
- 前言
- 等式约束优化
- 等式约束的几何解释
- 不等式约束优化
- 多约束优化
- KKT条件
- 代码示例
LM算法的置信域方法中,通过在优化函数后添加一个优化量约束来提升迭代过程中的稳定性。
拉格朗日乘子法(Lagrange Multiplier Method)是非线性优化中的常用方法,置信域约束实际上就是拉格朗日乘子法的应用。
本篇将学习记录拉格朗日乘子法的原理和使用。
注意:之所以是初探,是因为我还没有总结过凸优化的基础内容,现在不会深入研究拉格朗日乘子法需要满足的限定条件。
等式约束优化对于优化函数 f : R n → R f:{\bf R}^n \to {\bf R} f:Rn→R,求 f f f在某个可行域 x ∈ R n {\bf x}\in {\bf R^n} x∈Rn下的极值点。如果可行域通过等式 g ( x ) = 0 g{\bf (x)}=0 g(x)=0表达,则记为: min x f ( x ) s . t . g ( x ) = 0 \min_{\bf x} f({\bf x}) \\ s.t. \quad g({\bf x})=0 xminf(x)s.t.g(x)=0 假设 f ( x ) , g ( x ) f({\bf x}),g({\bf x}) f(x),g(x)都连续可导,则定义拉格朗日函数,获得极值条件: L ( x , λ ) = f ( x ) + λ g ( x ) min x , λ L ( x , λ ) = min x , λ ( f ( x ) + λ g ( x ) ) → { ∇ x L ( x , λ ) = ∇ x f ( x ) + λ ∇ x g ( x ) = 0 ∇ λ L ( x , λ ) = g ( x ) = 0 L({\bf x,\lambda})=f({\bf x})+\lambda g({\bf x}) \\ \quad \\ \min_{\bf x,\lambda} L({\bf x},\lambda)=\min_{\bf x,\lambda} (f({\bf x})+\lambda g({\bf x})) \\ \quad \\ \to \begin{cases} \nabla_{\bf x} L({\bf x}, \lambda)=\nabla_{\bf x} f({\bf x})+\lambda\nabla_{\bf x}g({\bf x})=0 \\ \nabla_{\lambda} L({\bf x}, \lambda)= g({\bf x})=0 \\ \end{cases} L(x,λ)=f(x)+λg(x)x,λminL(x,λ)=x,λmin(f(x)+λg(x))→{∇xL(x,λ)=∇xf(x)+λ∇xg(x)=0∇λL(x,λ)=g(x)=0 于是,等式约束优化就变成了无约束优化问题。
不过,拉格朗日函数的构造有一些突兀,这里给出一个几何解释。
等式约束的几何解释下图是求极大值的例子,蓝色虚线表示优化函数
f
(
x
,
y
)
f(x,y)
f(x,y),
f
(
x
,
y
)
=
d
1
,
d
2
,
…
f(x,y)=d_1,d_2,\dots
f(x,y)=d1,d2,…表示该函数的一个个等高线,
d
1
>
d
2
>
d
3
d_1>d_2>d_3
d1>d2>d3,蓝色小箭头表示该处的梯度;红色线表示约束方程
g
(
x
,
y
)
=
c
g(x,y)=c
g(x,y)=c,红色小箭头表示该处的梯度。需要注意,该图像是从三维空间投影到xy平面上的结果。 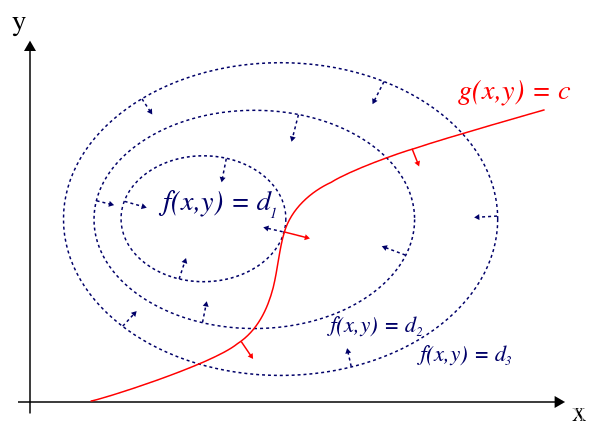 等式约束条件下,
x
,
y
x,y
x,y的值只能在红线上取。优化函数的极值必然会在蓝线与红线相切的切点获得,这是因为:蓝色梯度是优化函数增长最快的方向,如果极值点是切点附近的点,那么向切点运动,函数值仍然会增加,这就不符合极大值点的定义了。求极小值的情况也同理。
等式约束条件下,
x
,
y
x,y
x,y的值只能在红线上取。优化函数的极值必然会在蓝线与红线相切的切点获得,这是因为:蓝色梯度是优化函数增长最快的方向,如果极值点是切点附近的点,那么向切点运动,函数值仍然会增加,这就不符合极大值点的定义了。求极小值的情况也同理。
给出切点处是极小值点的数学形式,即: ∇ x , y f ( x , y ) = − λ ∇ x , y g ( x , y ) g ( x , y ) = 0 \nabla_{x,y} f(x,y)=-\lambda \nabla_{x,y} g(x,y) \\ g(x,y) = 0 ∇x,yf(x,y)=−λ∇x,yg(x,y)g(x,y)=0 第一个式子表示两个函数 f , g f,g f,g处的梯度平行(说 f , g f,g f,g相切并不严谨,因为图示只是在xy平面上的函数投影),第二个式子表示约束条件决定的可行域。
不等式约束优化优化函数不变,约束条件变成了不等式
g
(
x
)
≤
0
g({\bf x})\le 0
g(x)≤0,则可行域从曲线变成了一个曲面,如下图所示,灰色部分代表可行域。 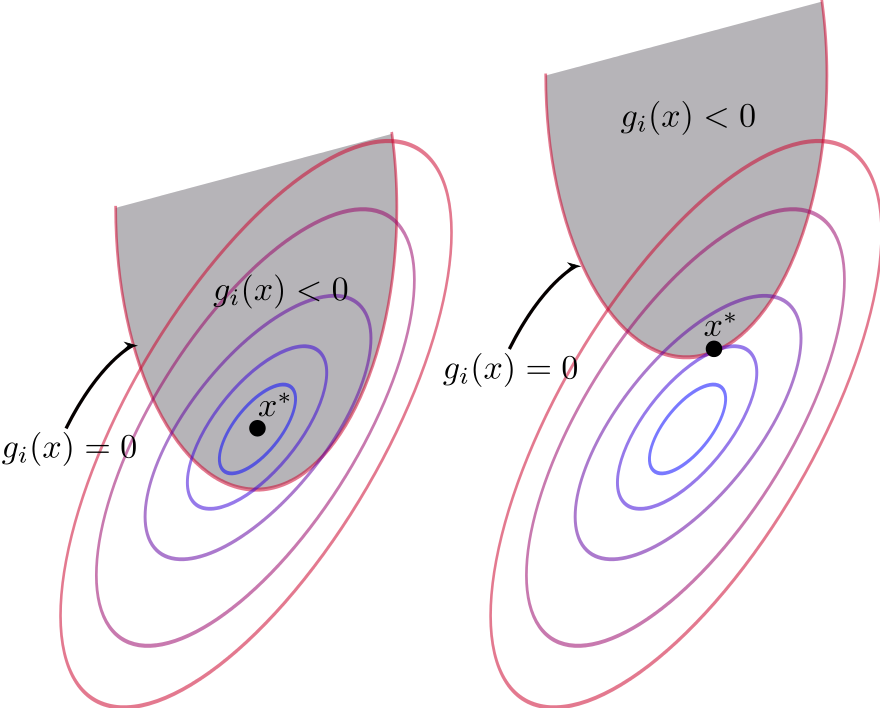 此时需要考虑两种情况。
此时需要考虑两种情况。
第一种情况如图左,如果极值点落在可行域边界内,即 g ( x ) < 0 g({\bf x})0)。这就限定了 λ ≥ 0 \lambda \ge 0 λ≥0。 λ = 0 \lambda=0 λ=0意味着可行域边界通过了 ∇ x f ( x ) = 0 \nabla_{{\bf x}}f({\bf x})=0 ∇xf(x)=0的位置。
将两种情况综合考虑,获得不等式约束优化的KKT(Karush-Kuhn-Tucker)条件: ∇ x L ( x , λ ) = ∇ x f ( x ) + λ ∇ x g ( x ) = 0 g ( x ) ≤ 0 λ ≥ 0 λ g ( x ) = 0 \nabla_{\bf x} L({\bf x}, \lambda) = \nabla_{\bf x}f({\bf x})+\lambda \nabla_{\bf x}g({\bf x}) = {\bf 0} \\ g({\bf x}) \le 0 \\ \lambda \ge 0 \\ \lambda g({\bf x}) = 0 ∇xL(x,λ)=∇xf(x)+λ∇xg(x)=0g(x)≤0λ≥0λg(x)=0
多约束优化上面的等式与不等式约束可以共同推广到多个约束的优化情况: L ( x , λ ) = f ( x ) + ∑ i = 1 m λ i g i ( x ) + ∑ j = 1 n μ j h j ( x ) s . t . g i ( x ) ≤ 0 , h j ( x ) = 0 L({\bf x},\lambda)=f({\bf x})+\sum_{i=1}^m \lambda_i g_i({\bf x}) + \sum_{j=1}^n \mu_j h_j({\bf x}) \\ \quad \\ s.t. \quad g_i{(\bf x)} \le 0,\quad h_j({\bf x}) = 0 \\ L(x,λ)=f(x)+i=1∑mλigi(x)+j=1∑nμjhj(x)s.t.gi(x)≤0,hj(x)=0
其KKT条件为: ∇ x L ( x , λ ) = ∇ x f ( x ) + ∑ i = 1 m λ i ∇ g i ( x ) + ∑ j = 1 n μ j ∇ h j ( x ) = 0 g i ( x ) ≤ 0 h j ( x ) = 0 λ i ≥ 0 λ i g i ( x ) = 0 \nabla_{\bf x} L({\bf x}, \lambda) = \nabla_{\bf x} f({\bf x})+\sum_{i=1}^m \lambda_i \nabla g_i({\bf x}) + \sum_{j=1}^n \mu_j \nabla h_j({\bf x}) = 0 \\ \quad \\ \quad g_i{(\bf x)} \le 0 \\ \quad h_j({\bf x}) = 0 \\ \lambda_i \ge 0 \\ \lambda_i g_i({\bf x}) = 0 ∇xL(x,λ)=∇xf(x)+i=1∑mλi∇gi(x)+j=1∑nμj∇hj(x)=0gi(x)≤0hj(x)=0λi≥0λigi(x)=0
KKT条件上面给出的KKT条件,实际上是约束优化问题有解时满足的必要条件。也就是说,非极值也可能满足KKT条件。因此,只有满足某些正则条件时,KKT条件才能正确使用,比如最常用的线性无关条件LICQ:
对于极值点落在边界上的不等式约束条件在极值点处的梯度与等式约束在极值点处的梯度线性无关时。
由于这一部分涉及很多凸优化内容,因此等我学习到凸优化时,再来深入探究KKT条件。
代码示例这里给出一个基于python sympy的等式约束拉格朗日乘子法示例。由于sympy不能单独完成不等式约束,需要添加其它模块,以后会补充不等式约束代码。
import numpy as np
import math
import scipy
import sympy
def solve_lagarange(F, G=0, H=0):
x, y, l, u = sympy.symbols('x, y, l, u')
L = F + l * G + u * H
px, py, pl, pu = sympy.derive_by_array(L, [x, y, l, u])
res = sympy.solve([px, py, pl, pu], x, y, l, u)
print(res)
def eq_limit_solve():
a, b = sympy.symbols('x, y')
optim_function = non_linear_func_2(a, b)
eq_limit_function = limite_func_1(a, b)
solve_lagarange(optim_function, 0, eq_limit_function)
def non_linear_func(x, y):
fxy = 0.5 * (x ** 2 + y ** 2)
return fxy
def non_linear_func_2(x, y):
fxy = x*x + 2*y*y + 2*x*y + 3*x - y - 2
return fxy
def non_linear_func_3(x, y):
fxy = 0.5 * (x ** 2 - y ** 2)
return fxy
def non_linear_func_4(x, y):
fxy = x**4 + 2*y**4 + 3*x**2*y**2 + 4*x*y**2 + x*y + x + 2*y + 0.5
return fxy
def limite_func_1(x, y):
fxy = 2 * x + y - 5
return fxy
def limite_func_2(x, y):
fxy = x**2 + y**2 - 9
return fxy
if __name__ == '__main__':
a, b = sympy.symbols('x, y')
eq_limit_solve()

