
- 选择题10道*2分=20分
- 填空题5道*2分=10分
- 判断题5道*1分=5分
- 简答题2道*10分=20分
- 方案设计题1道*15分=15分
(无唯一标准答案,可用中文写清楚每个关键步骤和重要技术点,也可直接写代码,或者中文和代码混合说明)
注意: ①写清方案实行的步骤 ②每个步骤的重要技术点,比如用的哪个类来实现
- 程序设计题6段*5分=30分(从挖行改成挖段)
- 复习hive的JSON和多字节分隔符的解析步骤和关键技术点
- 复习hive窗口函数的使用方法和含义
- 分布式是指通过网络连接的多个组件,通过交换信息协作而形成的系统。
- 集群是指同一种组件的多个实例,形成的逻辑上的整体
- Hadoop的框架最核心的设计就是:HDFS和MapReduce。
- HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算
HDFS:分布式文件系统 Yarn:资源调度系统 MapReduce:分布式运算程序开发框架 HIVE:SQL数据仓库工具 HBASE:基于Hadoop的分布式海量数据库 Zookeeper:分布式协调服务基础组件
Hadoop集群:⭐⭐NameNode它是hadoop中的主服务器,管理文件系统名称空间和对集群中存储的文件的访问,保存有metadate。SecondaryNameNode它不是namenode的冗余守护进程,而是提供周期检查点和清理任务。帮助NN合并editslog,减少NN启动时间。DataNode它负责管理连接到节点的存储(一个集群中可以有多个节点)。每个存储数据的节点运行一个datanode守护进程。ResourceManager(JobTracker)是一个仲裁整个集群可用资源的主节点,帮助YARN系统管理其上的分布式应用NodeManager(TaskTracker)是运行在单个节点上的代理,它管理Hadoop集群中单个计算节点
Hadoop分布式文件系统
端口:9000端口是HDFS默认的端口号,提供文件系统的端口供client角色寻找namenode角色的端口号,是进程之间的调用50070端口是NameNode的WebUI默认端口
大文件存储、流式数据访问
不适合做:大量小文件存储、随机写入(不支持修改内容,但是支持追加内容)、低延迟读取
other- 应用程序采用WORM(write once read many)(一次写入,多次读取)的数据读写模型,文件仅支持追加,而不支持修改。
- HDFS易于运行不同的平台上
- block size允许修改,2.7.7版本默认大小是128M
-
分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题。
-
MapReduce由两个阶段组成:Map和Reduce,用户只需要实现
map()和reduce()两个函数,即可实现分布式计算
大规模数据集的离线批处理计算
不适合做:实时的交互式计算,要求快速响应,低延迟
Yarn⭐⭐ 简介:是Hadoop2.0中的资源管理系统,它是一个通用的资源管理模块,可为各类应用程序进行资源管理和调度
节点:ResourceManager节点负责集群资源统一管理和计算框架管理,主要包括调度与应用程序管理NodeManager节点是节点资源管理监控和容器管理
-
Hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。
-
hive数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供SQL查询功能,能将SQL语句转变成MapReduce任务来执行
- 对于Hive的String类型相当于数据库的varchar类型
- 该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符,理论上它可以存储2GB的字符数。
(1)任何整数类型都可以隐式地转换为一个范围更广的类型,如TINYINT可以转换成INT,INT可以转换成BIGINT。 (2)所有整数类型、FLOAT和STRING(数值型)类型都可以隐式地转换成DOUBLE。 (3)TINYINT、SMALLINT、INT都可以转换为FLOAT。 (4)BOOLEAN类型不可以转换为任何其它的类型
强制转换:⭐- 可以使用CAST操作显示进行数据类型转换
例如CAST(‘1’ AS INT)将把字符串’1’ 转换成整数1;
- 如果强制类型转换失败,如执行CAST(‘X’ AS INT),表达式返回空值 NULL
create database if not exists dbname;
show databases;
desc database extended dbname;
drop database if exists dbname;只能删除空的数据库
drop database if exists dbname cascade;可删除非空数据库
use database_name;
内部表、外部表、分桶表、分区表…
表复制:create table stu_copy like stu_external; stu_copy是内部表
select * from tablename
-- 修改表名。rename
alter table course_common
rename to course_common1;
-- 修改列名。change column
alter table course_common1
change column id cid int;
-- 修改字段类型。change column
alter table course_common1
change column cid cid string;
-- The following columns have types incompatible with the existing columns in their respective positions
-- 修改字段数据类型时,要满足数据类型转换的要求。如int可以转为string,但是string不能转为int
-- 增加字段。add columns
alter table course_common1
add columns (common string);
-- 删除字段:replace columns
-- 这里仅仅只是在元数据中删除了字段,并没有改动hdfs上的数据文件
alter table course_common1
replace columns(
id string, cname string, score int);
-- 删除表
drop table course_common1;
truncate table tablename [partition partition_spec];
-
Hive创建内部表时,会将数据移动到数据仓库指向的路径。
-
创建外部表时,仅记录数据所在的路径,不对数据的位置做任何改变,在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
-
这样外部表相对来说更加安全些,数据组织也更加灵活,方便共享源数据
-
如果数据已经存储在 HDFS 上了,然后需要使用 Hive 去进行分析,并且该份数据还有可能要使用其他的计算引擎做计算之用,请使用外部表
-
如果一份数据仅仅只是使用 Hive 做统计分析,那么可以使用内部表
- 静态分区需要手动指定分区名,而动态分区是根据查询语句自动生成分区名
- 静态分区中的某个分区有可能一条数据都没有,而动态分区的每一个分区都至少包含一条数据
- 动态分区比静态分区消耗更多性能
从本地导入:
load data local inpath ‘/home/1.txt’ (overwrite)into table student;
从Hdfs导入:
load data inpath ‘/user/hive/warehouse/1.txt’ (overwrite)into table student;
查询导入:
create table student1 as select * from student;(也可以具体查询某项数据)
查询结果导入:
insert (overwrite)into table staff select * from track_log;
用insert overwrite导出方式导出到本地或者HDFS中
insert overwrite [local] directory path select_statement
暂不列举
自定义函数: 分类:UDF(User-Defined-Function)一进一出UDAF(User- Defined Aggregation Funcation)聚集函数,多进一出UDTF(User-Defined Table-Generating Functions)一进多出
get_json_object(string json_string, string path)函数的定义与使用
-
返回值:string
-
参数1:要解析的json的字符串
-
参数2:$(json字符串的最外层).(map的key)[]( 数组的元素,下标从0开始)* (所有)
eg:
{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}
取第一列movie的值:$.movie
[{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}]
取第一列movie的值:$[0].movie
[[{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}]]
取第二列rate的值:$[0][0].rate
hive默认序列化类是LazySimpleSerDe,其只支持单字节分隔符来加载文本数据。
参考博客
注:over才是窗口函数,下面这些函数只是与之搭配的分析函数
ROW_NUMBER()函数作用就是将select查询到的数据进行排序,每一条数据加一个序号,他不能用做于学生成绩的排名,一般多用于分页查询rank():生成数据项在分组中的排名,排名相等会在名次中留下空位。dense_rank():生成数据项在分组中的排名,排名相等会在名次中不会留下空位
分析函数 over(partition by 列名 order by 列名 rows between 开始位置 and 结束位置)
例子:
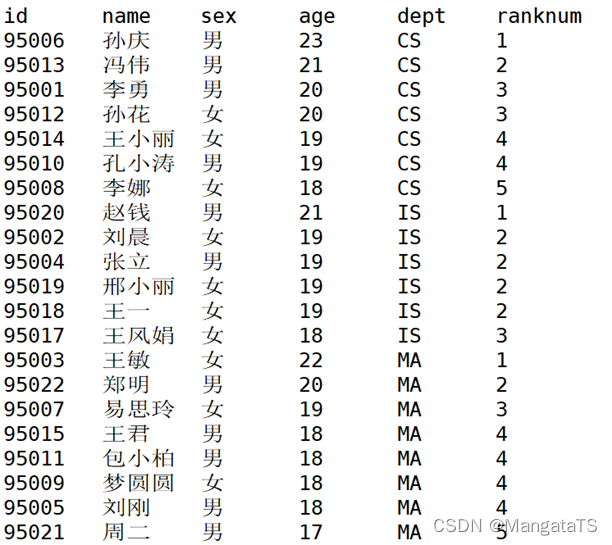
row_number() + overselect id,name,sex,age,dept,row_number() over(partition by dept order by age desc) index from suttest;
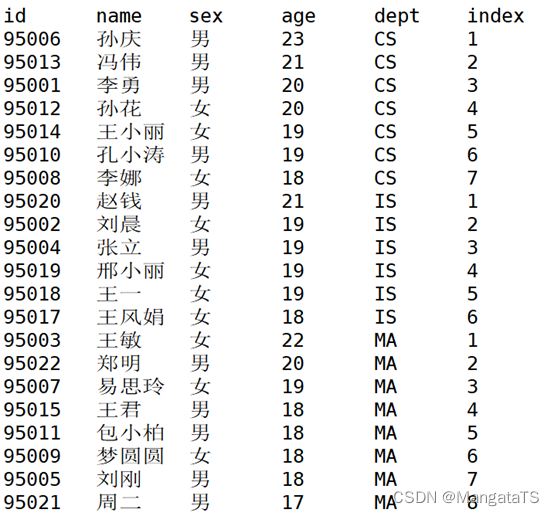
select id,name,sex,age,dept,rank() over(partition by dept order by age desc) ranknum from suttest;
生成数据项在分组中的排名,排名相等会在名次中留下空位
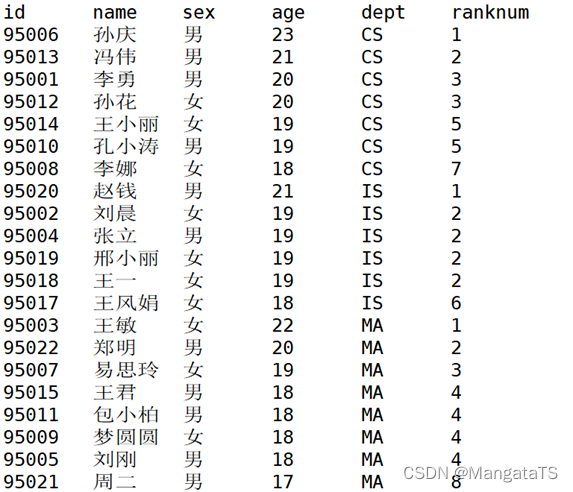
select id,name,sex,age,dept,dense_rank() over(partition by dept order by age desc) ranknum from suttest;
生成数据项在分组中的排名,排名相等会在名次中不会留下空位
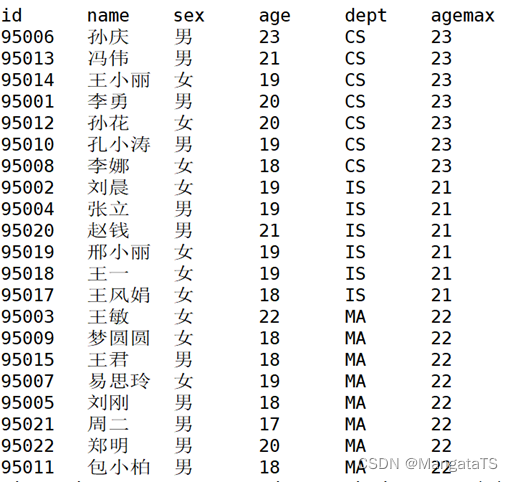
常用的聚合函数包括max 、 min、sum
结构和上面分析函数相同
eg: ① 求整个窗口内部年龄的最大值
select id,name,sex,age,dept,max(age) over(distribute by dept) agemax from suttest;
package com.xishiyou.mytest;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class HdfsMyTest {
public static void main(String[] args) {
try {
Configuration con = new Configuration();
// con.set("dfs.replication","1");
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.200.11:9000"), con, "root");
// 创建文件夹
// fileSystem.mkdirs(new Path("/aaa"));
// 创建文件
// fileSystem.createNewFile(new Path("/aaa/test2.txt"));
// 下载文件
// fileSystem.copyToLocalFile(false,
// new Path("/NOTICE.txt"),
// new Path("D:/NOTICE.txt"),
// true
// );
// 上传文件
// fileSystem.copyFromLocalFile(new Path("D:/b.jpg"),
// new Path("/aaa/b.jpg"));
// 追加内容到文件中
//WINDOWS本地---HDFS
//windows--input--内存--output--HDFS
BufferedInputStream in = new BufferedInputStream(new FileInputStream("D:/NOTICE.txt"));
FSDataOutputStream out = fileSystem.append(new Path("/aaa/test1.txt"));
IOUtils.copyBytes(in,out,4096);
fileSystem.close();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
}
}
HiveTest继承UDF
package com.java.hivetest;
import org.apache.hadoop.hive.ql.exec.UDF;
public class MyUdf extends UDF {
// 三个数相加
public double evaluate(double a,double b,double c){
return a+b+c;
}
// 两个数相乘
public double evaluate(double a,double b) {
return a*b;
}
}
package com.xishiyou.mytest01;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 前两个泛型LongWritable, Text代表输入Map程序中的Key-value
*后两个泛型Text,LongWritable代表输出Map程序中的Key-value--根据需求规定
* LongWritable→java中的long
* Text→java中的String
* 这些类型都是hadoop自已进行特殊序列化之后的类型,不能采用java的原生类型
*/
public class WordMapTest extends Mapper {
/**
*map方法执行一次,代表读取一行数据:转换成特定格式
* @param key 进入map方法的key值
* @param value 进入map方法的value值,表示每一行内容
* @param context 上下文 将处理之后的结果,输送到下一个环节
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
System.out.println(key.toString());
//将每一行数据以空格拆分
String[] words = value.toString().split(" ");
//遍历该数据,得到每行中的单词
for (String word:words) {
//按照特定的格式发送给reduce程序
context.write(new Text(word),new LongWritable(1));
}
}
}
package com.xishiyou.mytest01;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class WordReduceTest extends Reducer {
/**
*
* @param key mapreduce合并后传过来的key
* @param values 进mapreduce给我们进行了合并处理之后的数据key,[1,1,1,1,1,1,1]
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
long result=0L;
// 迭代values,将值相加即可得到总数
for (LongWritable lw:values) {
result+=lw.get();
}
// 迭代相加完成后输出
context.write(key,new LongWritable(result));
}
}
package com.mrqianru.mr1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WordJob {
public static void main(String[] args) {
try {
Configuration con = new Configuration();
con.set("fs.defaultFS","hdfs://192.168.200.11:9000");
con.set("dfs.replication","1");
Job job = Job.getInstance(con);
// 为job程序取名字
job.setJobName("单词统计测试");
// 主类的class对象
job.setJarByClass(WordJob.class);
// 关联的mapper类
job.setMapperClass(WordMap.class);
// 关联的reduce类
job.setReducerClass(WordReduce.class);
// 告诉job程序,mapper类的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 告诉job程序,reduce类的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// job.setNumReduceTasks(2);
// 为job设置输入源---hdfs
FileInputFormat.addInputPath(job,new Path("/word.txt"));
Path path = new Path("/word_result");
FileSystem fileSystem = FileSystem.get(con);
if (fileSystem.exists(path)){
fileSystem.delete(path,true);
}
// 为job设置输出源--hdfs
FileOutputFormat.setOutputPath(job,path);
// 启动job
// true表示将运行进度等信息及时输出给用户,false的话只是等待作业结束
boolean flag = job.waitForCompletion(true);
if (flag){
System.out.println("执行完成");
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
package com.xishiyou.mytest02;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class OrderMap extends Mapper {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 按照tab键拆分
String[] orders = value.toString().split("\t");
// 设置orderWritable
OrderWritable ow = new OrderWritable();
ow.setPrice(Double.parseDouble(orders[1]));
ow.setNum(Integer.parseInt(orders[2]));
ow.setTotalPrice(Double.parseDouble(orders[3]));
// 输出
context.write(new Text(orders[0]),ow);
}
}
package com.xishiyou.mytest02;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class OrderReduce extends Reducer {
@Override
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
for (OrderWritable ow:values) {
// 设置价格*2,得出总价
ow.setPrice(ow.getPrice()*2);
ow.setTotalPrice(ow.getPrice()*ow.getNum());
// 输出
context.write(key,ow);
}
}
}
package com.xishiyou.mytest02;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//自定义类型
public class OrderWritable implements Writable {
// 单价
private double price;
// 数量
private int num;
// 销售额
private double totalPrice;
//提供getter和setter方法
public double getPrice() {
return price;
}
public void setPrice(double price) {
this.price = price;
}
public int getNum() {
return num;
}
public void setNum(int num) {
this.num = num;
}
public double getTotalPrice() {
return totalPrice;
}
public void setTotalPrice(double totalPrice) {
this.totalPrice = totalPrice;
}
// 重写toString方法
@Override
public String toString() {
return price + "\t" + num + "\t" + totalPrice ;
}
// 以下两个方法里面的顺序要与定义时一致
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeDouble(price);
dataOutput.writeInt(num);
dataOutput.writeDouble(totalPrice);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
price = dataInput.readDouble();
num=dataInput.readInt();
totalPrice=dataInput.readDouble();
}
}
package com.xishiyou.mytest02;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class OrderJob {
public static void main(String[] args) {
try {
// 设置参数
Configuration config = new Configuration();
config.set("fs.defaultFS","hdfs://192.168.200.11:9000");
config.set("dfs.repliaction","1");
// 获取job对象
Job job = Job.getInstance(config, "订单案例");
// 获取三个类
job.setJarByClass(OrderJob.class);
job.setMapperClass(OrderMap.class);
job.setReducerClass(OrderReduce.class);
// 设置map和reduce的输出
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(OrderWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(OrderWritable.class);
// 设置输入源
FileInputFormat.addInputPath(job,new Path("/order.txt"));
// 设置输出目的地
Path outPath=new Path("/order_result");
FileSystem fileSystem = FileSystem.get(config);
if (fileSystem.exists(outPath)){
fileSystem.delete(outPath,true);
}
FileOutputFormat.setOutputPath(job,outPath);
// 启动
boolean b = job.waitForCompletion(true);
if (b){
System.out.println("执行成功");
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
}
注释可以不用管
Ⅰ、HDFSpublic static void main(String[] args) {
try {
Configuration con = new Configuration();
// con.set("dfs.replication","1");
FileSystem fileSystem = FileSystem.get(new URI("hdfs://192.168.200.11:9000"), con, "root");
// 创建文件夹
// fileSystem.mkdirs(new Path("/aaa"));
// 创建文件
// fileSystem.createNewFile(new Path("/aaa/test2.txt"));
// 下载文件
// fileSystem.copyToLocalFile(false,
// new Path("/NOTICE.txt"),
// new Path("D:/NOTICE.txt"),
// true
// );
// 上传文件
// fileSystem.copyFromLocalFile(new Path("D:/b.jpg"),
// new Path("/aaa/b.jpg"));
// 追加内容到文件中
//WINDOWS本地---HDFS
//windows--input--内存--output--HDFS
BufferedInputStream in = new BufferedInputStream(new FileInputStream("D:/NOTICE.txt"));
FSDataOutputStream out = fileSystem.append(new Path("/aaa/test1.txt"));
IOUtils.copyBytes(in,out,4096);
fileSystem.close();
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
}
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
System.out.println(key.toString());
//将每一行数据以空格拆分
String[] words = value.toString().split(" ");
//遍历该数据,得到每行中的单词
for (String word:words) {
//按照特定的格式发送给reduce程序
context.write(new Text(word),new LongWritable(1));
}
}
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
long result=0L;
// 迭代values,将值相加即可得到总数
for (LongWritable lw:values) {
result+=lw.get();
}
// 迭代相加完成后输出
context.write(key,new LongWritable(result));
}
public static void main(String[] args) {
try {
Configuration con = new Configuration();
con.set("fs.defaultFS","hdfs://192.168.200.11:9000");
con.set("dfs.replication","1");
Job job = Job.getInstance(con);
// 为job程序取名字
job.setJobName("单词统计测试");
// 主类的class对象
job.setJarByClass(WordJob.class);
// 关联的mapper类
job.setMapperClass(WordMap.class);
// 关联的reduce类
job.setReducerClass(WordReduce.class);
// 告诉job程序,mapper类的输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
// 告诉job程序,reduce类的输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
// job.setNumReduceTasks(2);
// 为job设置输入源---hdfs
FileInputFormat.addInputPath(job,new Path("/word.txt"));
Path path = new Path("/word_result");
FileSystem fileSystem = FileSystem.get(con);
if (fileSystem.exists(path)){
fileSystem.delete(path,true);
}
// 为job设置输出源--hdfs
FileOutputFormat.setOutputPath(job,path);
// 启动job
// true表示将运行进度等信息及时输出给用户,false的话只是等待作业结束
boolean flag = job.waitForCompletion(true);
if (flag){
System.out.println("执行完成");
}
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ClassNotFoundException e) {
e.printStackTrace();
}
}
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] orders = value.toString().split("\t");
OrderWritable ow = new OrderWritable();
ow.setPrice(Double.parseDouble(orders[1]));
ow.setNum(Integer.parseInt(orders[2]));
ow.setTotalPrice(Double.parseDouble(orders[3]));
context.write(new Text(orders[0]),ow);
}
protected void reduce(Text key, Iterable values, Context context) throws IOException, InterruptedException {
for (OrderWritable ow:values) {
ow.setPrice(ow.getPrice()*2);
ow.setTotalPrice(ow.getPrice()*ow.getNum());
context.write(key,ow);
}
}
// 重写toString方法
@Override
public String toString() {
return price + "\t" + num + "\t" + totalPrice ;
}
// 以下两个方法里面的顺序要与定义时一致
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeDouble(price);
dataOutput.writeInt(num);
dataOutput.writeDouble(totalPrice);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
price = dataInput.readDouble();
num=dataInput.readInt();
totalPrice=dataInput.readDouble();
}
方案设计题就是,比如说给你一堆比较复杂的需要处理的数据,要你存到hdfs上,然后查询出某种想要的结果。答题可以用中文回答或者写代码写hql都可以,比如存到hdfs上时,第一步要干嘛,第二步干嘛,大概写出每一步有可能涉及的技术关键字就行。
大数据代码题主要看方法的具体实现和重点类名就行,方法声明,环境配置之类的不需要看,方案设计题没有唯一答案,也没有固定的作答方式,只需要写好每个重点步骤和步骤大概用到什么知识点就行,也可以直接写代码
将数据存到HDFS的步骤⭐⭐⭐- ①加载配置项,创建
Configuration对象并初始化参数 - ②通过
FileSystem创建文件系统实例 - ③通过
Path创建文件实例 - ④创建**
FSDataOutputStream的输出流对象** - ⑤通过
os.write函数写入数据 - ⑥通过
close()函数关闭输出流和文件系统
代码实现:
try{
//加载配置项
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://localhost:9000");
conf.set("fs.hdfs.impl", "org.apache.hadoop.hdfs.DistributedFileSystem");
//创建文件系统实例
FileSystem fs = FileSystem.get(conf);
//创建文件实例
String fileName = "test";
Path file = new Path(fileName);
//创建输出流对象
FSDataOutputStream os = fs.create(file);
//写入数据
byte[] buff = "Hello World".getBytes();
os.write(buff, 0, buff.length);
System.out.println("Create:"+fileName);
//关闭输出流和文件系统
os.close();
fs.close();
} catch (Exception e){
e.printStackTrace();
}
- 我们先在hive上面创建一个新的表
- 然后将数据拷贝到HDFS上面 eg:
hadoop fs -put test.txt /data/test - 然后使用
select或者其他查询语句筛选我们想要的结果

