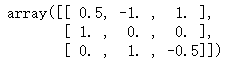通过本文的学习你将了解到为什么要进行标准化,以及标准化的常用方法。
为什么需要标准化数据集标准化是许多在scikit-learn中实现的机器学习估计器的共同要求;如果个体特征不是或多或少地像标准正态分布(零均值,单位标准差的正态分布),算法的表现可能会大打折扣。实际上,我们经常忽略数据的分布形状,而仅仅做零均值、单位标准差的处理。在一个机器学习算法的目标函数里的很多元素所有特征都近似零均值,方差具有相同的阶。如果某个特征的方差的数量级大于其它的特征,那么,这个特征可能在目标函数中占主导地位,这使得模型不能从其它特征有效地学习。
- 原理:基于原始数据的
mean(均值)和standard deviation(标准差)进行数据的标准化。将特征的原始值x使用Z-score标准化为x’。数据按其特征(按列进行)-mean,然后÷方差。最后得到的结果对每个特征/每列来说所有数据都聚集在0附近,方差值为1。 - 适用范围:特征的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。
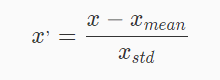
from sklearn import preprocessing
import numpy as np
X_train = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
X_scaled = preprocessing.scale(X_train)
X_scaled

X_scaled.mean(axis=0)
# array([0., 0., 0.])
X_scaled.std(axis=0)
array([ 1., 1., 1.])
- 原理:对原始数据进行线性变换。设特征
A的最小值和最大值为minA、maxA,将A的一个原始值x通过min-max标准化映射成在区间[0,1]中的值x’。 - 适用范围:特征的最大值最小值已知的情况
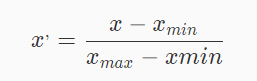
from sklearn import preprocessing
import numpy as np
X_train = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
min_max_scaler = preprocessing.MinMaxScaler()
X_train_minmax = min_max_scaler.fit_transform(X_train)
X_train_minmax
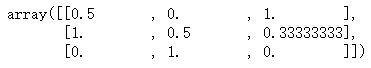
- 原理:通过除以每个特征的最大值将训练数据特征缩放至
[-1, 1]范围内,这就意味着,训练数据应该是已经零中心化或者是稀疏数据。 - 使用范围:特征最大值已知。
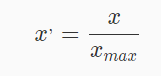
from sklearn import preprocessing
import numpy as np
X_train = np.array([[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]])
max_abs_scaler = preprocessing.MaxAbsScaler()
X_train_maxabs = max_abs_scaler.fit_transform(X_train)
X_train_maxabs