
5. 面积图 area
df.groupby('education').apply(lambda x:x.avg).unstack().T.plot.area()
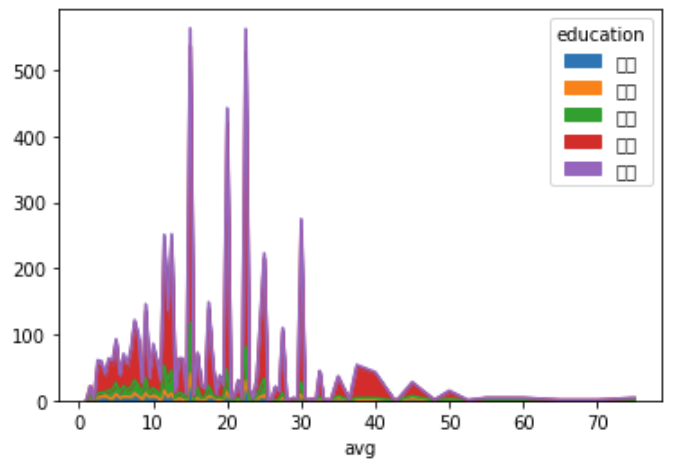
df.pivot_table(index='avg', columns='education', aggfunc='count', values='positionId').plot.area()
- 百分比面积图
# 加一个apply()函数计算百分比 df.pivot_table(index='avg', columns='education', aggfunc='count', values='positionId').apply().plot.area()
6. 散点图 scatter
df.groupby('companyId').aggregate(['mean','count','max']).avg.plot.scatter(x='mean',y='count')
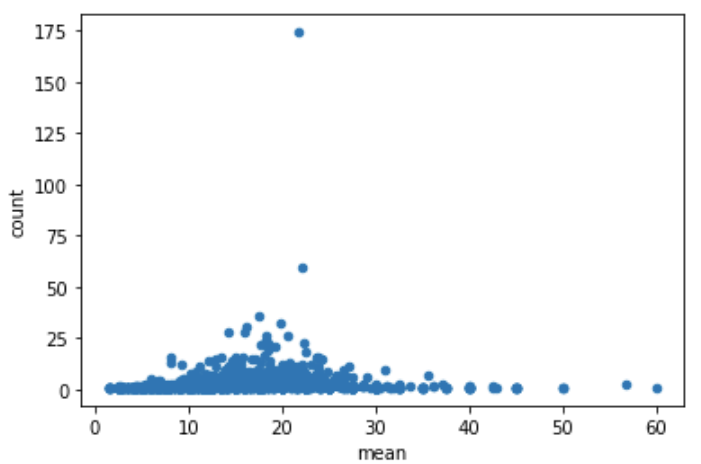
7. 散点图矩阵 scatter_matrix
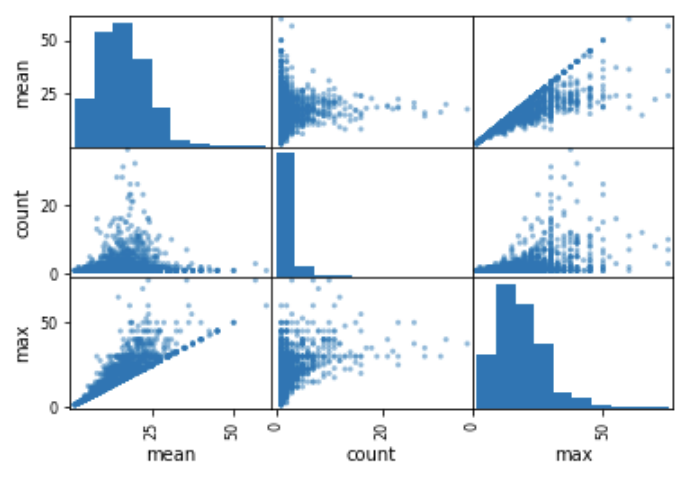
pd.plotting.scatter_matrix(matrix)
- 可以通过query条件过滤数据
pd.plotting.scatter_matrix(matrix.query('count<50'))
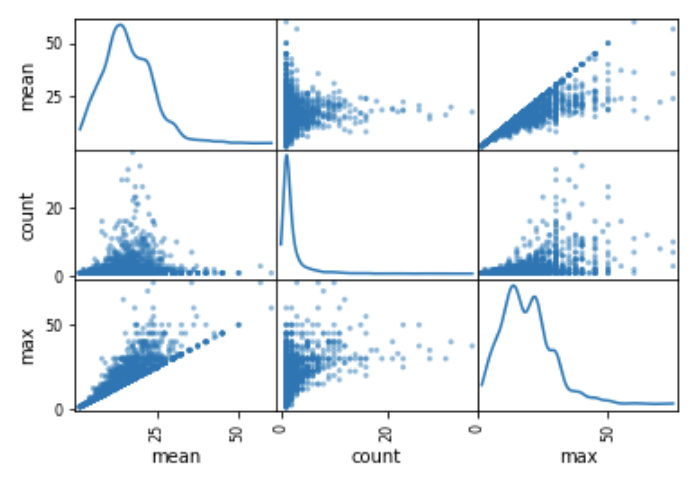
- 对角线上的直方图改为密度图
pd.plotting.scatter_matrix(matrix.query('count<50'),diagonal='kde')
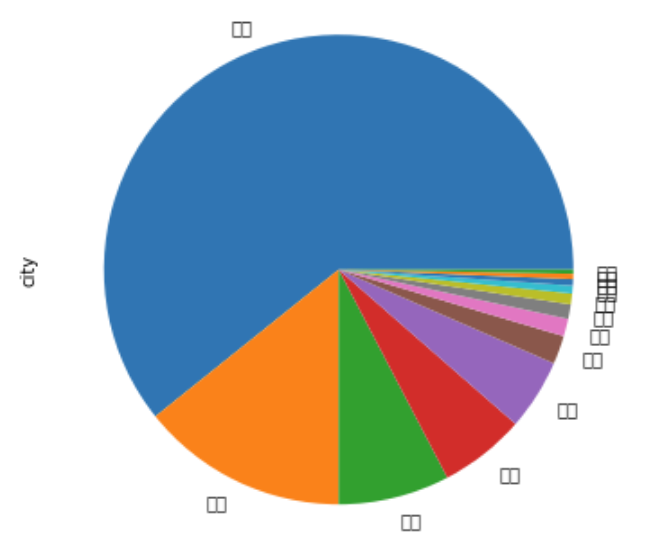
8. 饼图 pie
df.city.value_counts().plot.pie(figsize=(6,6))
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 让图表在单元格里显示
%matplotlib inline
df = pd.read_csv('position_gbk.csv', encoding='gbk')
# 显示中文(字符串编码问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 字体设置为黑体
plt.rcParams['axes.unicode_minus'] = False # 使坐标轴上能显示负数的负号
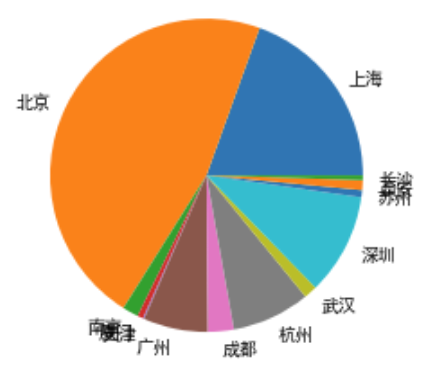
1. 饼图
plt.pie(df.groupby('city').avg.count(), labels = df.groupby('city').avg.count().index)
2. 折线图
# np.random.random_integers(-20,20,20) # 创建-20到20之间的20个数 plt.plot(np.random.random_integers(-20,20,20)) # 去掉内存地址[],加上下面这行 plt.show()
3. 图表元素
画布figure上可以有很多子图subplot(类似于BI的dashboard),单独一张图表叫axes
- title:标题
- data:数据
-
x轴
- x轴刻度:xticks
- x轴标签:xlabel
- y轴
plt.figure(1, figsize=(10,4))
plt.plot(np.random.random_integers(-20,20,20))
plt.title('这是一条折线图')
plt.xticks([0,10,20])
plt.xlabel('x轴')
plt.show()
4. 同时画多条折线图
图表是一层一层粘贴上去的,故一行代码就是一个图表
plt.plot(np.random.random_integers(-20,20,20)) plt.plot(np.random.random_integers(-20,20,20)) plt.show()
5. 添加图例
# 法1
plt.plot(np.random.random_integers(-20,20,20))
plt.plot(np.random.random_integers(-20,20,20))
plt.legend(('no1','no2'))
plt.show()
# 法2
plt.plot(np.random.random_integers(-20,20,20),label='no1',color='r')
plt.plot(np.random.random_integers(-20,20,20),label='no2')
plt.legend()
plt.show()
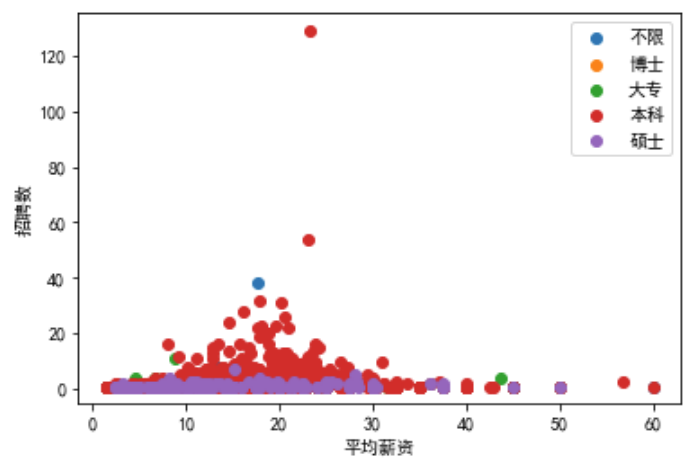
例:计算不同公司下的平均工资和招聘岗位数,散点图,分类属性为学历
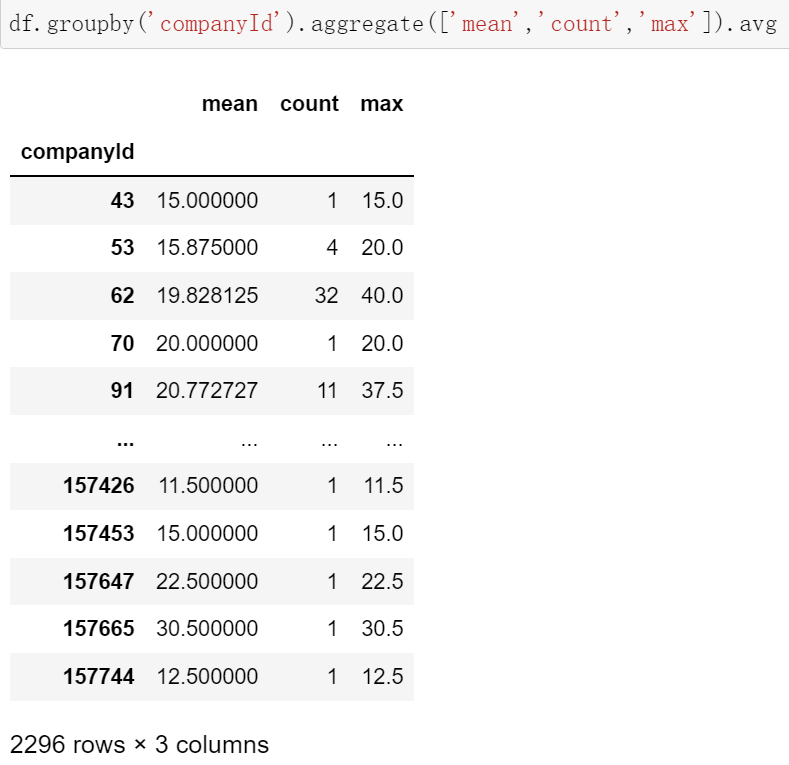
df.groupby(['education','companyId']).aggregate(['mean','count']).avg data = df.groupby(['education','companyId']).aggregate(['mean','count']).avg.reset_index() data
for edu, grouped in data.groupby('education'): # edu为标签,grouped为标签下的数据框
x = grouped['mean'] # 切片
y = grouped['count']
plt.scatter(x,y,label=edu)
plt.legend() # 加上参数loc='upper left'可以将图例添加到左侧
plt.xlabel('平均薪资')
plt.ylabel('招聘数')
plt.show()
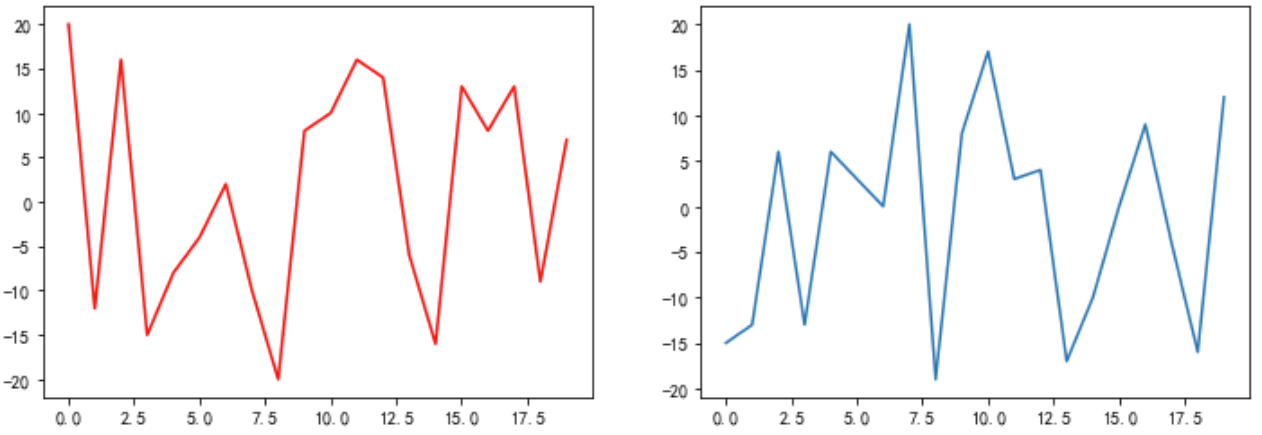
6. 绘制子图subplot
在一张画布上画多个图表
# 定义画布宽度 plt.figure(figsize=(12,4)) # 第一张图绘制 plt.subplot(1,2,1) # 也可以写成plt.subplot(121) plt.plot(np.random.random_integers(-20,20,20),label='no1',color='r') # 第二张图绘制 plt.subplot(1,2,2) plt.plot(np.random.random_integers(-20,20,20),label='no2') plt.show()
# 定义画布宽度 plt.figure(figsize=(12,4)) # 第一张图绘制 plt.subplot(221) # 四份,占据第一个 plt.plot(np.random.random_integers(-20,20,20),label='no1') plt.plot(np.random.random_integers(-20,20,20),label='no2') plt.legend() # 第二张图绘制 plt.subplot(222) # 四份,占据第二个 plt.plot(np.random.random_integers(-20,20,20),label='no3') plt.plot(np.random.random_integers(-20,20,20),label='no4') plt.legend() # 第三张宽图绘制 plt.subplot(212) # 两行一列,占据第二个位置 plt.plot(np.random.random_integers(-20,20,20),label='no5') plt.show()
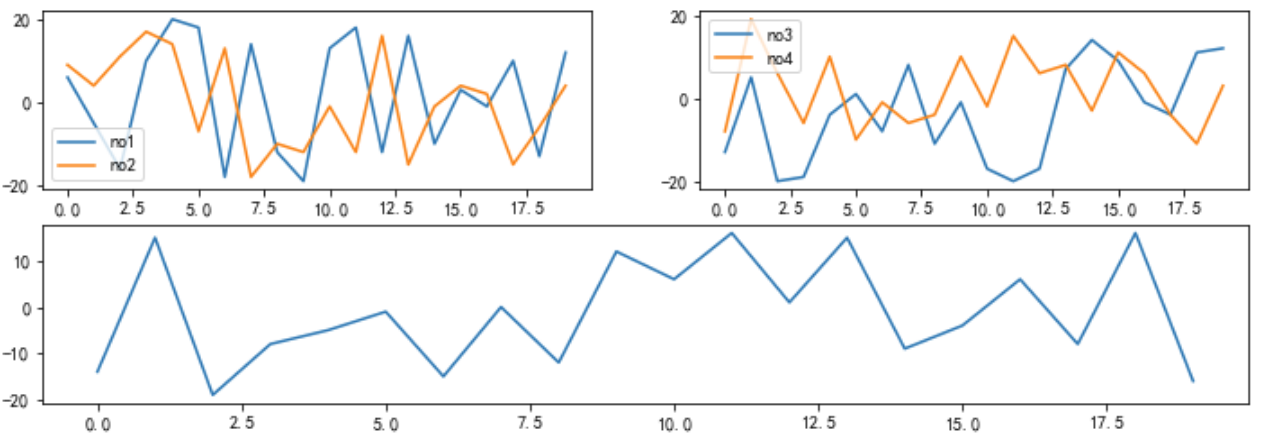
# 定义画布宽度 plt.figure(figsize=(12,4)) # 第一张图绘制 plt.subplot(221) # 四份,占据第一个 plt.plot(np.random.random_integers(-20,20,20),label='no1') plt.plot(np.random.random_integers(-20,20,20),label='no2') plt.legend() # 第二张图绘制 plt.subplot(223) # 四份,占据第三个 plt.plot(np.random.random_integers(-20,20,20),label='no3') plt.plot(np.random.random_integers(-20,20,20),label='no4') plt.legend() # 第三张宽图绘制 plt.subplot(122) # 一行两列,占据第二个位置 plt.plot(np.random.random_integers(-20,20,20),label='no5') plt.show()
plt.figure(figsize=(12,6))
plt.subplot(121)
plt.plot(np.random.random_integers(-20,20,20),label='no1')
data = df.groupby(['city','companyId']).aggregate(['mean','count']).avg.reset_index()
for city, grouped in data.groupby('city'): # city为标签,grouped为标签下的数据框
x = grouped['mean'] # 切片
y = grouped['count']
plt.subplot(122)
plt.scatter(x,y,label=city)
plt.legend(loc='upper right')
plt.xlabel('平均薪资')
plt.ylabel('招聘数')
plt.show()

import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline
分布
- distplot 概率分布图
- kdeplot 概率密度图
- jointplot 联合密度图(两个变量)
- pairplot 多变量图(多个变量)
分类
- boxplot 箱线图
- violinplot 提琴图
- barplot 柱形图
- factorplot 因子图
线性
- lmplot 回归图
- heatmap 热力图
1. 分布
- distplot 概率分布图
- kdeplot 概率密度图
- jointplot 联合密度图(两个变量)
- pairplot 多变量图(多个变量)
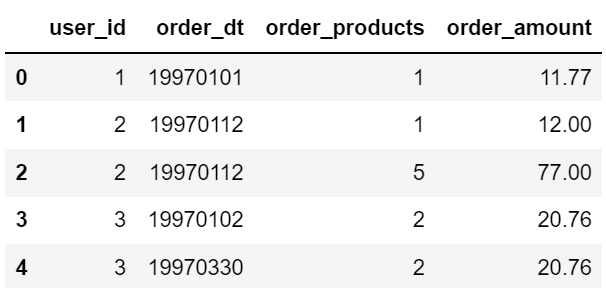
columns = ['user_id','order_dt','order_products','order_amount']
df = pd.read_table('CDNOW_master.txt', names=columns, sep='\s+')
df.head()
(1)单变量分析
- displot 概率分布图
# 概率分布图 sns.distplot(df.order_amount) # 只需要直方图 sns.distplot(df.order_amount, kde=False)
 (左)概率分布图,(右)只需要直方图
(左)概率分布图,(右)只需要直方图
- kdeplot 概率密度图
# 概率密度图,不带直方 sns.kdeplot(df.order_amount)
- jointplot 联合密度图
# 求每个用户的总消费次数和总消费金额
grouped_user = df.groupby('user_id').sum()
grouped_user.head()
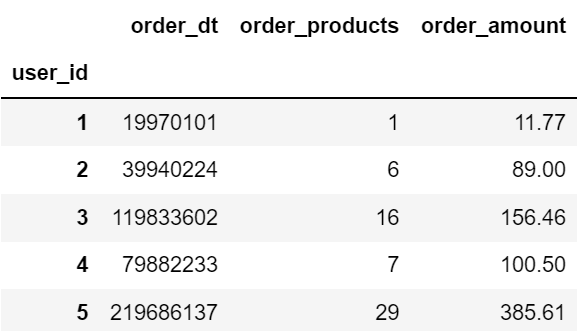
# 联合密度图 sns.jointplot(x = grouped_user.order_products, y = grouped_user.order_amount) sns.jointplot(x = grouped_user.order_products, y = grouped_user.order_amount, kind='reg') # kind默认为scatter
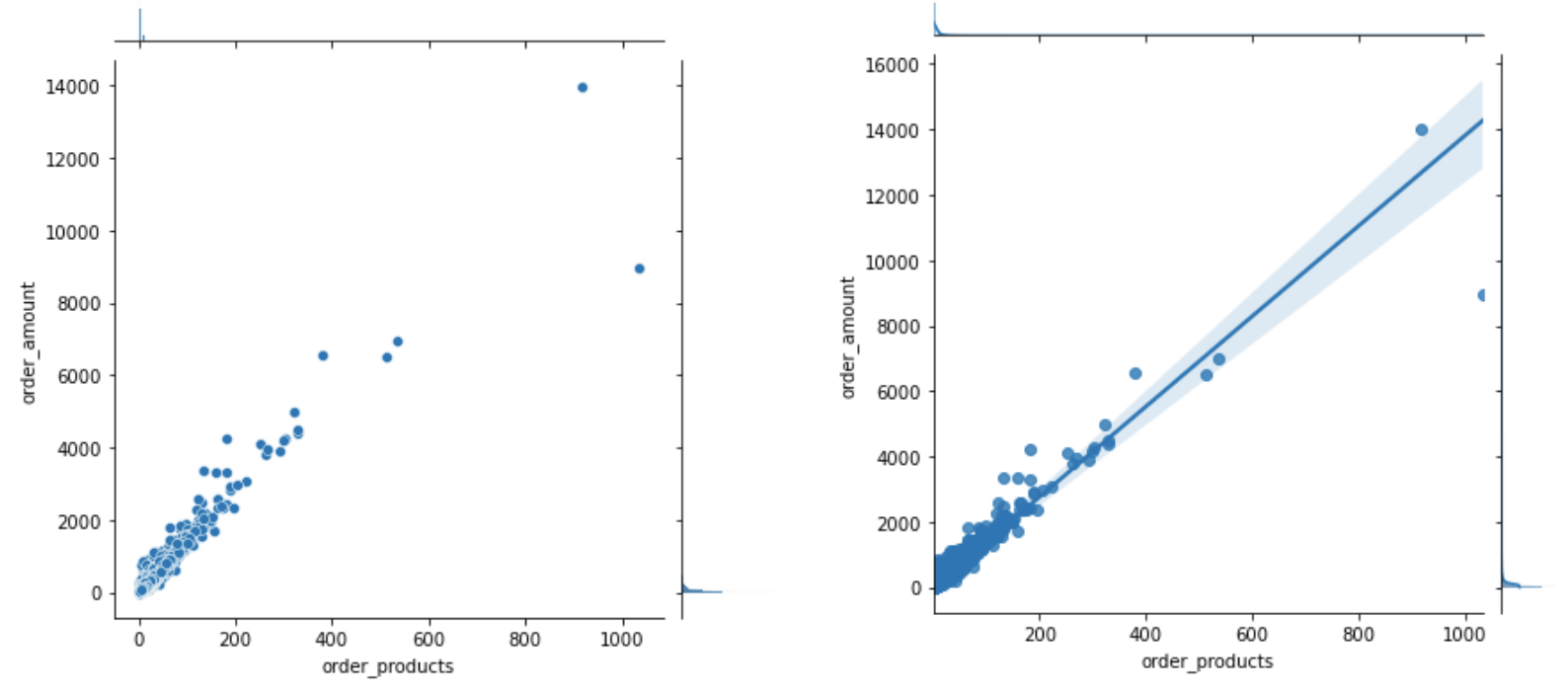 (左)kind默认为scatter,(右)kind为reg
(左)kind默认为scatter,(右)kind为reg
(2)多变量/多因子分析
- 联合密度图(2个变量)
# RFM
df['order_dt'] = pd.to_datetime(df.order_dt, format = '%Y%m%d')
rfm = df.pivot_table(index = 'user_id',
values = ['order_products','order_amount','order_dt'],
aggfunc = {'order_dt':'max',
'order_amount':'sum',
'order_products':'sum'
})
rfm['R'] = -(rfm.order_dt - rfm.order_dt.max()) / np.timedelta64(1,'D')
rfm.rename(columns = {'order_products':'F', 'order_amount':'M'}, inplace=True)
rfm.head()
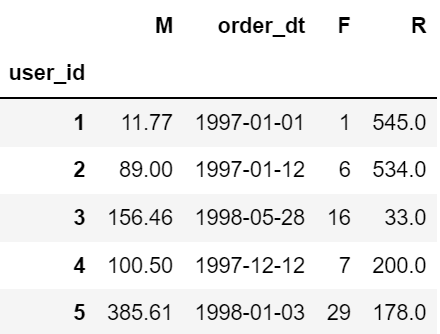
# 联合密度图 sns.jointplot(x = rfm.R, y = rfm.F) # 左图 # 消费频次F 和 总消费额M sns.jointplot(x = rfm.F, y = rfm.M, kind='reg') # 客单价;右图
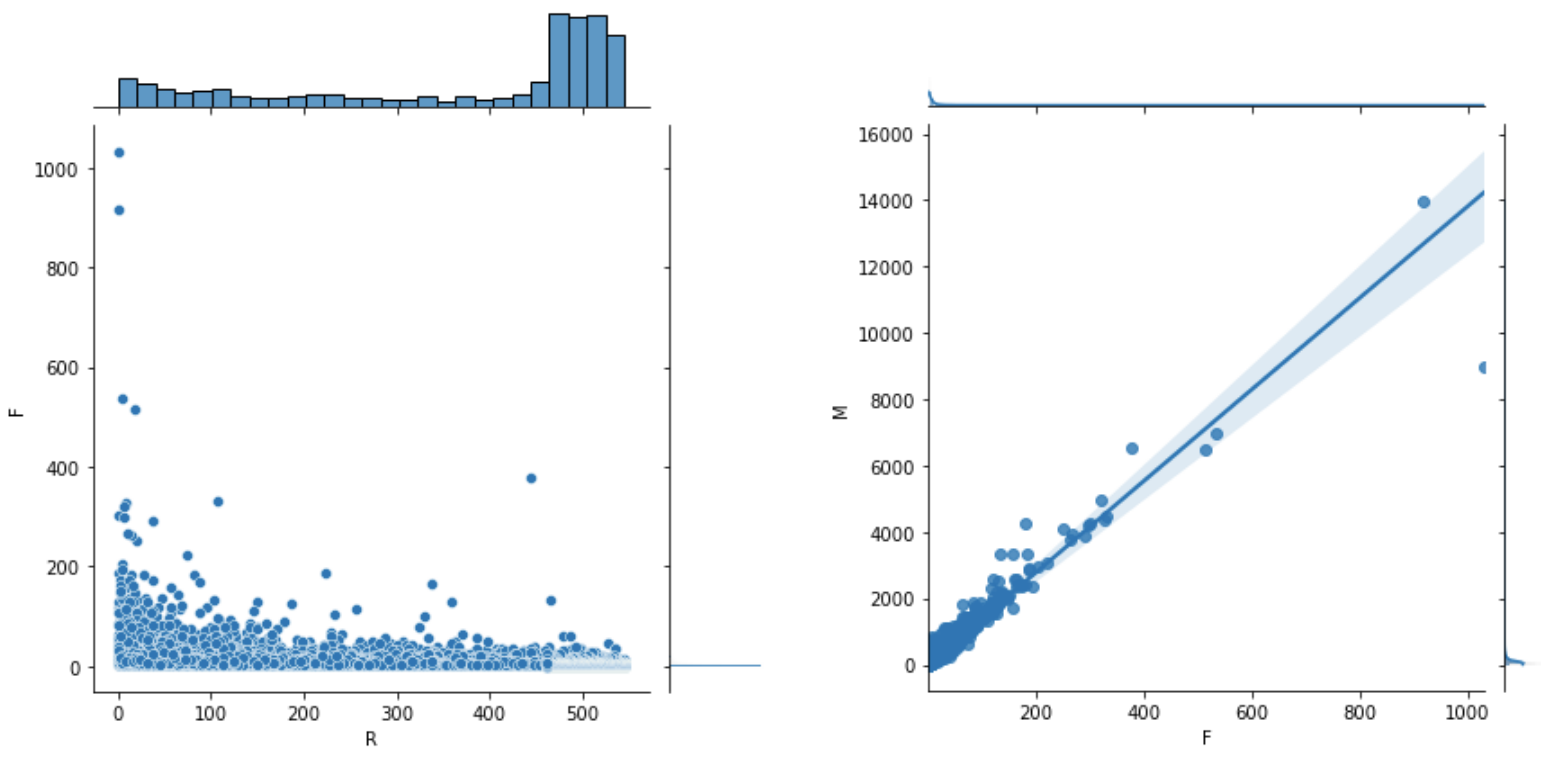
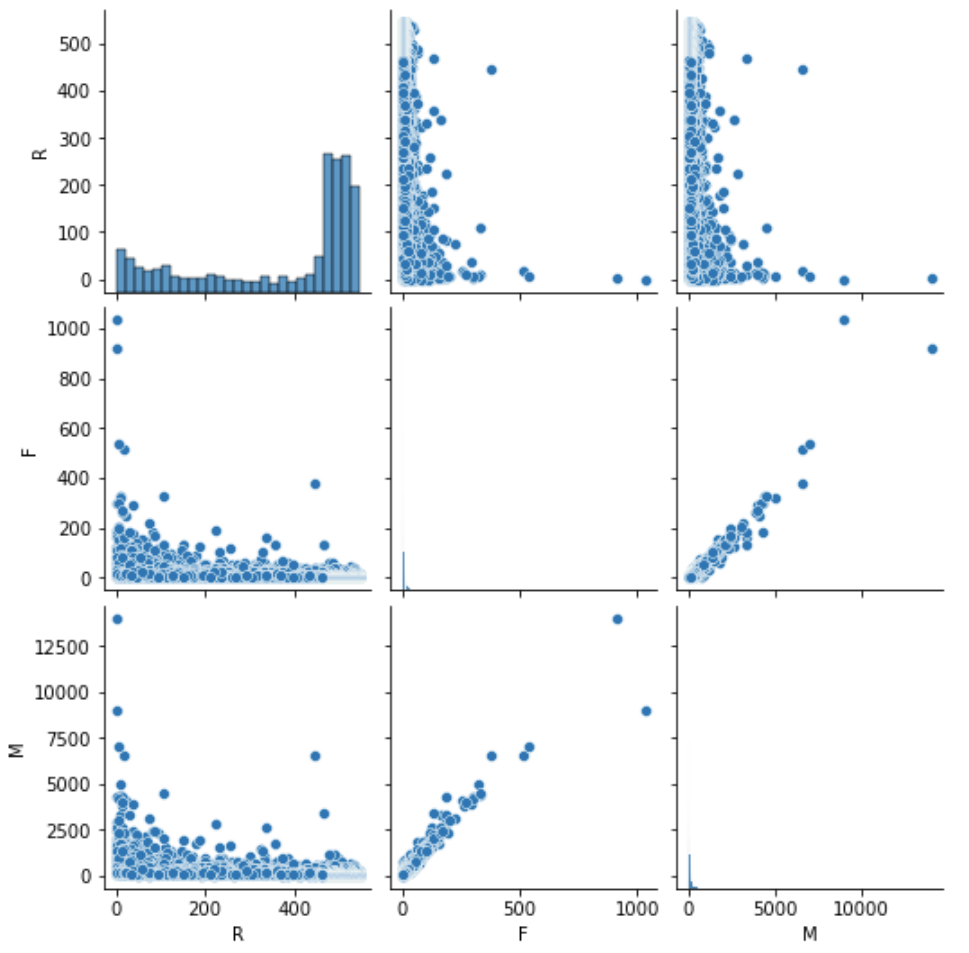
- 多变量图(多个变量)
sns.pairplot(rfm[['R','F','M']]) # 散点图矩阵 # 参数hue:针对某一字段进行分类,如:若rfm用户还有一个性别的分类 # 参数palette = 'husl':设置调色板
2. 分类
plt.rcParams['font.sans-serif'] = 'SimHei'
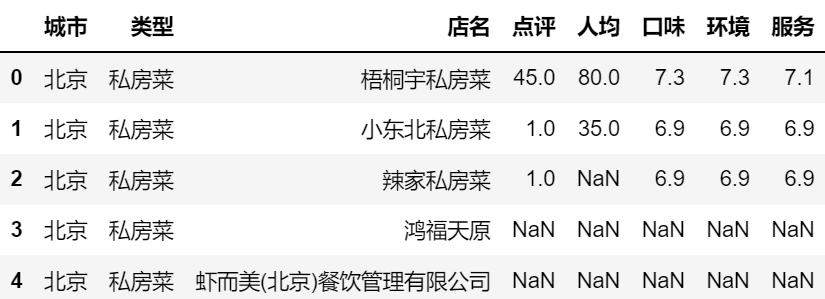
df = pd.read_csv('cy.csv',encoding='gbk')
df.head()
df2 = df.query("(城市=='上海')|(城市=='北京')")
- boxplot 箱线图
- violinplot 提琴图
- barplot 柱形图
- factorplot 因子图
(1)箱线图
sns.boxplot(x= , y= , hue=, data= )
四个参数:
- x:类型
- y:数值,构成箱体和箱线
- hue:x轴本身已经进行分类好之后,再去进行一个对比
- data:数据来源
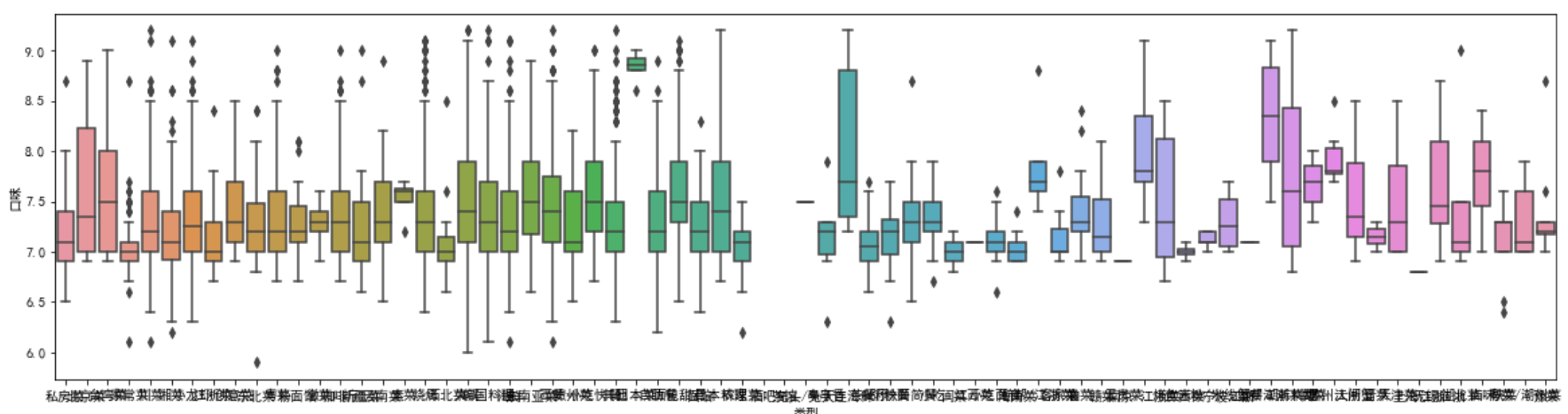
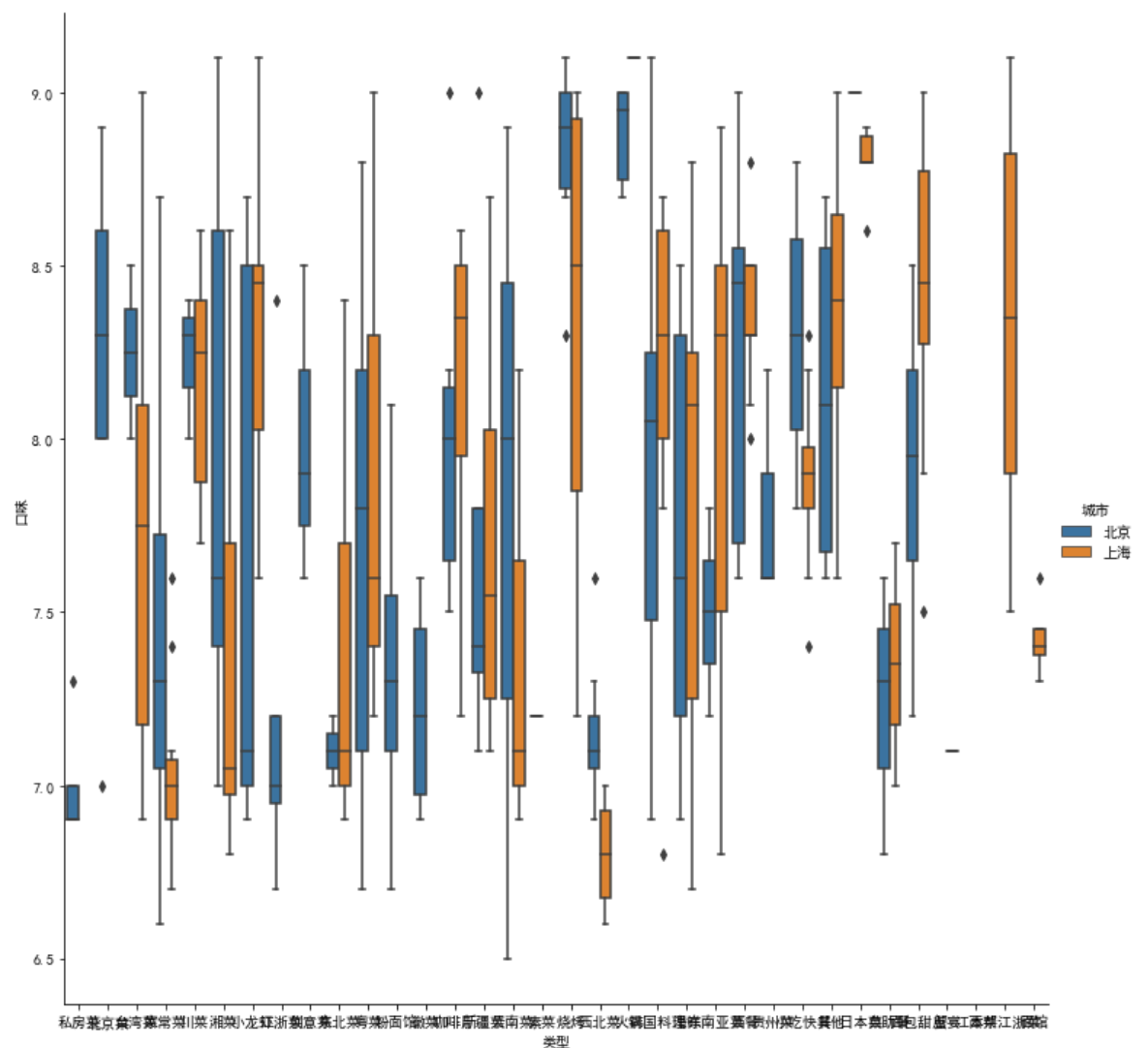
plt.figure(figsize=(20,5)) sns.boxplot(x = '类型', y = '口味', data = df)
plt.figure(figsize=(20,5)) sns.boxplot(x = '类型', y = '口味', hue='城市', data = df2)
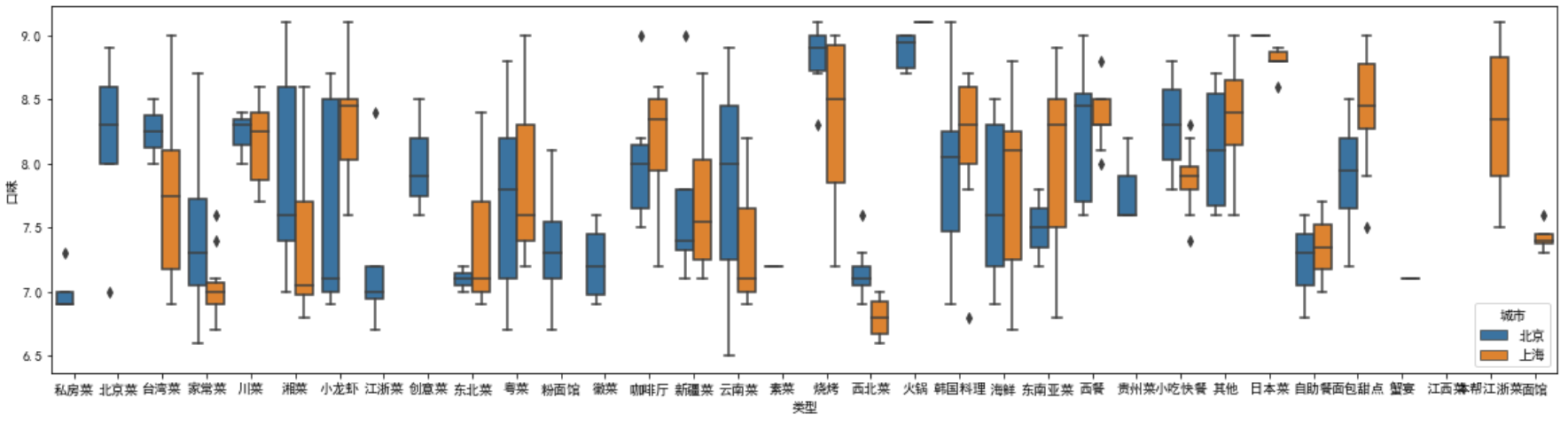
(2)提琴图
- 表示集中,左右代表密度
- 箱线图(根据分位数画出)+ 密度图/直方图 = 提琴图
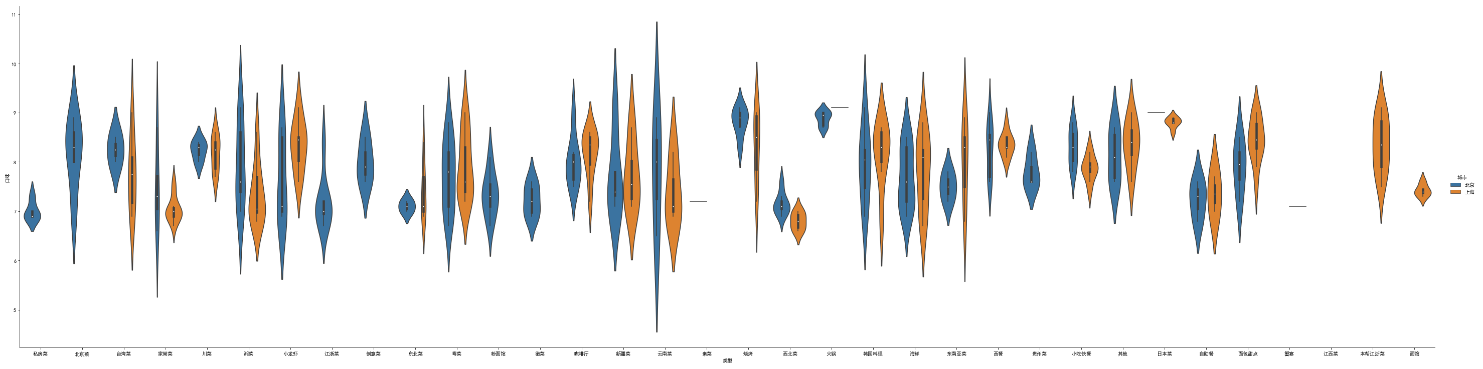
plt.figure(figsize=(20,5)) sns.violinplot(x = '类型', y = '口味', data = df)

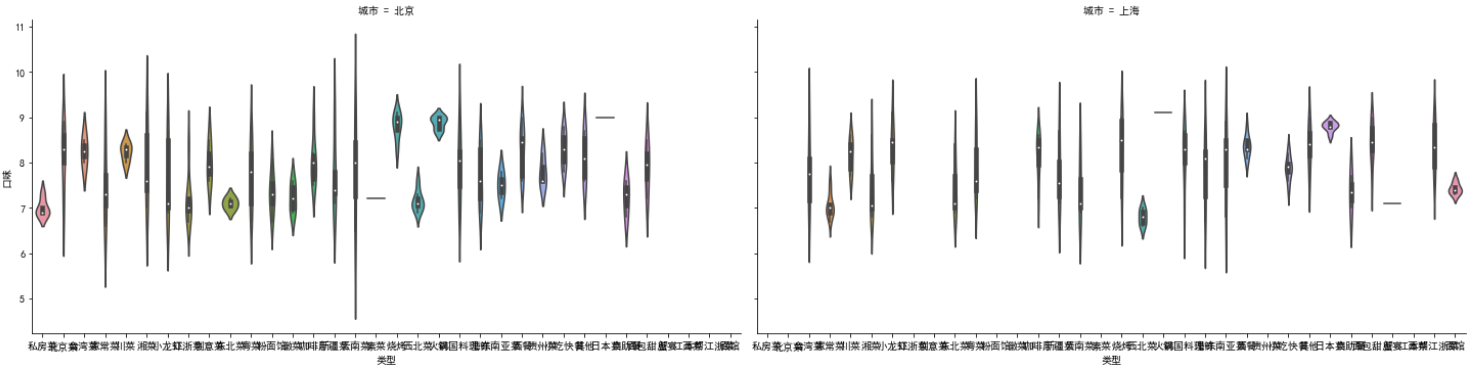
plt.figure(figsize=(20,5)) sns.violinplot(x = '类型', y = '口味', hue='城市', data = df2)
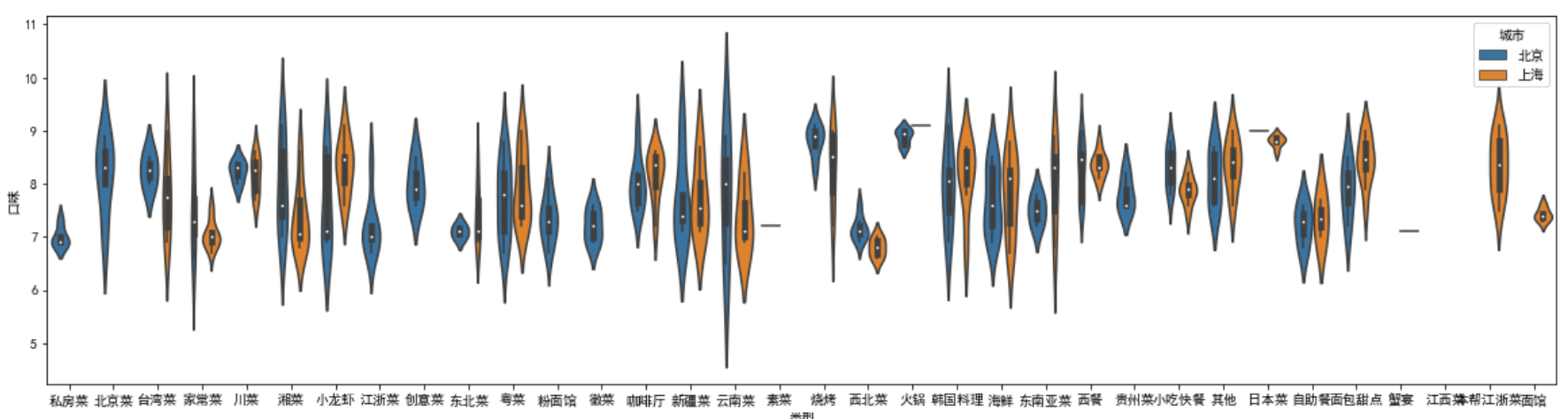
plt.figure(figsize=(20,5)) sns.violinplot(x = '类型', y = '口味', hue='城市', data = df2, split = True) # split = True表示拼接
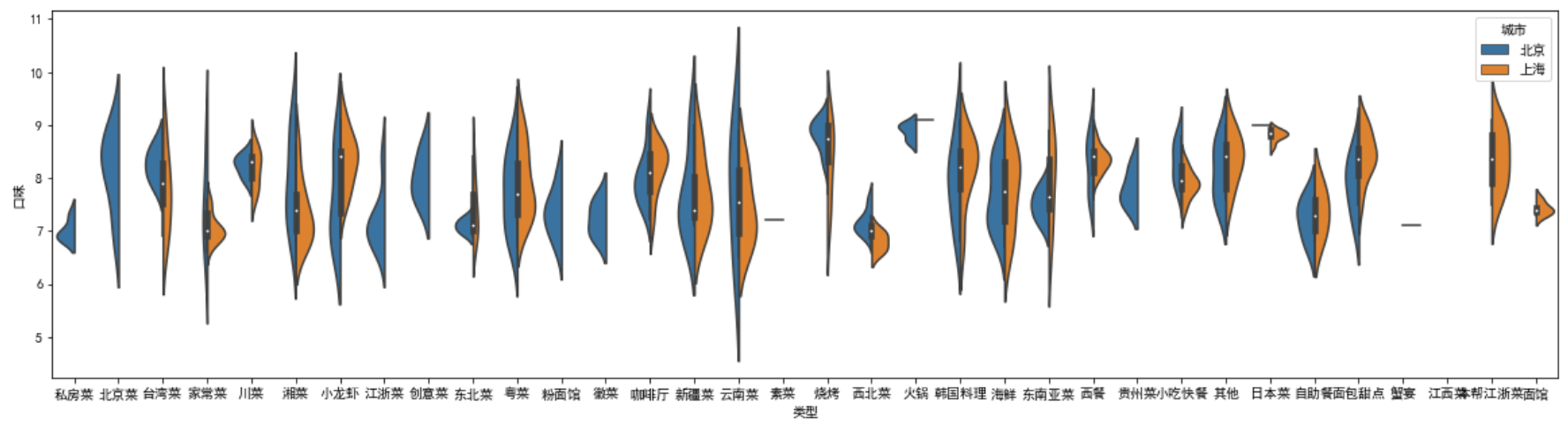 把北京和上海的拼接在一起
把北京和上海的拼接在一起
(3)因子图
sns.factorplot(x = , y = , data = , hue= , size= , aspect= , ci= , kind= , col= , col_wrap= )
参数:
- x:类型
- y:数值
- hue:x轴本身已经进行分类好之后,再去进行一个对比(一个图里对比)
- data:数据来源
- ci:透明度
- kind:默认为point(即折线图+竖线),也可以改为box(箱线图)、violin(提琴图)等
- size:宽
- aspect:高度,数字越大高度越小/窄
- col:散点图矩阵的功能,根据 col参数 的值,拆分成不同的图(拆分子图的方式来对比)
- col_wrap:设置每行最多显示多少个图
- 可以通过调整参数达到其他图的效果
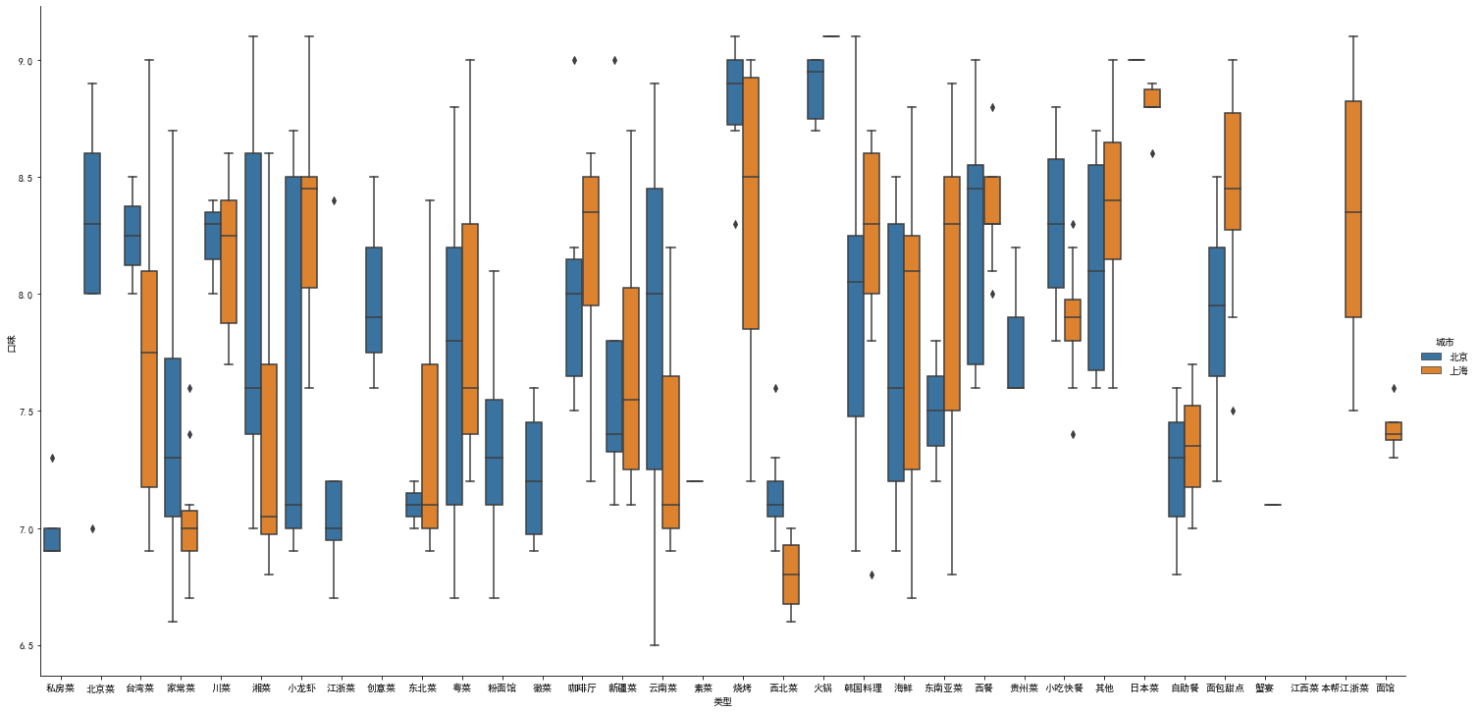
sns.factorplot(x = '类型', y = '口味', data = df, size=10)
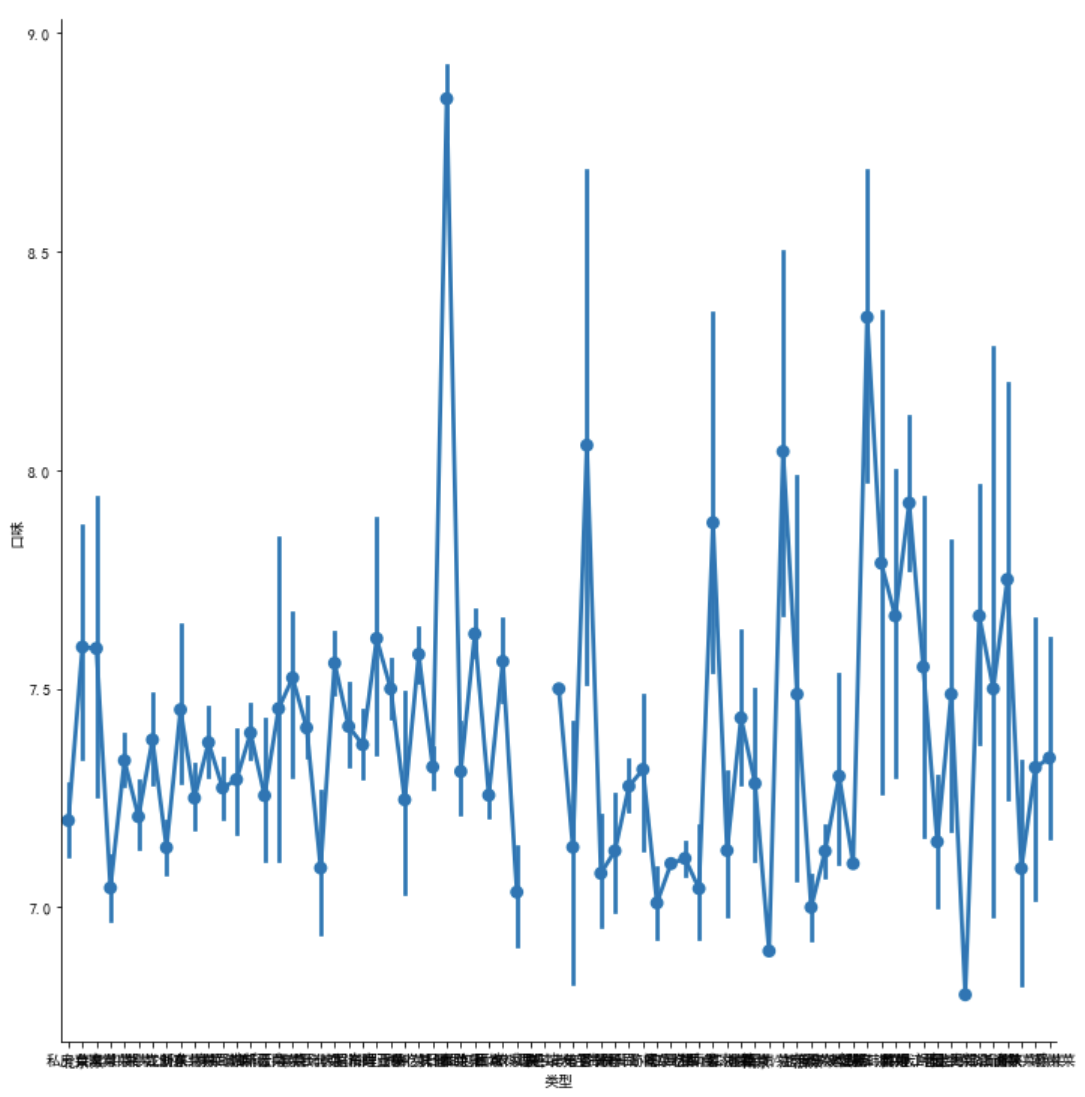
sns.factorplot(x = '类型', y = '口味', hue='城市', data = df2, size=10)
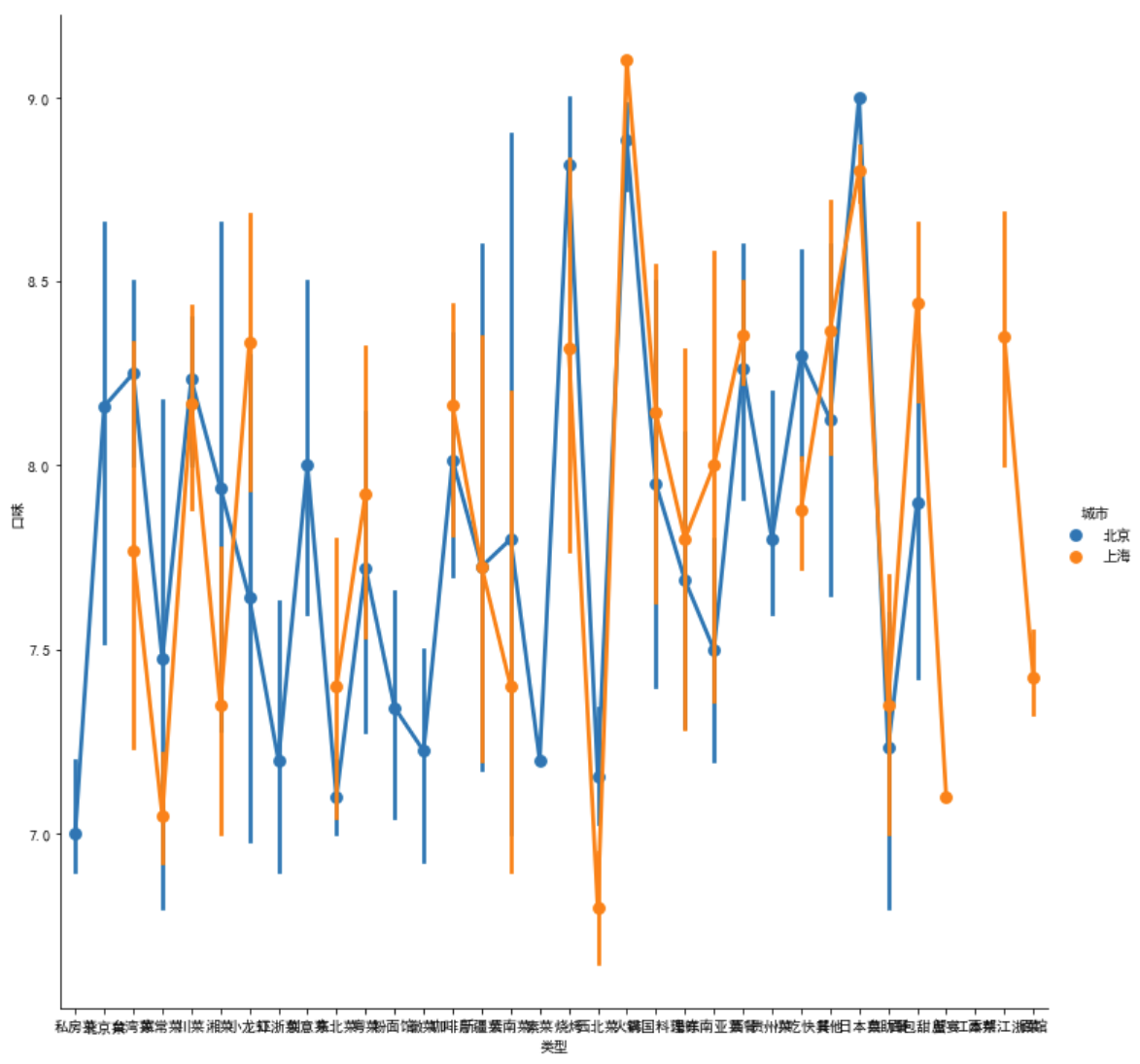
sns.factorplot(x = '类型', y = '口味', hue='城市', kind='box', data = df2, size=10) # kind默认为point(折线图+竖线)
sns.factorplot(x = '类型', y = '口味', hue='城市', kind='box', data = df2, size=10, aspect=2) # 调整高度,数字越大高度越小
sns.factorplot(x = '类型', y = '口味', hue='城市', kind='violin', data = df2, size=10, aspect=4)
- 散点图矩阵的效果(数据类型太多时不建议,一般最多6-7个类别)
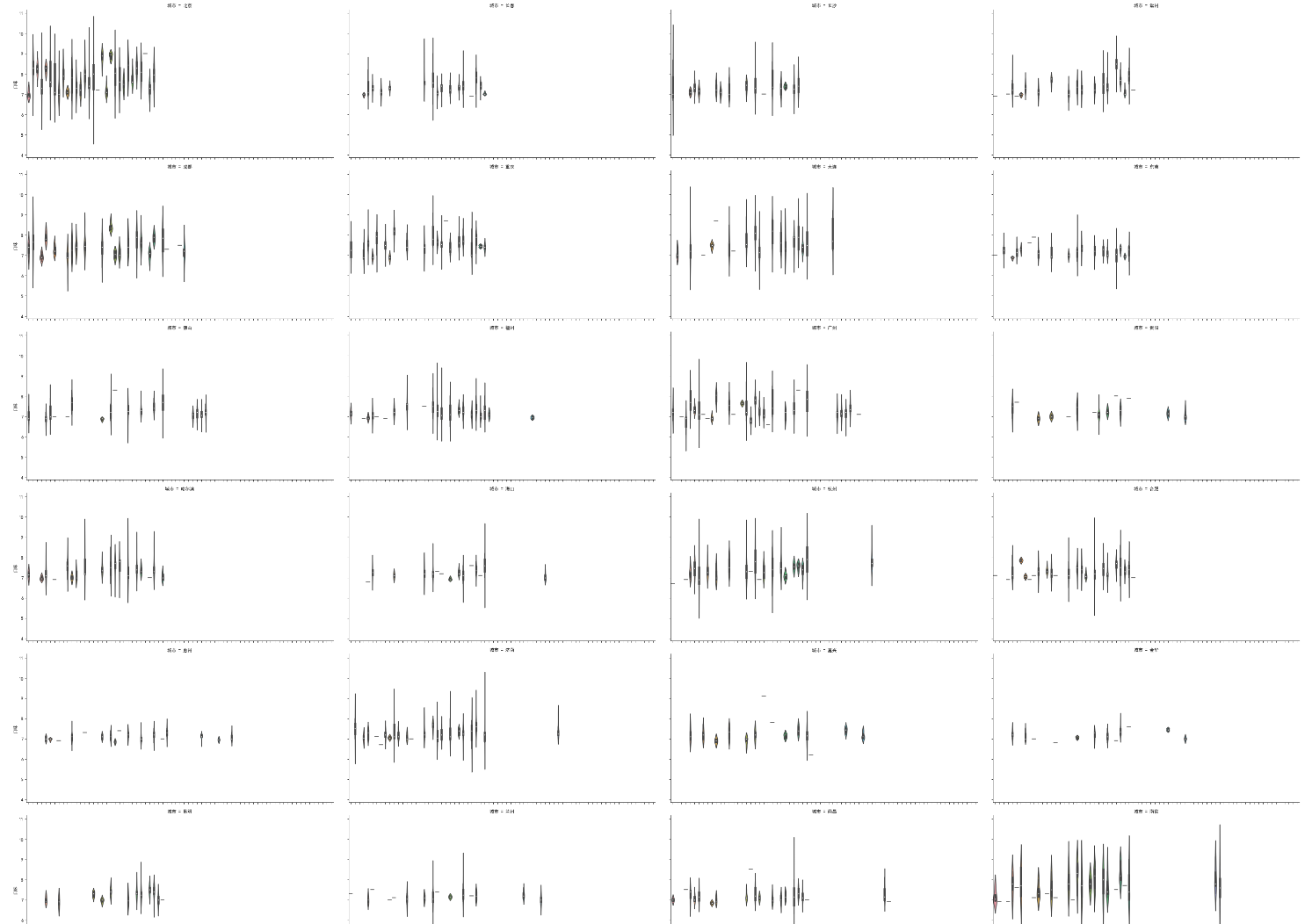
# 散点图矩阵功能 sns.factorplot(x = '类型', y = '口味', col='城市', kind='violin', data = df2, size=5, aspect=2) # size宽,aspect高
# 设置每行最多显示多少个图,col_wrap sns.factorplot(x = '类型', y = '口味', col='城市', kind='violin', data = df, size=5, aspect=2, col_wrap=4) # 行数会自动计算
3. 线性
- lmplot 回归图(两个数值变量之间的关系)
- heatmap 热力图(揭示变量之间的关系)
(1)回归图
sns.lmplot(x= , y= , data= , hue= , col= , row= , order= )
参数:
- x:自变量
- y:因变量
- data:数据来源,里面可以添加 query条件 做筛选
- hue:同一个图里分类
- col:拆分成子图的方式分类(排在一行里,即不同列)
- row:拆分成子图的方式分类(排在一列里,即不同行)
- order:拟合曲线规律,默认为1(一次线性方程)
sns.lmplot(x='口味', y='点评', data=df.query('点评<2000')) # 随着口味变好,点评数的变化
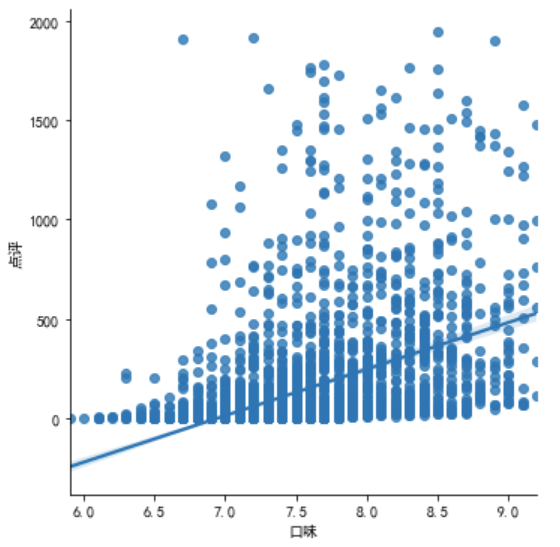
回归图虽然能拟合出一条直线,但不代表两者之间有规律或线性关系
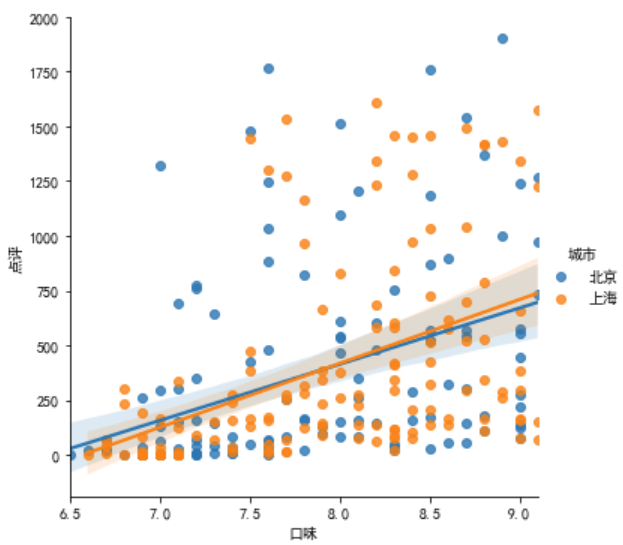
sns.lmplot(x='口味', y='点评', data=df2.query('点评<2000'), hue='城市')
sns.lmplot(x='口味', y='点评', data=df2.query('点评<2000'),col='城市')
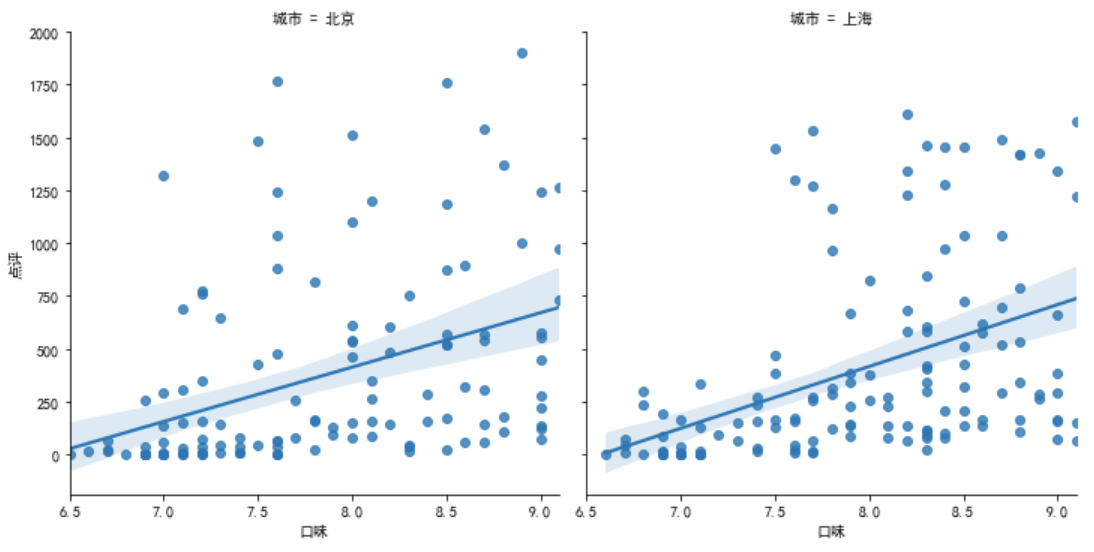
sns.lmplot(x='口味', y='点评', data=df2.query('点评<2000'),row='城市')
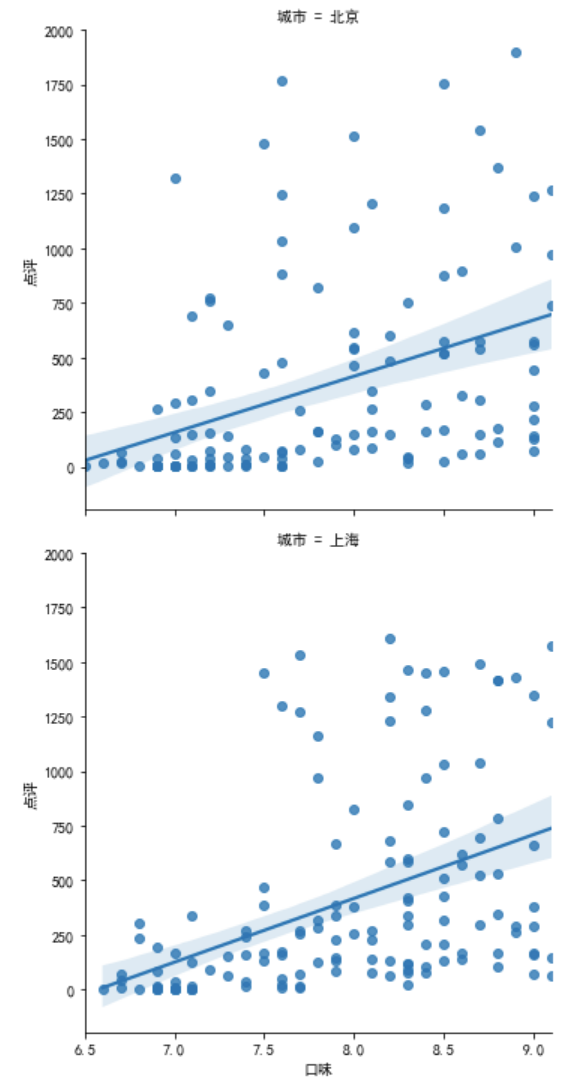
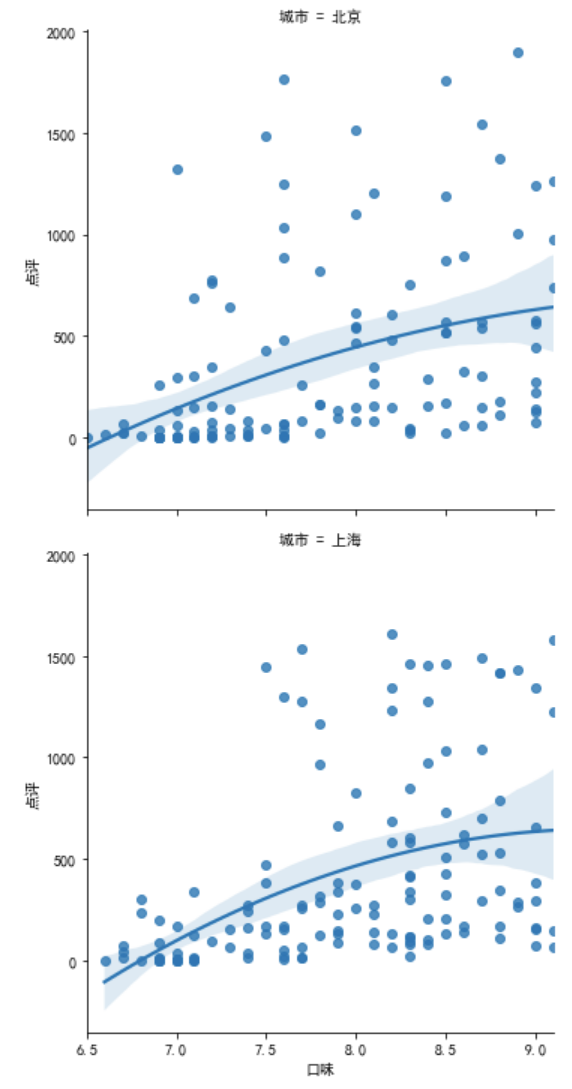
# 拟合曲线规律,order,默认为1(一次线性方程)
sns.lmplot(x='口味', y='点评', data=df2.query('点评<2000'), row='城市', order=2)
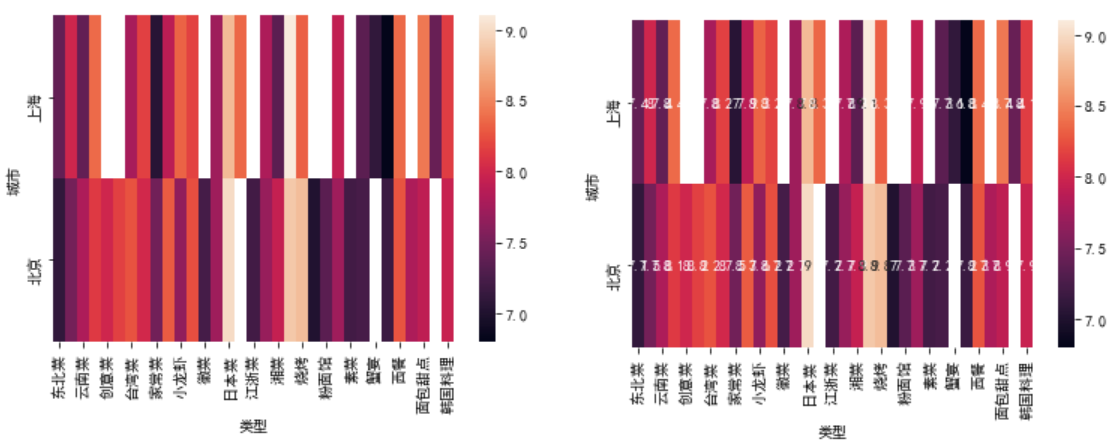
(2)热力图
# 城市和类型 pt = df2.pivot_table(index='城市', columns='类型', values='口味', aggfunc='mean') pt
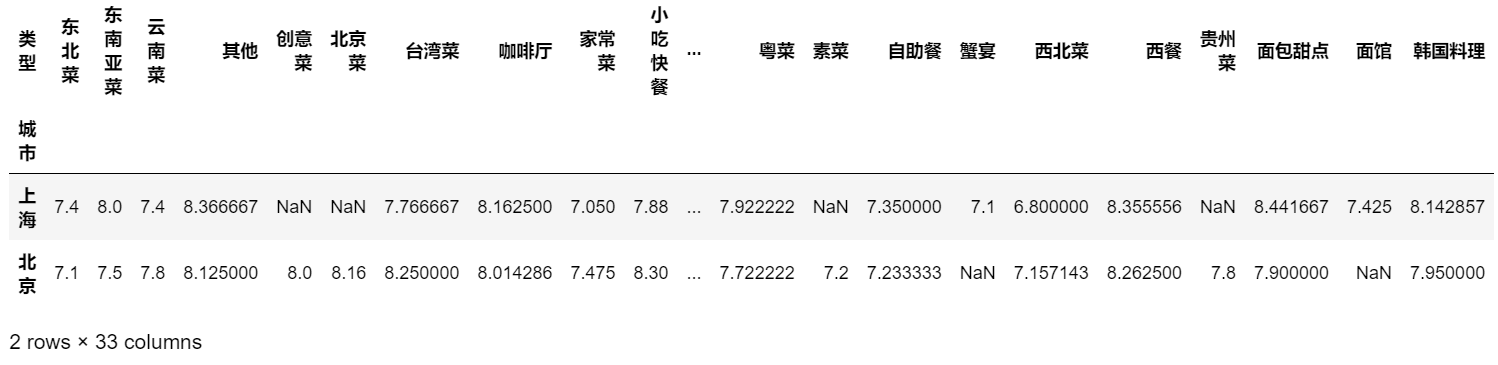
sns.heatmap(pt) # 左图 sns.heatmap(pt, annot=True) # 显示数值,右图
日期中常用,时间上的波动性

