1 python按照页数拆分PDF文档
目的: 将一个PDF文档按照指定的页数拆份额为多个文档 思路: 使用PyPDF库中的PdfFileReader, PdfFileWriter类,这两个类是PyPDF2的核心,完成PDF文件的读写操作。
# 安装包
pip install PyPDF2
# 导入包
from PyPDF2 import PdfFileReader, PdfFileWriter
import os
# 读取 PDF 文件
path = './保利发展.pdf'
# 读取PDF文件
input_file = PdfFileReader(path)
# 要拆分的页数(每个文件)
page_bins=20
#总页数
page_sum = input_file.getNumPages()
#文件名
fname = os.path.splitext(os.path.basename(path))[0]
# 创造一个空的PDF
pdf_writer = PdfFileWriter()
# 循环取出写入,页数从0开始,page+1为实际的文件页码
for page in range(page_sum):
# 如果剩下的页数大于要拆分的页数,则继续拆分,否则就输出
if page_sum - page >= page_sum % page_bins:
# 获取某一页 input_file.getPage(1)
pdf_writer.addPage(input_file.getPage(page))
# 页数 可以对 要拆分的页数 整除,则保存
if (page+1) % page_bins == 0:
output_filename = f'{fname}_page_{page-page_bins+2}-{page+1}.pdf'
# 创建一个文件,这个文件是PDF文件
with open(output_filename, 'wb') as out:
pdf_writer.write(out)
print(f'已创建: {output_filename}')
pdf_writer = PdfFileWriter()
else:
continue
else:
pdf_writer.addPage(input_file.getPage(page))
if (page+1) == page_sum:
output_filename = f'{fname}_page_{page_sum - page_sum % page_bins+1}-{ page_sum }.pdf'
with open(output_filename, 'wb') as out:
pdf_writer.write(out)
print(f'已创建: {output_filename}')
 PDF拆分结果:
PDF拆分结果: 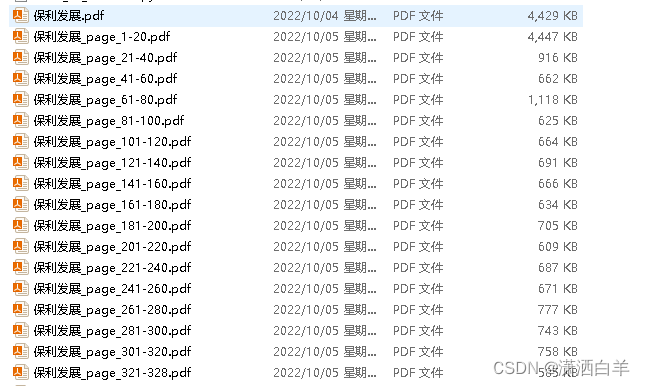
# 导入包
import os
from PyPDF2 import PdfFileReader, PdfFileWriter
# 实例化写入对象,就是创造一个可以写入PDF内容的变量
output_file = PdfFileWriter()
# 读取全部PDF
all_pdfs = os.listdir('E:/火狐下载/data/')
# 按照页数结尾页排序,用sort来排序
all_pdfs.sort(key=lambda x: int(x[x.find('-')+1:x.find('.')]))
# 循环写入
for i in all_pdfs:
if os.path.splitext(i)[-1][1:] == 'pdf':
print(i,'已合并完成')
input_file = PdfFileReader(f'E:/火狐下载/data/{i}')
pageCount = input_file.getNumPages()
for iPage in range(pageCount):
output_file.addPage(input_file.getPage(iPage))
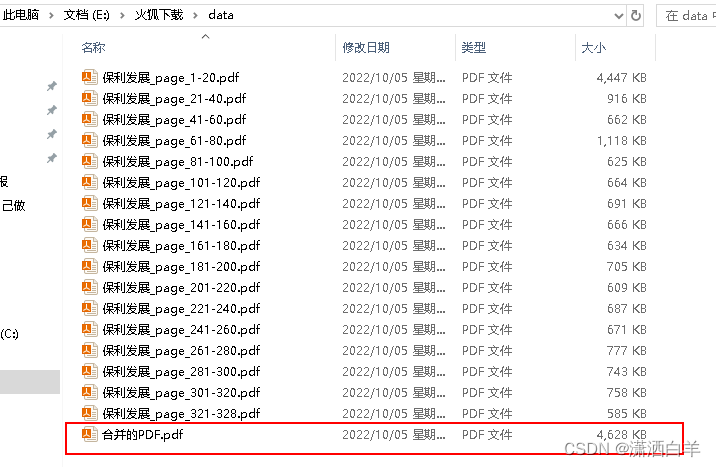
with open('E:/火狐下载/data/合并的PDF.pdf', "wb") as outputfile:
# 注意这里的写法和正常的上下文文件写入是相反的
output_file.write(outputfile)
 注意:
注意:
因为合并时,要按照页数正确合并,所以文件需要排好序再合并。
# 导入包
import os
from PyPDF2 import PdfFileReader, PdfFileWriter
# 读取全部PDF
all_pdfs = os.listdir('E:/火狐下载/data/')
all_pdfs
 这些文件没有按照我想要的顺序进行排序,而是按照字符串进行的排序
这些文件没有按照我想要的顺序进行排序,而是按照字符串进行的排序
# 排序方式一:获取结尾页码,按照页码进行排序
all_pdfs.sort(key=lambda x: int(x[x.find('-')+1:x.find('.')]))
all_pdfs

#获取所在文件的全路径
all_pdfs_all =list(map(lambda i: 'E:/火狐下载/data/'+i, all_pdfs))
all_pdfs_all
#排序方式二
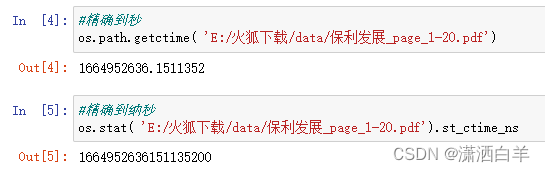
all_pdfs_all.sort(key=lambda x: os.path.getctime(x)) # 精确到秒
#排序方式三
all_pdfs_all.sort(key=lambda x: os.stat(x).st_ctime_ns) # 精确到纳秒