什么是Trie(字典)树
顾名思义,这棵树和字典类似,通过百度我们又能知道Trie树是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
我们可以先看一张图来演示Trie树的结构:
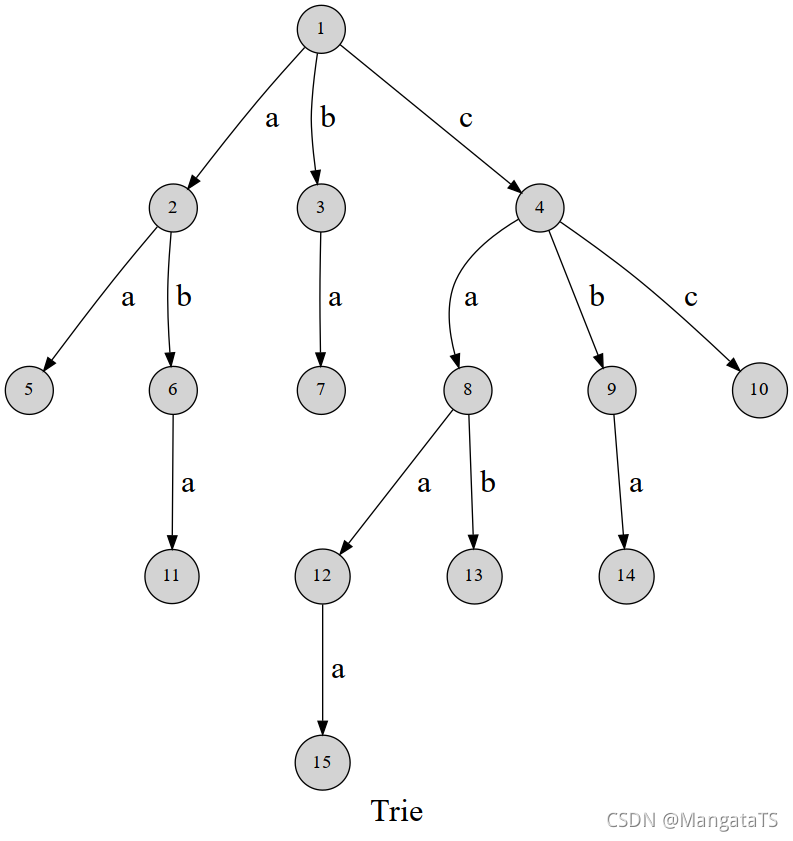
这张图已经很明显的告诉你了,这棵树的每一条边都代表着一个字符或者说除开根节点外其他点就是一个字符,我们通过这种方式就能实现类似字典的快速查找,但是显而易见的这样的结构对空间的浪费是巨大的
Trie树的基本性质1,根节点不包含字符,除根节点意外每个节点只包含一个字符。
2,从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串。
3,每个节点的所有子节点包含的字符串不相同。
Trie树的优缺点 优点1.很明显,Trie树在插入字符串和查找字符串的效率是极高的
2.Trie树本身就是一颗排好序的树
3.Trie树在对与字符串匹配方面能有更多的操作
4.不会发生像hash一样的hash碰撞
缺点1.很明显,Trie树是一种以时间换空间的做法,所以Trie树的空间花费非常大
2.对于较长字符串的处理,Trie树还不能解决,或者说会让Trie树的链变得很长导致炸空间等现象
为什么要学习Trie树1.因为题目需要,很多题目都会出现对字符串的处理等等
2.学习Trie树能丰富我们的数据结构知识
3.Trie树能给我们提供一种很好的思维方式
4.Trie树是后续学习其他数据结构例如AC自动机、后缀自动机的辅助结构
Trie树的应用 1.字符串的快速匹配通过Trie树我们可以实现O(m)复杂度的匹配
2.字符串排序我们通过优先遍历字符序靠前的字符串即可获得
3.最长公共前缀的匹配字典树会在插入字符串的时候统计每一个字符串的每一个字符的信息,通过这些信息我们就能知道当前匹配位置是否有公共前缀
代码实现例题luoguP2580
#include
#include
#include
using namespace std;
const int N = 5e5+10;//请注意这里的数组大小要开字符串的个数*字符串的长度这么大
int n,m;
struct trie {
int nextt[N][26],cnt;//nextt[i][j]存储的是第i个字符下一个字符j的位置信息
int exit[N];//exit[i]表示以值为i结束的这个字符串是否存在
void insert(char *s,int l) {
int p = 0;//这个表示的是当前的位置指针
for(int i = 0;i = 0; --i) {
ll c = (k>>i) & 1;
if(nextt[p][c^1]) p = nextt[p][c^1];
else p = nextt[p][c];
}
return exit[p];
}
}T;
int main()
{
int t;
scanf("%d",&t);
for(int j = 1;j
关注
打赏


