
本章节以博客园-新闻的爬取,来讲解scrapy的入门使用,分成上中下三篇
一.scrapy安装pip安装的时候是从国外的服务器下载,国内有一个非常常用的镜像,可以提高下载速度
pip install -i https://pypi.douban.com/simple scrapy
有些windows环境下安装scrapy会出错,安装出错则按下面的方式处理
https://www.lfd.uci.edu/~gohlke/pythonlibs/
这个网址可以直接下载会安装出错的包,安装scrapy需要下载下面4个,下载时需要选对应解释器的版本
lxmltwistedpywin32scrapy进入到下载目录下,按照以下方式安装,如果lxml等包有其依赖的包,也会通过镜像自动下载安装



 scrapy包放最后安装因为它依赖前面的3个包
scrapy包放最后安装因为它依赖前面的3个包
命令行输入:
scrapy startproject ArticleSpider
scrapy startproject 项目名称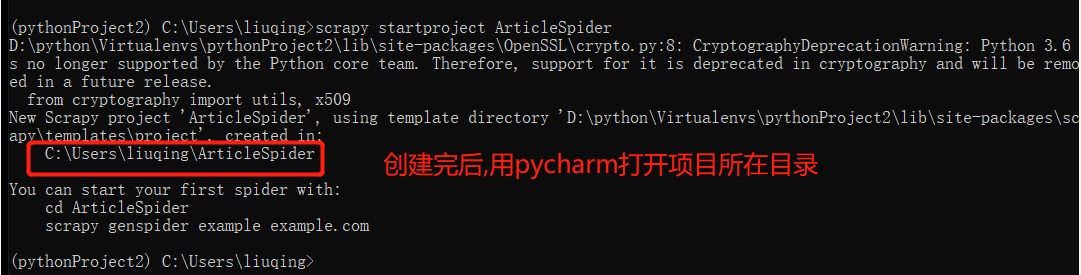
大家先不要着急了解每个文件的作用,后期会介绍到,命令行输入:
scrapy genspider cnblogs news.cnblogs.com
scrapy genspider 爬虫名称 抓取的网址
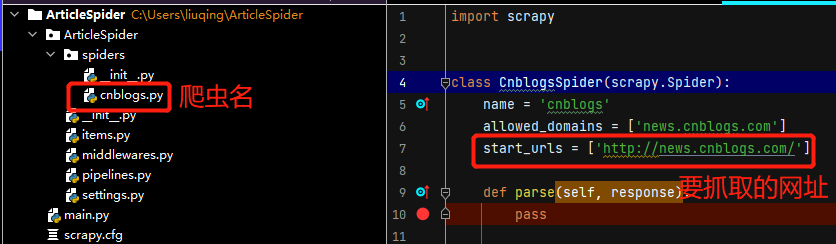
爬虫隶属于项目,一个项目下可以有多个爬虫,这就类似于Django项目和其下app的关系。
三.调试代码scrapy启动
通过命令行启动的爬虫程序,无法调试
scrapy crawl 爬虫名带运行日志
scrapy crawl 爬虫名 --nolog不带运行日志
crawl的英语翻译:爬行
在项目的目录下新建一个main.py(名字自取)内容如下,然后就可以鼠标右键debug这个爬虫
from scrapy.cmdline import execute import sys import os sys.path.append(os.path.dirname(os.path.abspath(__file__))) execute(["scrapy","crawl","cnblogs"])四.重点:response
当运行main.py,进入parse方法后,start_url里面的网址已经是被爬取下来的.
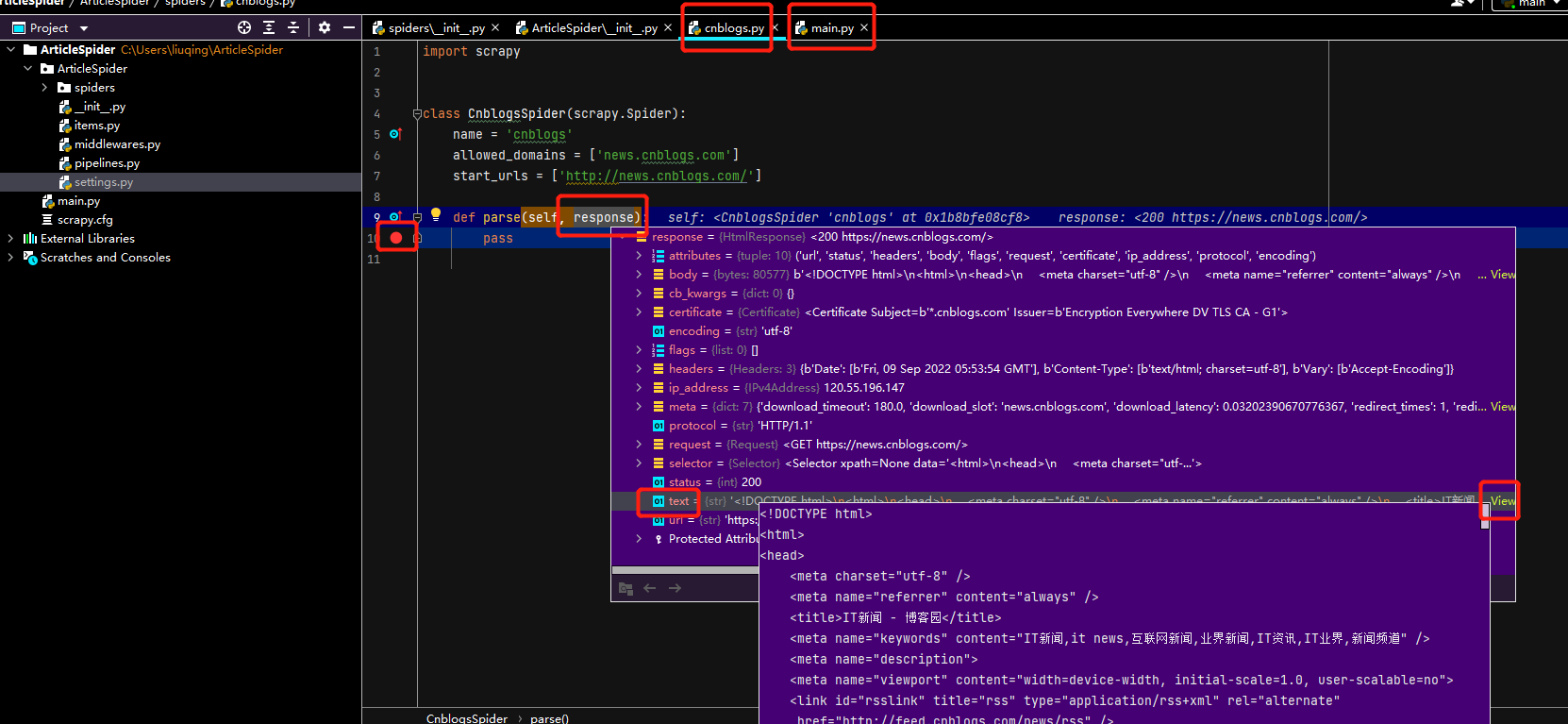
response对象可以使用xpath,css选择器来提取元素
title_list = response.css('.link-title')
title_list = response.xpath('//a[contains(@class,"link-title")]')
xpath/css可以看这篇
五. 重点:parse()方法parse()方法的使命是用来解析起始网址(start_url)中的url,并把这些url交给scrapy去下载;同时,解析下一页的url,交给scrapy去下载
这样,每一页的url,以及每一页中具体内容的url都被一层一层提取出来,交给scrapy下载了.
import scrapy from scrapy import Request from urllib import parse class CnblogsSpider(scrapy.Spider): name = 'cnblogs' allowed_domains = ['news.cnblogs.com']
start_urls = ['http://news.cnblogs.com/']
def parse(self, response): """
1.获取新闻列表页中的新闻url并交给scrapy进行下载后调用相应的解析方法
2.获取下一页的url交给scrapy进行下载,然后交给parse()方法进行提取新闻url来下载
""" post_nodes = response.css("#news_list .news_block")
for post_node in post_nodes:
image_url = post_node.css("div.entry_summary img::attr(src)").extract_first("")
post_url = post_node.css("div.content h2 a::attr(href)").extract_first("") # 新闻页标题:具体详情的url yield Request(url=parse.urljoin(response.url,post_url), # 这个请求会立马交给scrapy下载; meta={"front_image_url":image_url}, # meta用于传参 callback=self.parse_detail) # 下载好后回调真正提取数据的方法 # 提取下一页并交给scrapy下载 next_url = response.xpath('//div[@class="pager"]//a[contains(text(),"Next >")]/@href').extract_first("")
yield Request(url=parse.urljoin(response.url,next_url),callback=self.parse)
def parse_detail(self,response): # response参数是scrapy自动传递进来的,已经下载好的页面 pass
下一节:介绍解析详情页
本文由 mdnice 多平台发布

