
selinium可以执行JavaScript代码
from selenium import webdriver
bro= webdriver.Chrome(executable_path='chromedriver.exe')
bro.get('https://blog.csdn.net/nav/python')
js="window.scrollTo(0, document.body.scrollHeight); var lenOfPage=document.body.scrollHeight; return lenOfPage;" bro.execute_script(js)
scrapy爬虫的暂停与重启
打开命令行,进入当前项目的目录
启动项目:crawl spider 爬虫名 -s JOBDIR=自己新建的目录/001(或002...)
-s是safe的意思
将JOBDIR=自己新建的目录/001(或002...)这个也可以设置在每个爬虫单独的setting中
因为要暂停和重启,就需要提供一个目录,将spider中间状态的信息放在这个目录下,这样就能实现; 不同的spider使用不同的子目录
另外,需要在命令行中启动,而不能从pycharm中启动,因为命令行可以接收Ctrl+c中断信号
按一次Ctrl+c,程序会暂停,并处理一些善后工作,比如已经发出去的request要等它返回.(注意:ctrl+c连按两次会强制关掉进程,不会保存中间信息)
暂停后会生成以下中间信息
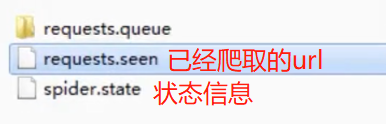
命令行中输入一模一样的启动命令crawl spider 爬虫名 -s JOBDIR=自己新建的目录/001(或002...),就会接着中间状态继续爬取
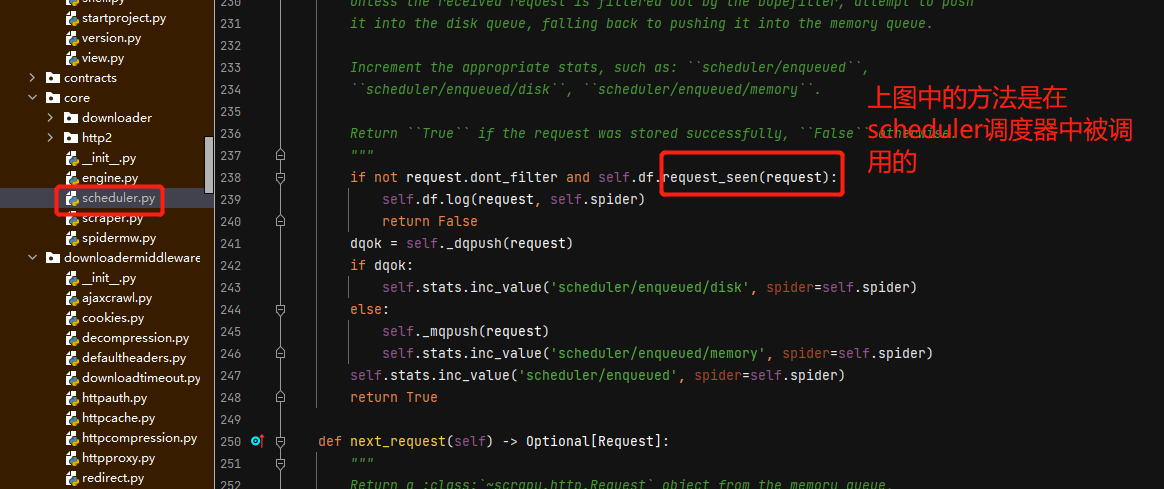
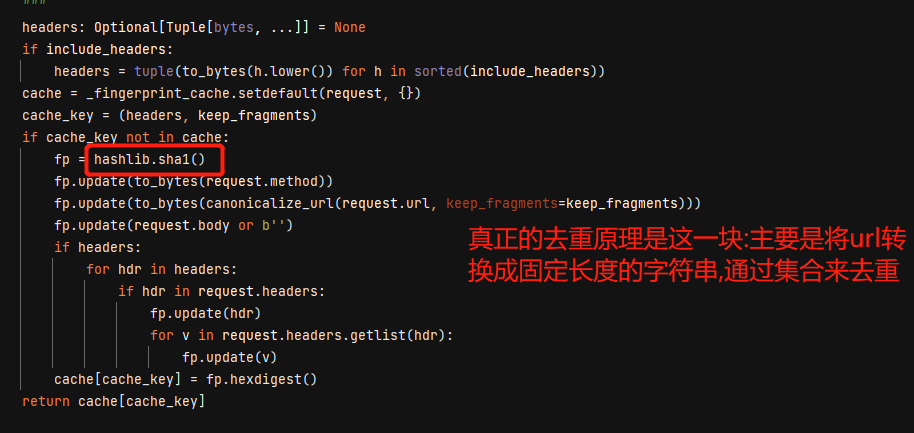
scrapy去重的原理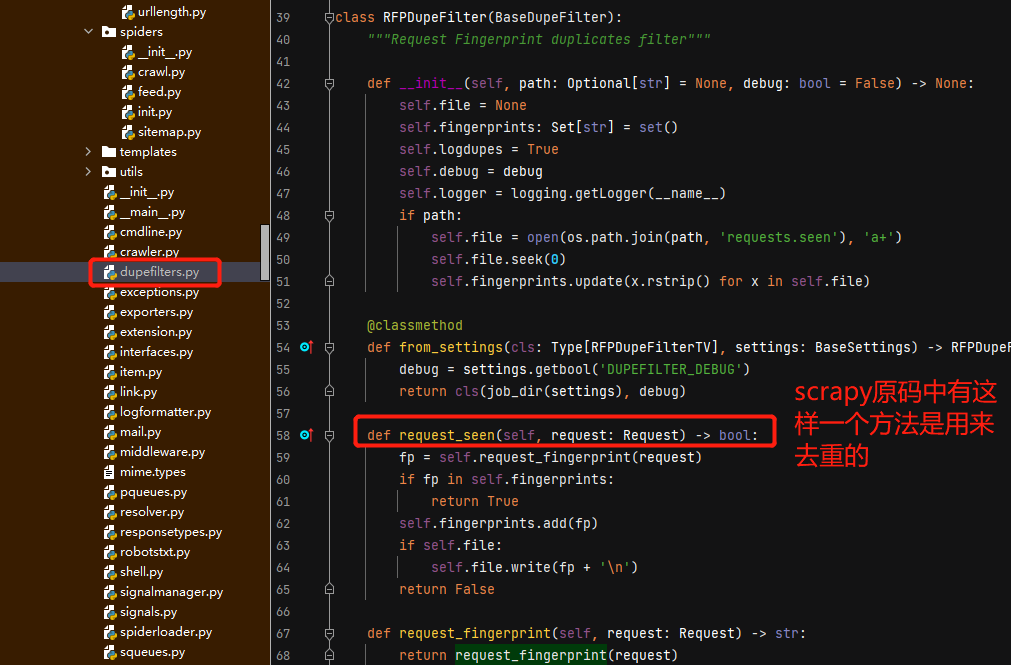
 scrapy telnet服务
scrapy telnet服务
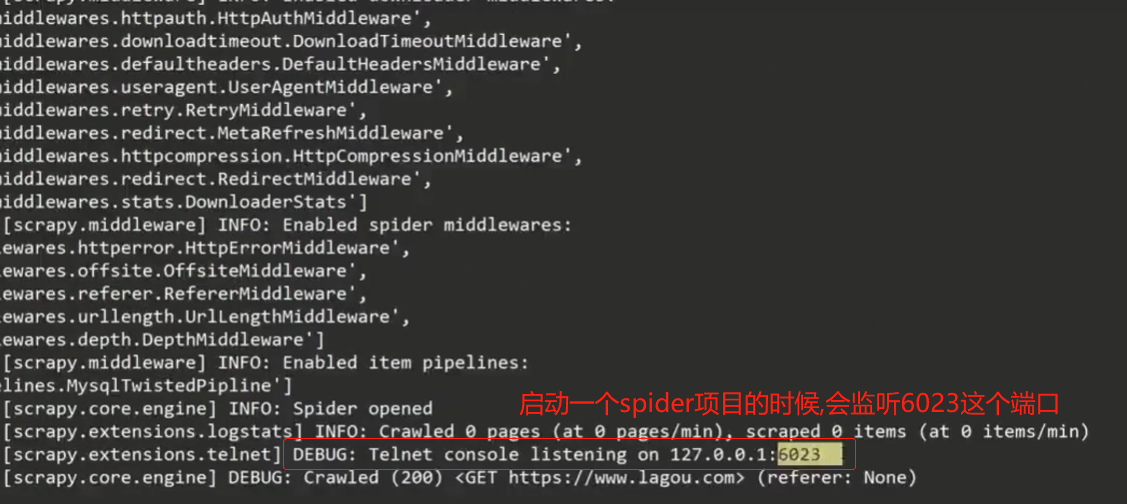
此时就可以通过cmd终端输入telnet ip地址 端口连接,然后可以输入est()获取spider的状态,同时,这里可以输入变量来获取值 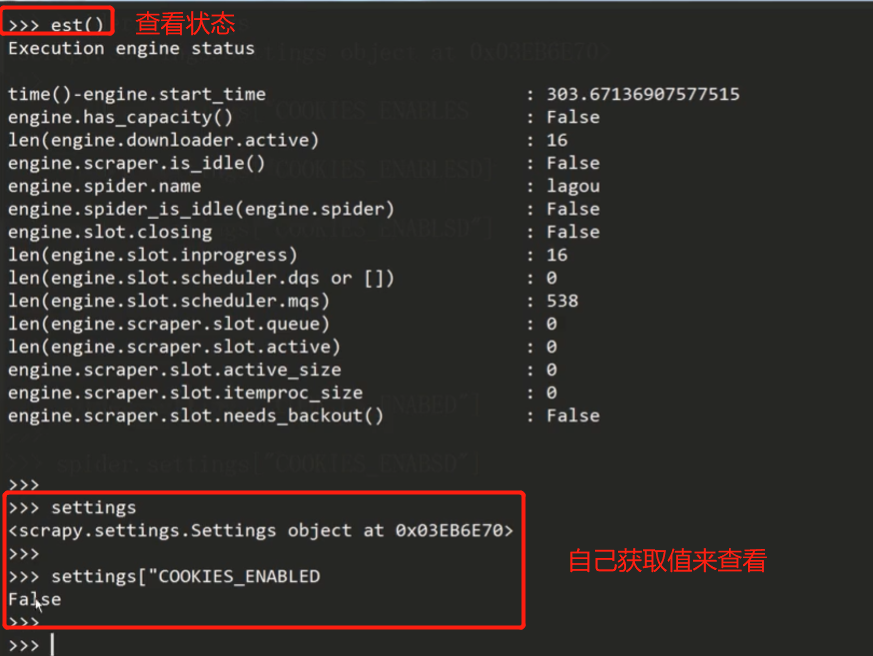
telnet相关的源码: 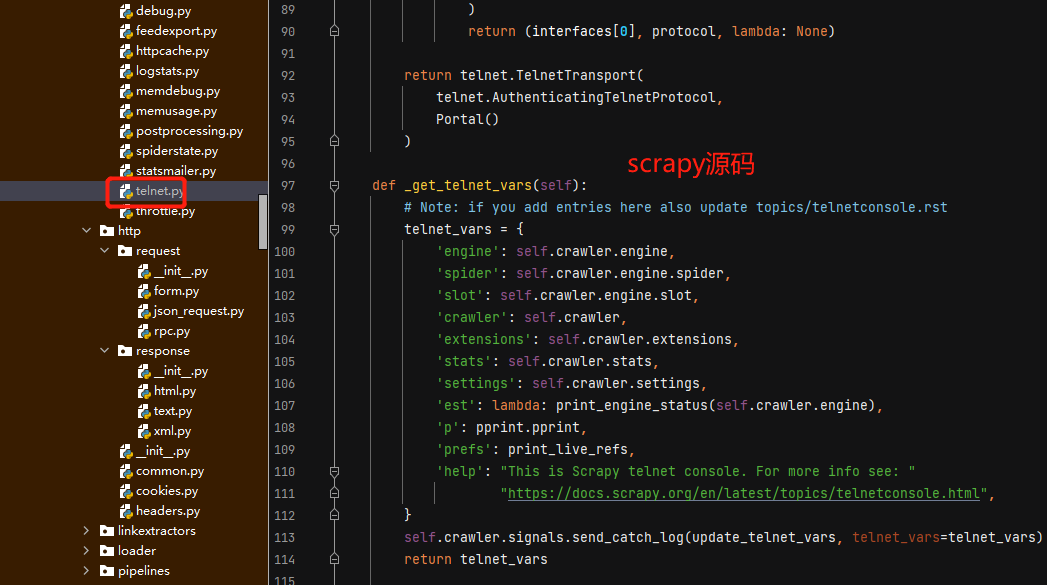
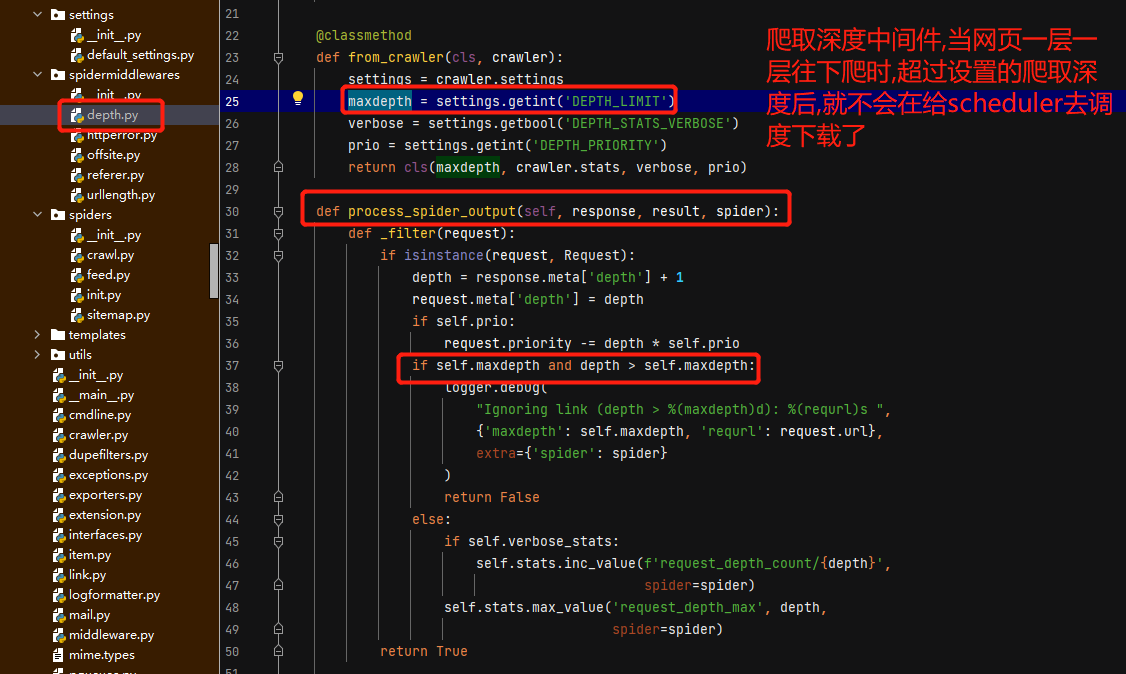
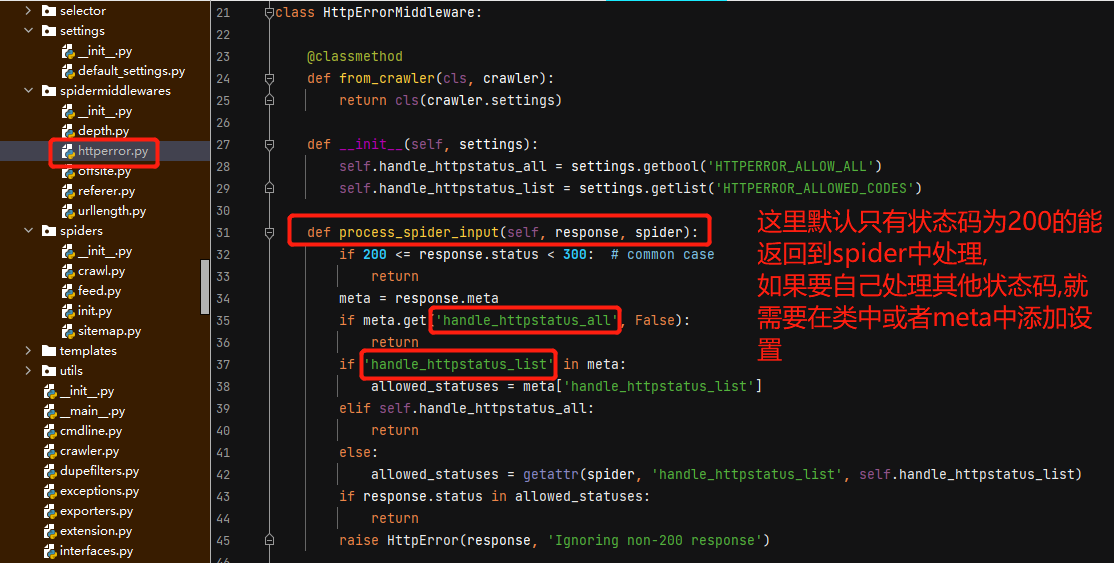
scrapy项目创建之初,自动生成的middlewares.py文件中,可以写自己的spider中间件.
def process_spider_input(self, response, spider):下载完的response,经由scheduler给spider时,会执行
def process_spider_output(self, response, result, spider):spider yield出request给scheduler时,会执行
这里介绍几个scrapy原码中的spider中间件
 scrapy数据收集
scrapy数据收集
stats.set_value('数据名称', 数据值) #设置数据 stats.inc_value('数据名称') #增加数据值,自增1 stats.max_value('数据名称', value) #当新的值比原来的值大时设置数据 stats.min_value('数据名称', value) #当新的值比原来的值小时设置数据 stats.get_value('数据名称') #获取数据值 stats.get_stats() #获取所有数据
应用举例:统计站点404的个数
class PachSpider(scrapy.Spider): #定义爬虫类,必须继承scrapy.Spider name = 'pach' #设置爬虫名称 allowed_domains = ['www.dict.cn'] #爬取域名 def start_requests(self): #起始url函数,会替换start_urls return [Request(
url='http://www.dict.cn/9999998888',
callback=self.parse
)]
# 利用数据收集器,收集所有404的url以及,404页面数量 handle_httpstatus_list = [404] # 设置不过滤404,见上一小节爬虫中间件的分析 def __init__(self): self.fail_urls = [] # 创建一个变量来储存404URL def parse(self, response): # 回调函数 if response.status == 404: # 判断返回状态码如果是404 self.fail_urls.append(response.url) # 将URL追加到列表 self.crawler.stats.inc_value('failed_url') # 设置一个数据收集,值为自增,每执行一次自增1 print(self.fail_urls) # 打印404URL列表 print(self.crawler.stats.get_value('failed_url')) # 打印数据收集值 else:
title = response.css('title::text').extract()
print(title)
相应的视频教程在这里 https://mp.weixin.qq.com/s/DG-T965Y9yKLwNYPus2cXA
本文由 mdnice 多平台发布

