
- 简介
-
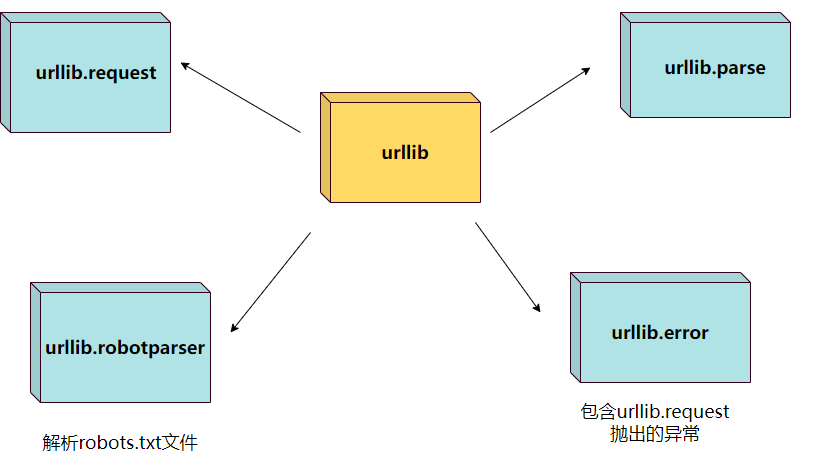
- 官方架构
- urllib.request
- urllib.error
- urllib.parse
- urllib.robotparser
- 案例一
- 案例二
- 案例三
- 案例四
- 案例五
urllib 库用于请求网页 URL,并对网页的内容进行抓取处理。对比request的话不是很方便,个人更偏向于使用request。
urllib 包含以下几个模块:
模块 说明 urllib.request 打开或读取url urllib.error urllib.request 抛出的异常 urllib.parse 解析url urllib.robotparser 解析robots.txt 官方架构
urllib.request 定义了一些打开 URL 的函数和类,包含授权验证、重定向、浏览器 cookies等。
使用 urllib.request 的 urlopen 方法来打开一个 URL,格式如下:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, context=None)
说明:
- url:url 地址。
- data:发送到服务器的其他数据对象,默认为 None。
- timeout:访问超时时间。
- cafile 和 capath:cafile 为 CA 证书, capath 为 CA 证书的路径,使用 HTTPS 需要用到。
- context:ssl.SSLContext类型,用来指定 SSL 设置。
urllib.error 模块为 urllib.request 所引发的异常定义了异常类,基础异常类是 URLError。
urllib.error 包含了两个方法,URLError 和 HTTPError。
URLError 是 OSError 的一个子类,用于处理程序在遇到问题时会引发此异常(或其派生的异常),包含的属性 reason 为引发异常的原因。
HTTPError 是 URLError 的一个子类,用于处理特殊 HTTP 错误例如作为认证请求的时候,包含的属性 code 为 HTTP 的状态码, reason 为引发异常的原因,headers 为导致 HTTPError 的特定 HTTP 请求的 HTTP 响应头。
urllib.parseurllib.parse 用于解析 URL,格式如下:
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)
urllib.parse.urlparse(urlstring, scheme=‘’, allow_fragments=True) urlstring 为 字符串的 url 地址,scheme 为协议类型,
allow_fragments 参数为 false,则无法识别片段标识符。相反,它们被解析为路径,参数或查询组件的一部分,并 fragment 在返回值中设置为空字符串。
urllib.robotparserurllib.robotparser 用于解析 robots.txt 文件。
robots.txt(统一小写)是一种存放于网站根目录下的 robots 协议,它通常用于告诉搜索引擎对网站的抓取规则。
案例一# 导入urllib from urllib.request import urlopen # 发送请求 res = urlopen("https://www.baidu.com/") # 返回网页内容 print(res.read())
除了 read() 函数外,还包含以下两个读取网页内容的函数:
-
readline() - 读取文件的一行内容
-
readlines() - 读取文件的全部内容。
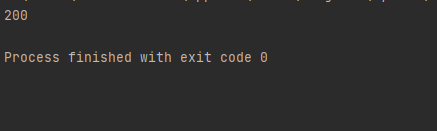
使用 getcode() 函数获取网页状态码
# 导入包 import urllib.request # 发送请求 res = urllib.request.urlopen("https://www.baidu.com/") # 返回状态码 print(res.getcode()) # 200
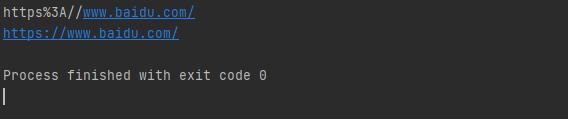
编码与解码可以使用 urllib.request.quote() 与 urllib.request.unquote() 方法:
# 导入包 import urllib.request
encode_url = urllib.request.quote("https://www.baidu.com/") # 编码 print(encode_url) unencode_url = urllib.request.unquote(encode_url) # 解码 print(unencode_url)
带上请求头
import urllib.request import urllib.parse
url = 'https://www.baidu.com/s?wd={}' code = urllib.request.quote('天气') # 对参数进行编码 url = url + code
header = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36' } #请求头 # 发送请求 request = urllib.request.Request(url,headers=header) # 返回网页内容 res = urllib.request.urlopen(request).read() print(res)
案例五
POST传递数据,与request区别很大,语法如下:
# 导入包 import urllib.request import urllib.parse
url = '' # 提交到表单页面 data = {'text': '你好'} # 提交数据 header = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.0.0 Safari/537.36' } #请求头 data = urllib.parse.urlencode(data).encode('utf8') # 对参数进行编码,解码使用 urllib.parse.urldecode request=urllib.request.Request(url, data, header) # 发送请求 reponse=urllib.request.urlopen(request).read() # 返回网页内容
点关注不迷路,本文若对你有帮助,烦请三连支持一下 ❤️❤️❤️ 各位的支持和认可就是我最大的动力❤️❤️❤️


