
将单链表中终端结点的指针端由空指针改为指向头结点,就使整个单链表形成一个环,这种头尾相接的单链表称为单链表,简称循环链表(circular linked list)。和单向链表一样,循环链表不一定必须有头结点,但是带有头结点循环链表使得空链表和非空链表的处理一致。 
这种情况下,访问第一个元素需要用 O ( 1 ) O(1) O(1)时间,而要访问最后一个元素则需要 O ( n ) O(n) O(n)。带头结点的循环链表后继指针指向头结点。
双向链表单向链表、循环链表有一个问题。当我们访问一个元素时间复杂度为
O
(
1
)
O(1)
O(1),下一次再次访问的时间就是
O
(
n
)
O(n)
O(n),为了解决这个问题就发明了双向链表。  如果是一个空的双向链表,其头结点的前后指针都指向同一个头结点。
如果是一个空的双向链表,其头结点的前后指针都指向同一个头结点。
双向链表(double linked list)是在单链表的每个结点中,在设置一个指向其前驱结点的指针域。双向链表有两个指针域,一个指向前驱一个指向后继。其结构可以设计成:
typedef struct DulNode
{
int data;
struct DulNode * prev;
struct DulNode * next;
}DulNode,
typedef DulNode * pDuLinkList;
双向链表有以下等式:
p->next->prev=p=p->prior->next;
双向链表使得反向遍历变得容易,但是也带了存储空间和操作上的复杂。比如说插入操作: 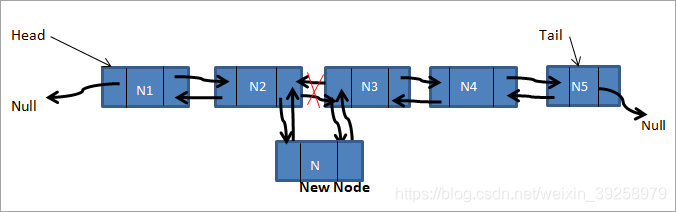 假设p指向N2节点,那么p->next则指向N3,s指向N待插入的节点。
假设p指向N2节点,那么p->next则指向N3,s指向N待插入的节点。
s->next=p->next;
s->prev=p->next->prev;
p->next=s;
p->next->prev=s;
注意先把原结点的信息给到新结点在进行处理。 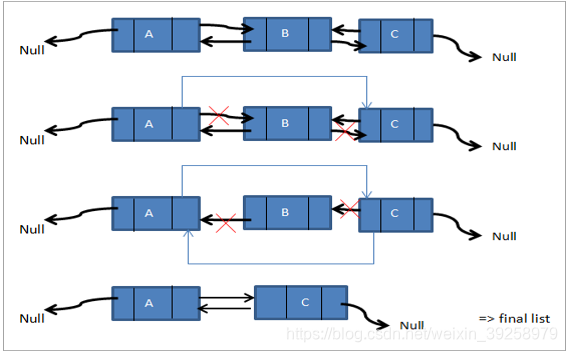 假设p指向B待删除节点,那么p->next则指向C,p->prev指向A。
假设p指向B待删除节点,那么p->next则指向C,p->prev指向A。
p->prev->next=p->next;
p->next->prev=p->prev;
free(p);

