
目录
解析
- 解析
- 代码实现
- 成果
-
打开网页,可以看到部分字体显示乱码,需要找到加密字体文件
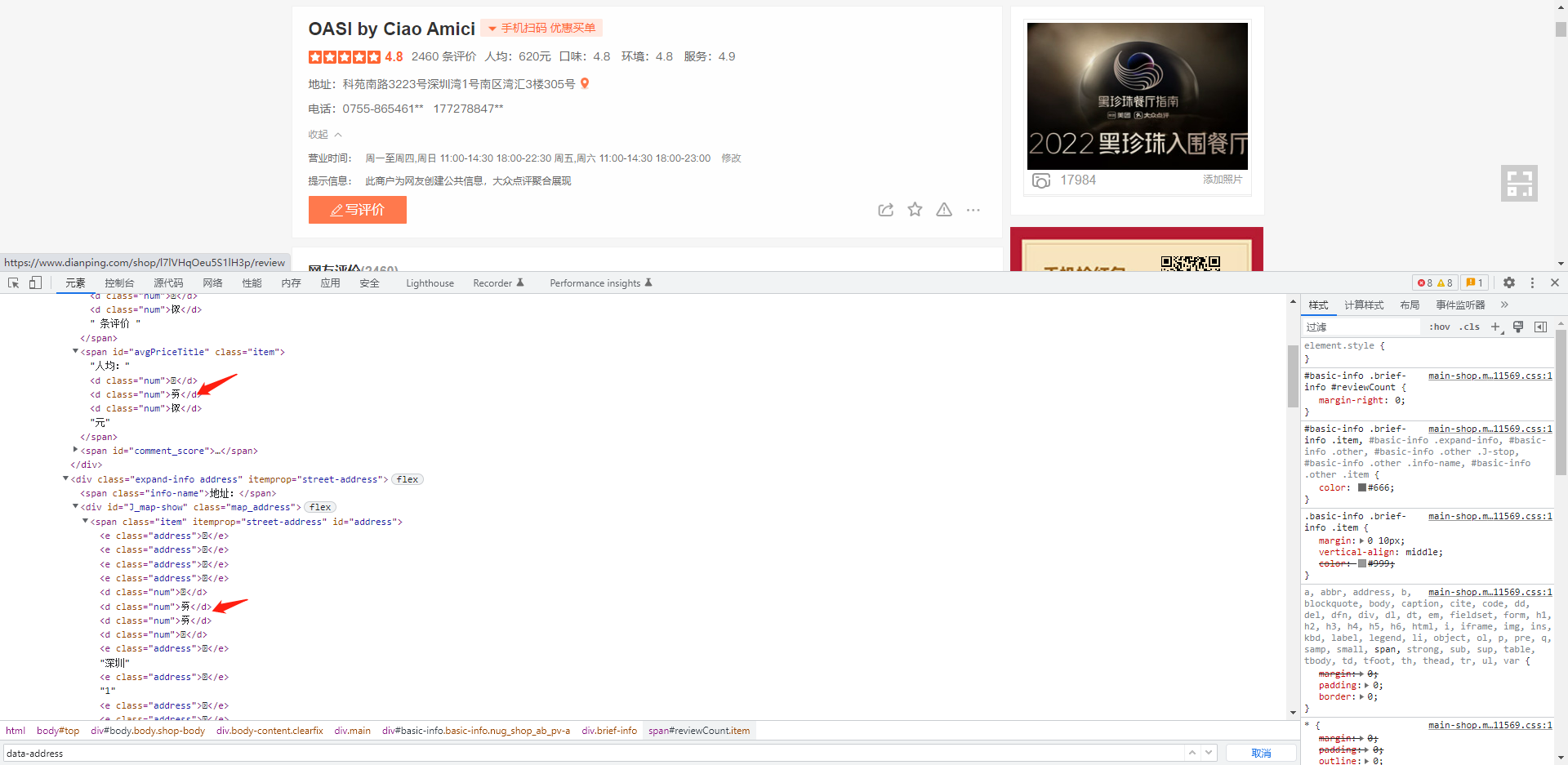
-
全局搜索woff文件,找到目标文件,随机点开一个
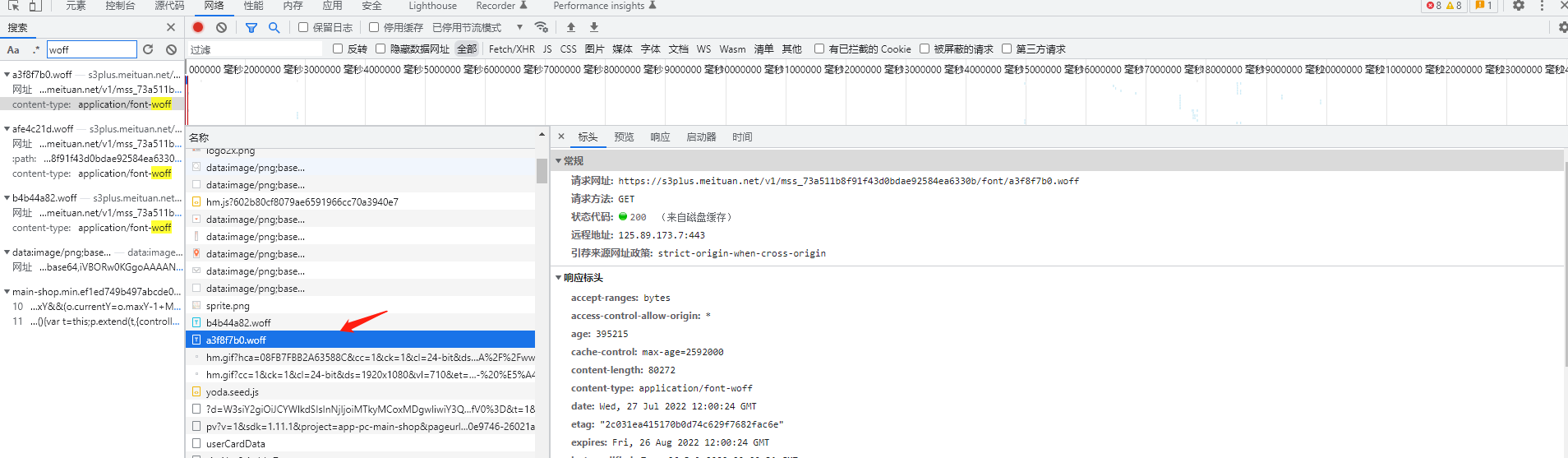
-
打开目标源代码,可以发现上面文件中有字体css
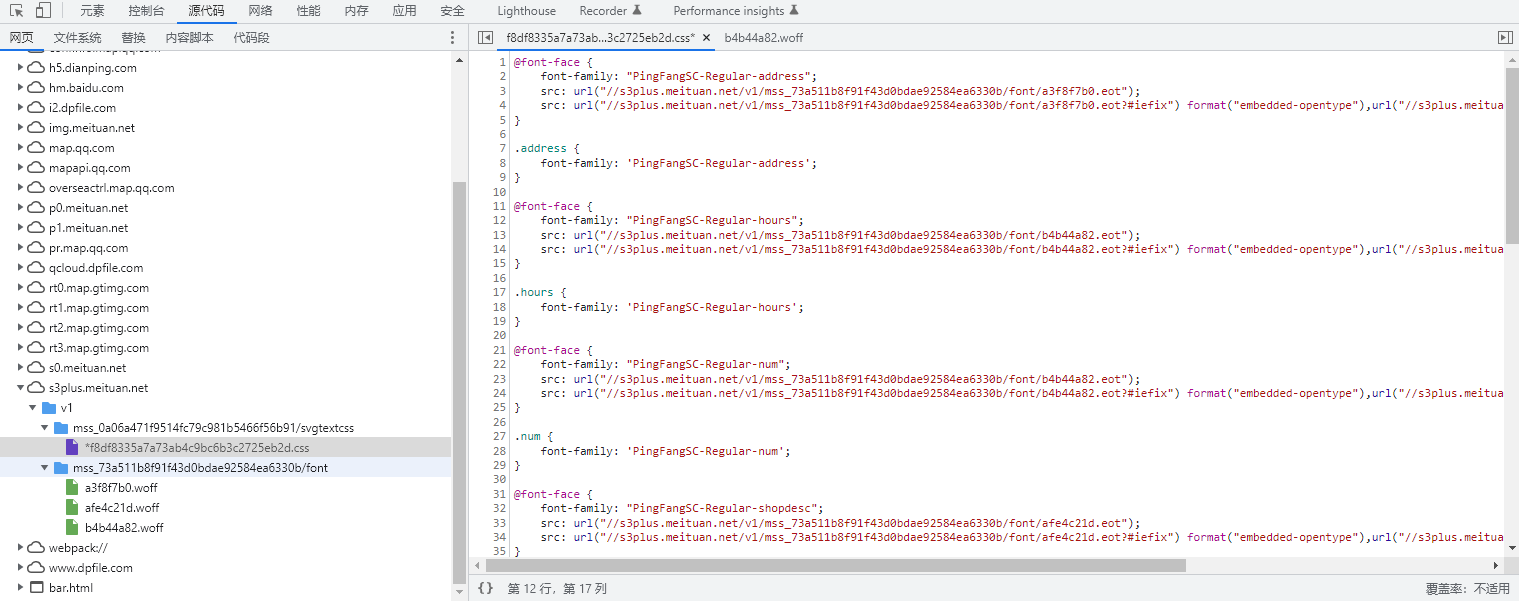
-
或者直接点击css,也能找到目标文件
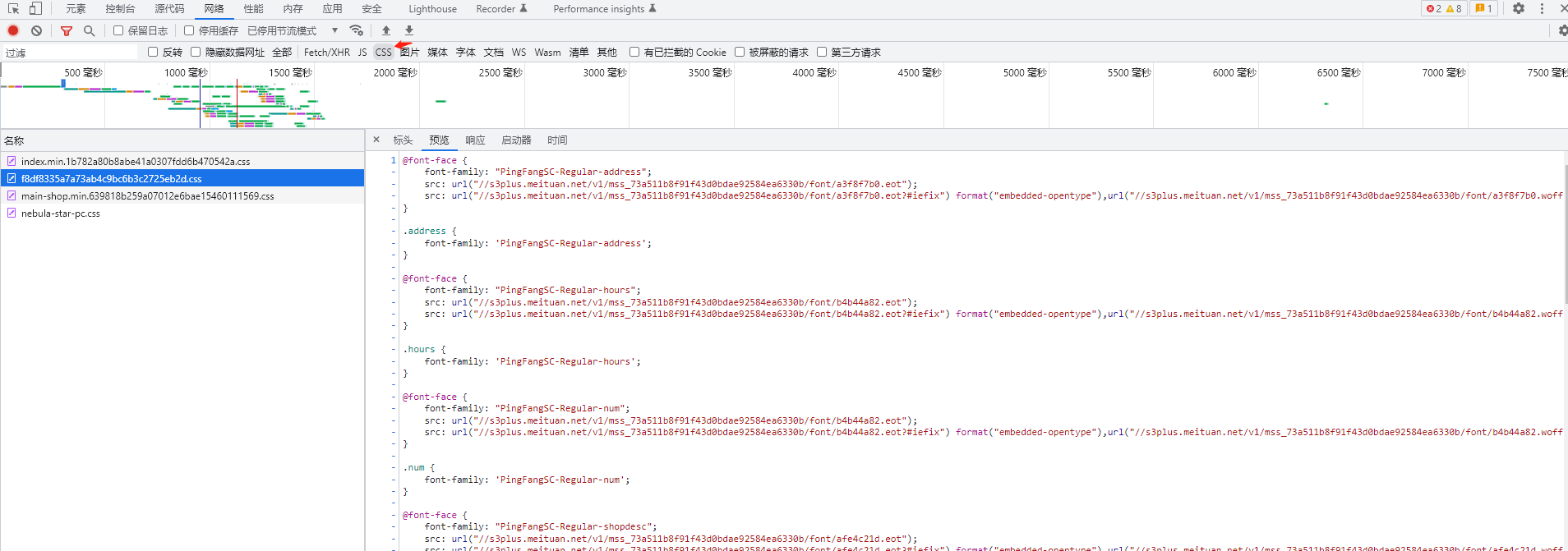
- 仔细观察,不难发现css中font-family,与网页中字体标签名称能对应上,说明哪些字体是用的哪个字体文件
- 请求css文件,通过正则匹配woff字体文件
def parse_css(): css_url = "https://s3plus.meituan.net/v1/mss_0a06a471f9514fc79c981b5466f56b91/svgtextcss/f8df8335a7a73ab4c9bc6b3c2725eb2d.css" header = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' } font_url_search = re.compile(r'font-family: "(.*?)".*?,url\("//(s3plus\.meituan\.net/v1/.*?\.woff)"\)') # 文件匹配规则`在这里插入代码片` css_font_response = requests.get(url=self.css_url,headers=header) # 请求css font_url_list = font_url_search.findall(css_font_response.text) # 获取字体文件 for font_name,font_url in font_url_list: font_response = requests.get(url="http://"+font_url,headers=header) #请求woff #将字体文件写入本地 font_name = font_name.split("-")[-1]+".woff" #字体名称 with open(font_name,'wb') as f: f.write(font_response.content)
-
保存所有字体文件到本地

-
地址标签名称是address,所以打开address.woff,利用某度字体编辑器解析字体文件
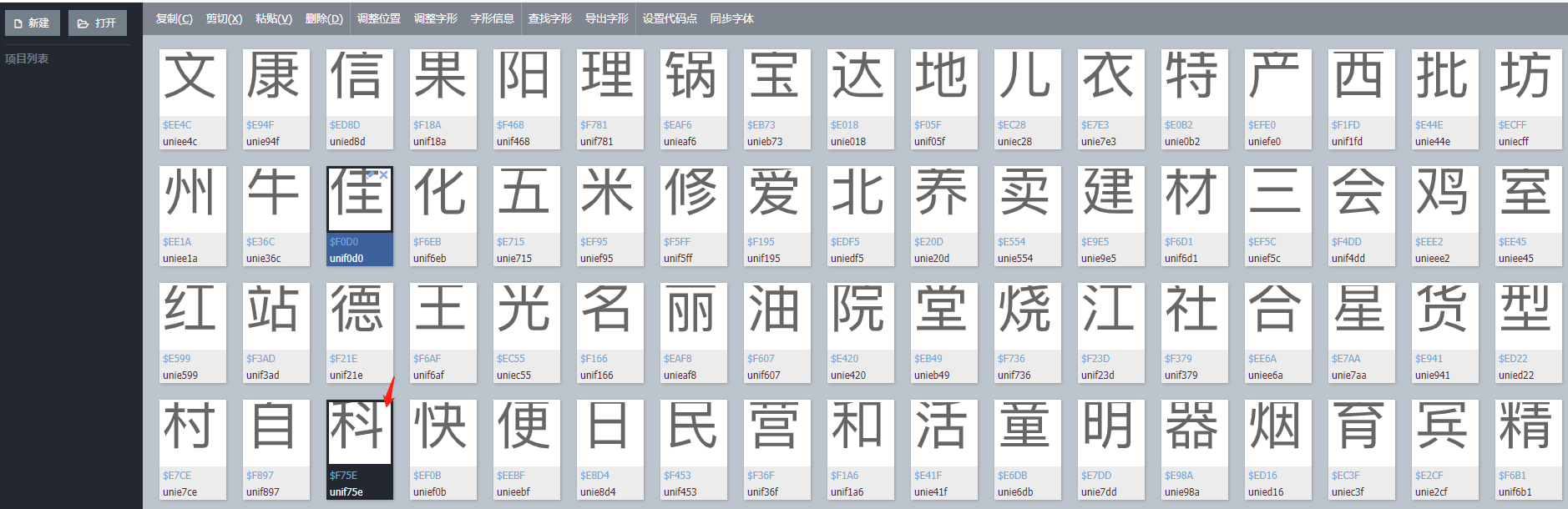
 发现后4位字符一致,所以这个woff文件就是这个字体的加密文件
发现后4位字符一致,所以这个woff文件就是这个字体的加密文件
-
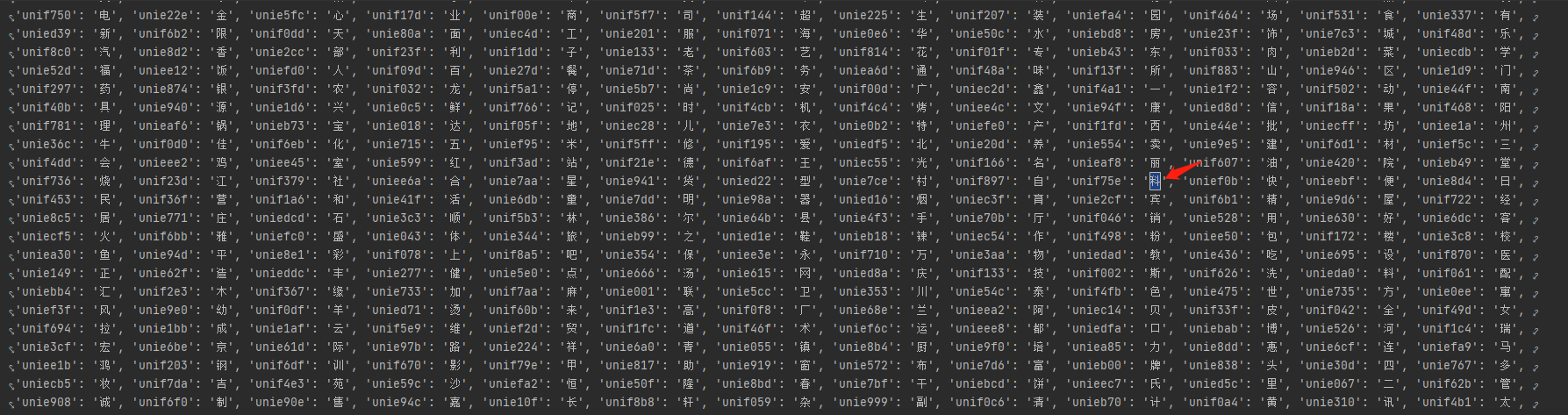
处理编码与字体的对应关系
def parse_font(): font_file = TTFont('address.woff') #保存字体和字符编码的对应关系 font_dict = json.dumps(dict(zip(font_file.getGlyphOrder(),FONT_LIST))) #写入本地 with open("font_dict",'w') as f: f.write(font_dict)

-
json解码
-
获取数据
def parse_detail(): """
请求大众点评页面
:return:
""" # self.parse_font() business_detail_url = "https://www.dianping.com/shop/l7lVHqOeu5S1lH3p" header = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' } response = requests.get(url=business_detail_url,headers=header) html = etree.HTML(response.text) #地址 address = html.xpath('//div[@id="J_map-show"]//span/e/text()') #读取本地字体对应文件 with open('font_dict','r') as f: f_read = json.loads(f.read()) for info in time: key = "uni"+json.dumps(info)[-5:][:-1] # 将前面&#x,后面的;去掉,转换为uni**** if key in f_read: print(f_read[key])
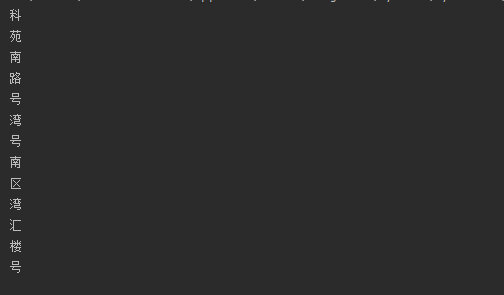
成果
点关注不迷路,本文若对你有帮助,烦请三连支持一下 ❤️❤️❤️ 各位的支持和认可就是我最大的动力❤️❤️❤️


