
前言
大家早好、午好、晚好吖~

-
python 3.8 运行代码
-
pycharm 2021.2 辅助敲代码
-
requests 发送请求 模块
-
parsel 解析数据 模块
-
发送请求
-
获取数据
-
解析数据
-
保存数据
import requests # 第三方模块
import re
import parsel
import urllib
import prettytable as pt
源码、教程 点击 蓝色字体 自取 ,我都放在这里了。
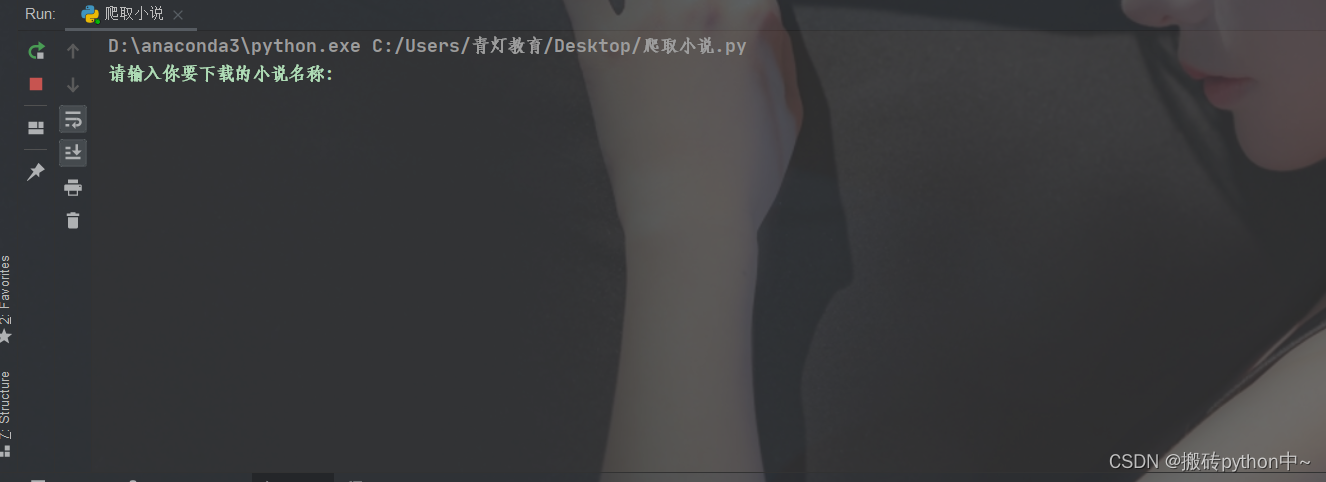
keyword = input("请输入你要下载的小说名称:")
keyword = urllib.parse.quote(keyword.encode('gb2312'))

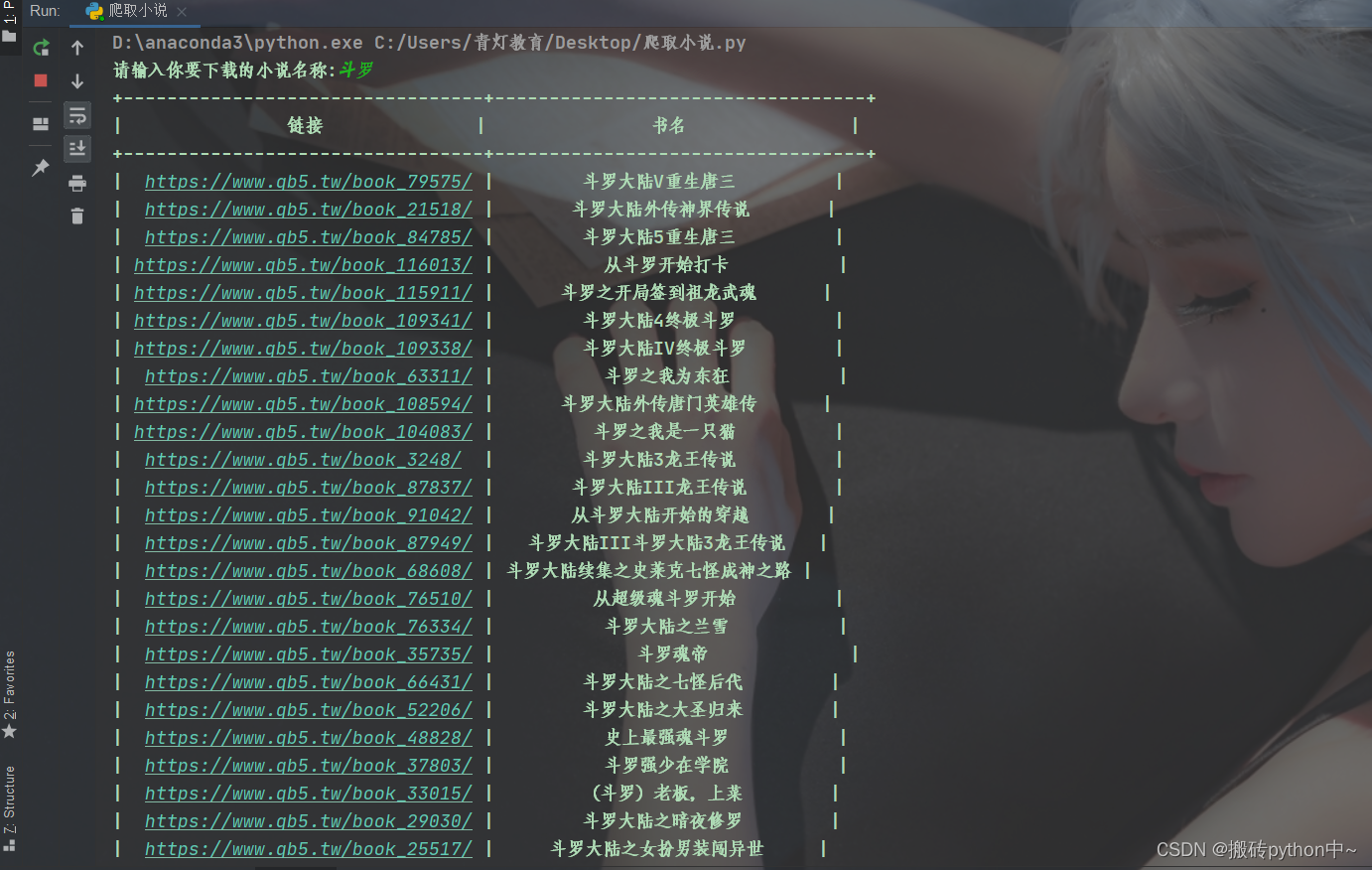
search_html = requests.get(search_url).text
info_list = re.findall('(.*?)', search_html)
tb = pt.PrettyTable()
tb.field_names = ['链接', '书名']
tb.add_rows(info_list)
print(tb)
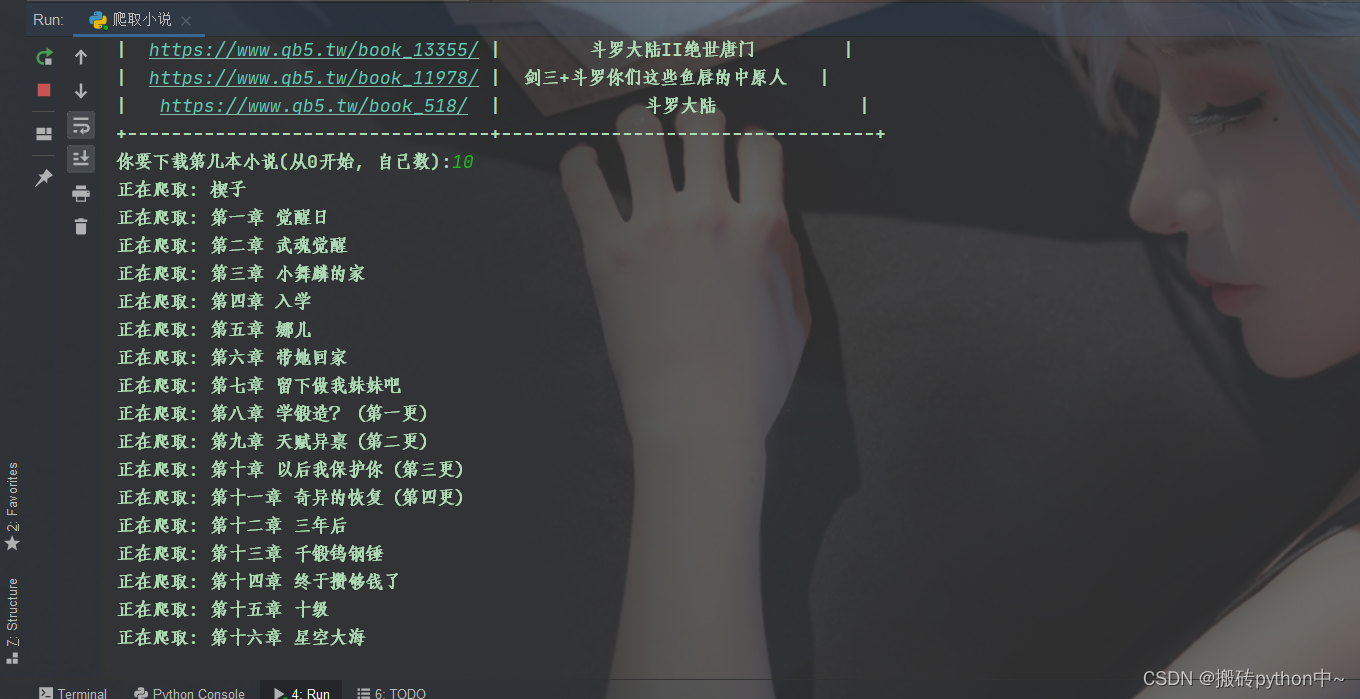
index = eval(input('你要下载第几本小说(从0开始, 自己数):'))
main_url = info_list[index][0]
main_html = requests.get(main_url).text
select = parsel.Selector(main_html)
subUrlList = select.css('.zjlist dd a::attr(href)').getall()
for subUrl in subUrlList:
url = main_url + subUrl
1. 发送请求
response = requests.get(url)
解决乱码
# response.encoding = 'gbk'
# response.encoding = response.apparent_encoding
: 请求成功
2. 获取数据
html_data = response.text
3. 解析数据
css / xpath / re 方式 / 语法规则
bs4 / lxml / parsel / re 模块…
非结构化的数据 网页源代码 css / xpath / re
结构化数据 json数据 字典键值对方式/re
re: 正则表达式
搜索功能 高级版本
# .*?
content = re.findall('(.*?)', html_data)[0]
# (.*?)
title = re.findall('(.*?)', html_data)[0]
print('正在爬取:', title)
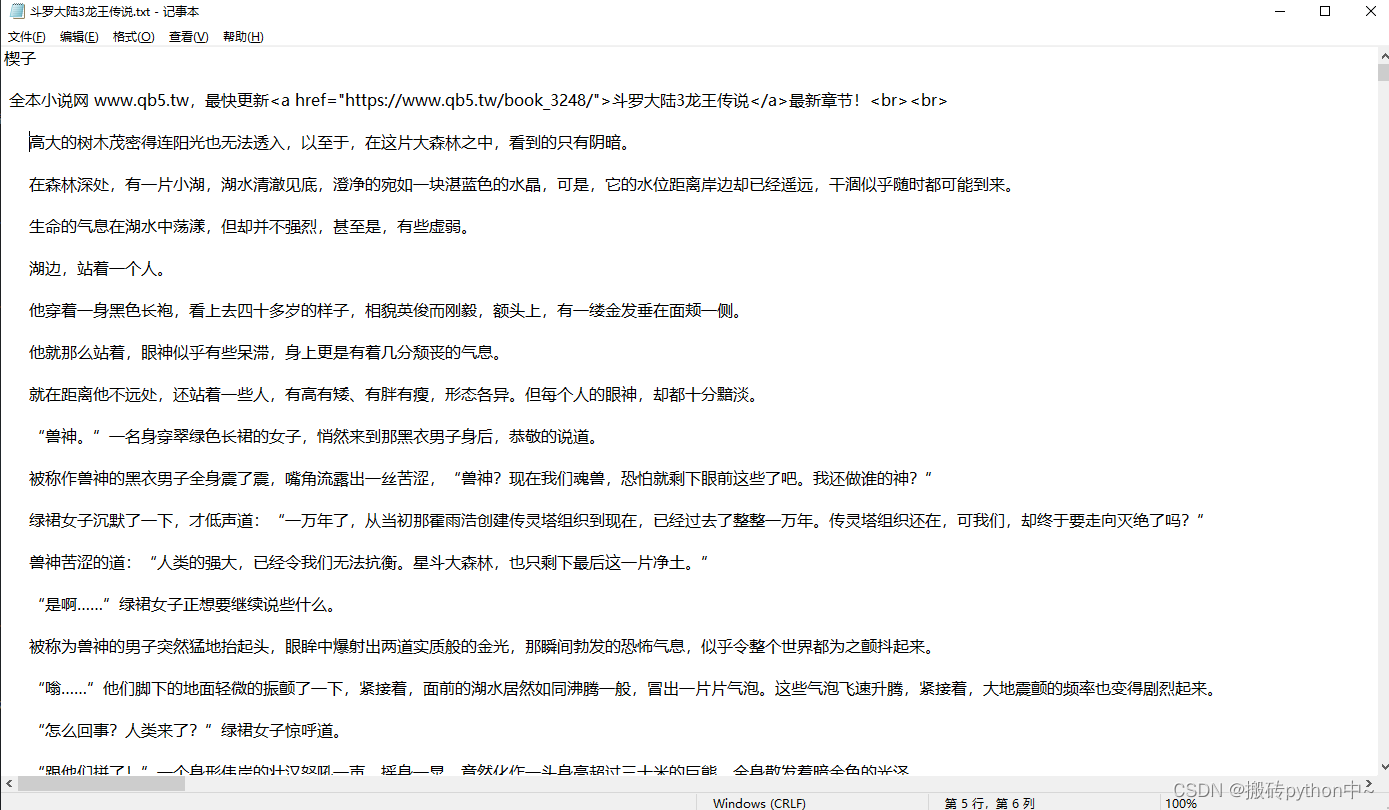
content = content.replace('', '\n').replace(' ', ' ').replace('全本小说网 www.qb5.tw,最快更新完美世界最新章节!', '')
text = title + '\n\n' + content + '\n\n'
# print(text)
: 换行
: 空格
最快更新完美世界最新章节!
4. 保存数据
with open(f'{info_list[index][1]}.txt', mode='a', encoding='utf-8') as f:
f.write(text)
文章看不懂,我专门录了对应的视频讲解,本文只是大致展示,完整代码和视频教程点击下方蓝字
点击 蓝色字体 自取,我都放在这里了。
尾语 💝好了,我的这篇文章写到这里就结束啦!
有更多建议或问题可以评论区或私信我哦!一起加油努力叭(ง •_•)ง
喜欢就关注一下博主,或点赞收藏评论一下我的文章叭!!!


