selenium爬取京东懒加载的商品信息
1.页面分析
- 1.页面分析
- 2.滑动滚动条获取完整页面源码
- 3.解析源码获取标签内容
- 4.保存信息至数据库
- 5.运行结果
首先给出要爬取数据的url: 京东
进入页面后,显示在界面上的图片已经加载完成,但是没有显示在屏幕上的内容,是没有加载的,只有当我们拖动界面,才会对相应资源进行请求和加载,我们如果用requests模块直接去请求获取页面源码数据,获取的源码肯定不完整。
这时就可以用selenium模拟浏览器的操作,通过拖动界面模拟人浏览,使浏览器资源加载完成后,再去获取页面源码,此时获取的内容就相对完整了。
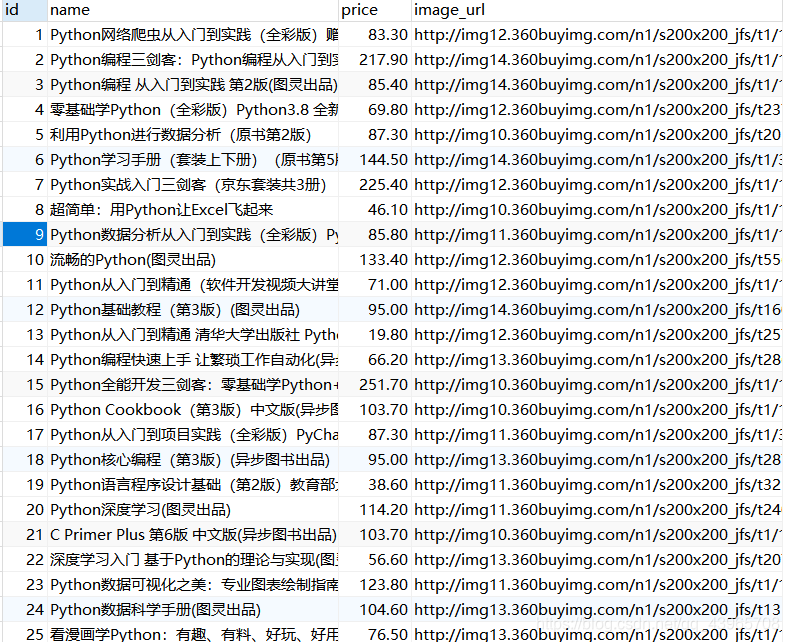
本次爬取内容是300条商品信息,书籍名称、价格、图片下载链接,获取后将其保存到mysql数据库中。
先选取滑动滚动条的参照标签,执行JS代码,滑动滚动条到此标签位置,这里为了图片能够完全加载,将整个页面分为6部分,拖动六次后再获取页面源码。 代码如下:
def get_page_text(url): driver.get(url) sleep(random.random()*3) for i in range(10, 61, 10): sleep(1) target = driver.find_element_by_xpath(f'//*[@id="J_goodsList"]/ul/li[{i}]') driver.execute_script("arguments[0].scrollIntoView();", target) sleep(random.random()) page_text = driver.page_source return page_text
3.解析源码获取标签内容
现在已经得到了加载完成后的页面数据,此时根据浏览器自带的工具,定位到图片列表具体的位置,大致如下。
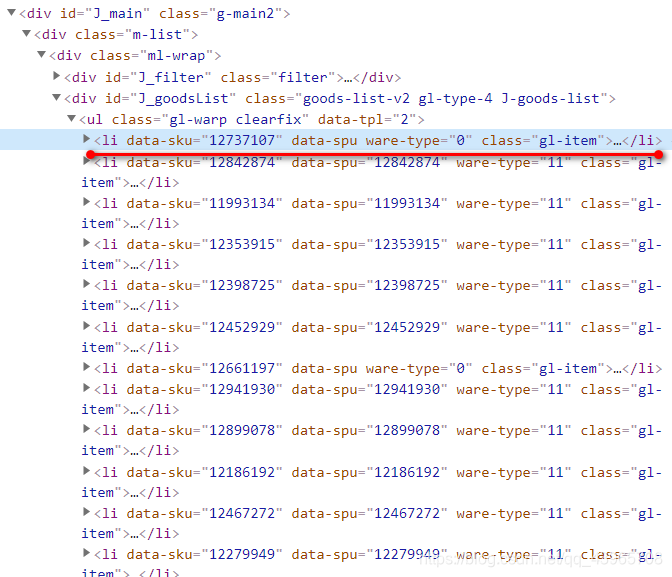 将获取的li标签保存到列表中,再在li标签中定位书籍名称、价格、图片地址。
将获取的li标签保存到列表中,再在li标签中定位书籍名称、价格、图片地址。
书籍名称:
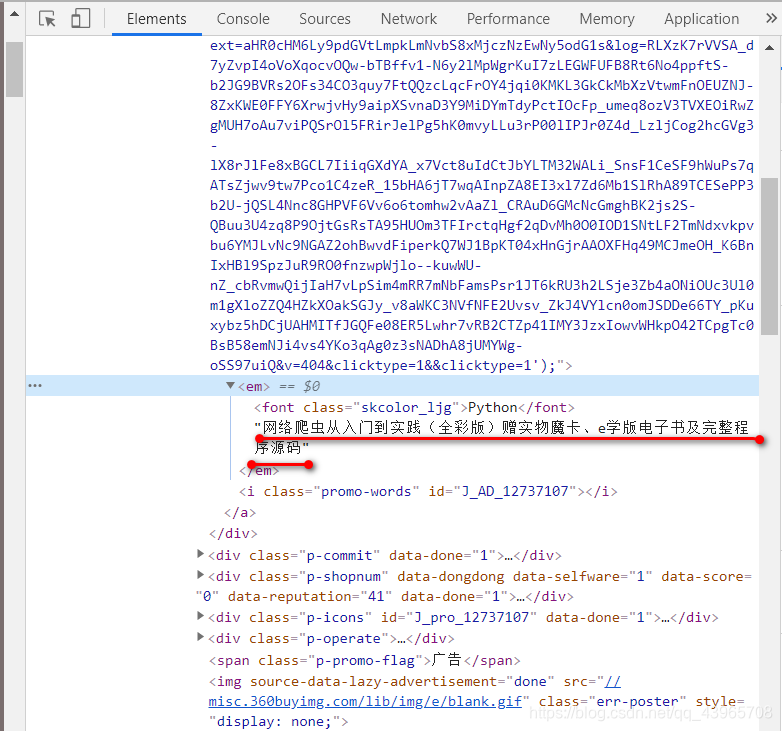 书籍价格:
书籍价格:
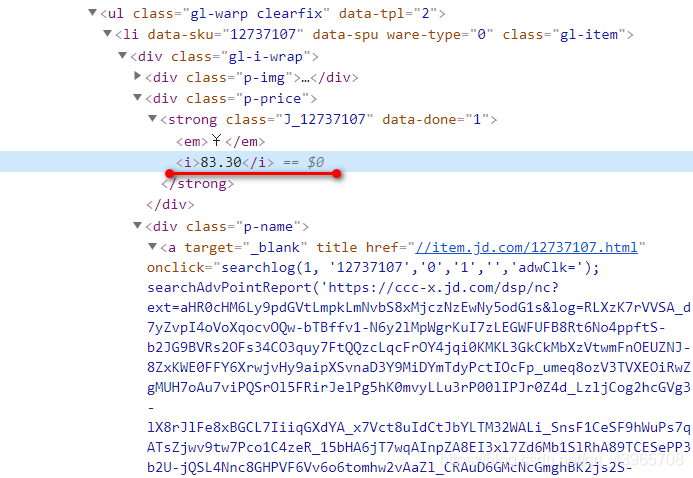 图片地址:
图片地址:
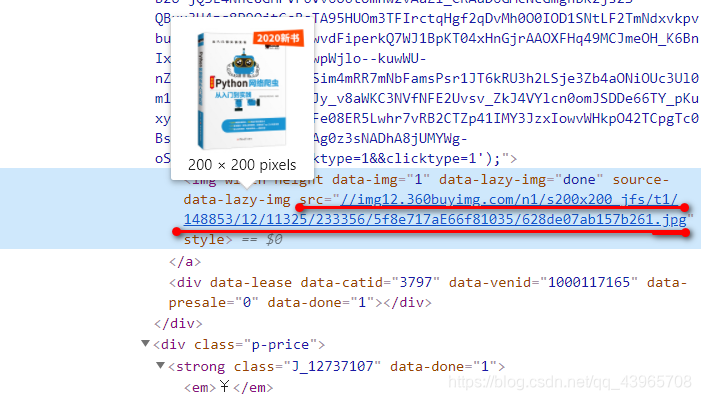 代码如下:
代码如下:
# 数据解析获取标签信息 def parse_page(page_text): tree = etree.HTML(page_text) li_list = tree.xpath('//*[@id="J_goodsList"]/ul/li') book_name_list = [] # 书籍名称 book_price_list = [] # 书籍价格 book_imageUrl_list = [] # 书籍图片 count = 0 for li in li_list: book_name_list.append(''.join(li.xpath('.//div[@class="p-name"]/a/em//text()'))) book_price_list .append(li.xpath('.//div[@class="p-price"]/strong/i/text()')[0]) # 由于网速的不稳定,可能有的图片没有加载完成,获取的数据可能为空 image_url = li.xpath('.//div[@class="p-img"]/a/img/@src') if len(image_url) == 0: # 若图片未加载出来,图片的url的值为img标签的data-lazy-img标签值 image_url = li.xpath('.//div[@class="p-img"]/a/img/@data-lazy-img') book_imageUrl_list.append('http:' + image_url[0]) return connectDB(book_name_list, book_price_list, book_imageUrl_list)
4.保存信息至数据库
代码如下:
# 连接数据库并保存 def connectDB(book_name_list, book_price_list, book_imageUrl_list): conn = pymysql.Connect(host = '127.0.0.1', port = 3306, user = 'root', password='password', db='books_jd', charset='utf8') # 创建游标对象 cursor = conn.cursor() for i in range(len(book_name_list)): sql = 'INSERT INTO books(name, price, image_url) VALUES ("{0}","{1}","{2}")'.format(book_name_list[i], book_price_list[i], book_imageUrl_list[i]) try: cursor.execute(sql) conn.commit() # 事务提交 except Exception as e: print(e) conn.rollback() # 事务回滚 conn.close() cursor.close()
主函数代码:
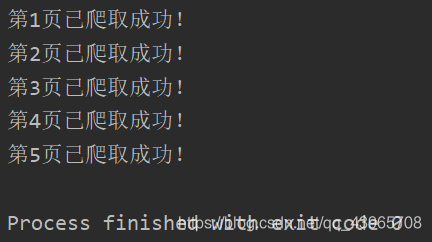
if __name__ == '__main__': j = [1, 57, 117, 176, 236] for i in range(1,10,2): url = 'https://search.jd.com/Search?keyword=python&wq=python&page={0}&s={1}&click=0'.format(i,j[(i-1)//2]) page_text = get_page_text(url) parse_page(page_text) sleep(random.random()*4) print('第{}页已爬取成功!'.format((i+1)//2)) # 退出并清除浏览器缓存 driver.quit()
5.运行结果