
目录
简介
- 简介
-
- 匹配模式
- re.match函数
-
- 案例
- re.search方法
-
- 案例
- re.match与re.search的区别
-
- 案例
- re.sub
-
- 案例
- re.findall
-
- 案例
- 正则修饰符
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。 Python re 模块提供了一些函数,使用一个模式字符串做为它们的第一个参数。
匹配模式 模式 描述 ^ 匹配字符串的开头 $ 匹配字符串的末尾 . 匹配任意字符,除了换行符 \d 匹配一个数字字符 \D 匹配一个非数字字符 \s 匹配任意空白字符,包括空格、制表符、换页符等等 \S 匹配任意非空白字符 \w 匹配包括下划线的任意单词字符 \W 匹配任意非单词字符 [0-9] 匹配任意数字 [a-z] 匹配任意小写字母 [A-Z] 匹配任意大写字母 .* 表示"贪婪"模式,除了换行符以外得任意单个或多个字符 .*? 表示"非贪婪"模式,只保存第一个匹配到的子串 re.match函数re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
语法:
re.match(pattern, string, flags=0)
- pattern – 匹配的正则表达式
- string – 匹配的字符串
- flags – 标志位,用于控制正则表达式的匹配方式
匹配方法:
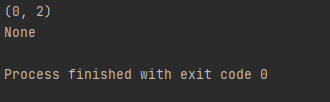
方法 描述 group() 匹配的整个表达式的字符串 groups() 返回一个包含所有小组字符串的元组 案例import re print(re.match('he', 'hello word').span()) # 在起始位置匹配 print(re.match('word', 'hello word')) # 不在起始位置匹配
re.search 扫描整个字符串并返回第一个成功的匹配。 语法:
re.search(pattern, string, flags=0)案例
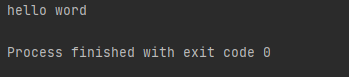
import re l = 'hello word' print(re.search( r'.*', l).group()) # 匹配所有字符串
re.match 只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回 None,而 re.search 匹配整个字符串,直到找到一个匹配。
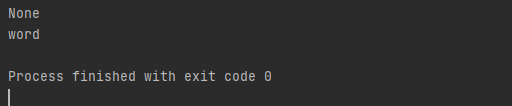
案例import re line = "hello word" match = re.match(r'word', line).group() \ if re.match(r'word', line) else None print(match) search = re.search(r'word', line, re.M | re.I).group() print(search)
re.sub用于替换字符串中的匹配项。 语法:
re.sub(pattern, repl, string, count=0, flags=0)
参数:
- pattern : 正则中的模式字符串。
- repl : 替换的字符串,也可为一个函数。
- string : 要被查找替换的原始字符串。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- flags : 匹配模式
import re
phone = "139-2030-0495" # 移除符号 num = re.sub(r'\D', "", phone) print("手机号: ", num)
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表
注意: match 和 search 是匹配一次,而 findall 匹配所有,也是经常用的匹配模块 语法:
re.findall(pattern, string, flags=0)
- pattern --匹配模式
- string – 待匹配的字符串
- flags – 匹配模式
import re
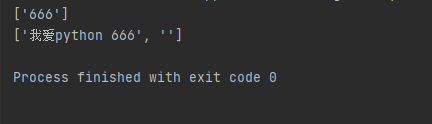
text = "我爱python 666" # 移除符号 res = re.findall(r'\d+',text) # 匹配数字 res1 = re.findall('.*',text,re.S) # 匹配所有 print(res) print(res1)
点关注不迷路,本文若对你有帮助,烦请三连支持一下 ❤️❤️❤️ 各位的支持和认可就是我最大的动力❤️❤️❤️


