
- 前言
- 拟牛顿条件
- 几何解释
- DFP算法
- BFGS算法
- Broyden类算法
- 代码示例
- 后记
无论是牛顿法,高斯牛顿法,还是LM算法,都需要计算海森矩阵或其近似,然后求海森矩阵的逆,来获得迭代增量,因此存在迭代不收敛问题(海森矩阵的正定性),并且计算效率较低。
拟牛顿法更进一步,将海森矩阵也作为一个迭代估计量,因而避免了海森矩阵的求逆运算,并提升了迭代稳定性。
拟牛顿条件仍然是从优化函数的泰勒展开讲起: f ( x ) = f ( x k ) + ∇ f ( x k ) T ( x − x k ) + 1 2 ( x − x k ) T H ( x k ) ( x − x k ) ∇ f ( x ) T = ∇ f ( x k ) T + H ( x k ) ( x − x k ) f({\bf x})=f({\bf x_k})+\nabla f({\bf x_k})^T({\bf x - x_k}) + \frac{1}{2}({\bf x - x_k})^T H({\bf x_k})({\bf x - x_k}) \\ \nabla f ({\bf x})^T = \nabla f({\bf x_k})^T + H({\bf x_k})({\bf x-x_k}) f(x)=f(xk)+∇f(xk)T(x−xk)+21(x−xk)TH(xk)(x−xk)∇f(x)T=∇f(xk)T+H(xk)(x−xk) 简写为: J ( x ) − J ( x k ) = H ( x k ) ( x − x k ) J({\bf x}) - J({\bf x_k}) = H({\bf x_k})({\bf x-x_k}) J(x)−J(xk)=H(xk)(x−xk) 假设我们通过 J ( x ) = 0 J(\bf x)=0 J(x)=0求出了本次迭代增量 Δ x \Delta \bf x Δx,现在将 x = x k + 1 = x k + Δ x {\bf x=x_{k+1}=x_k}+\Delta {\bf x} x=xk+1=xk+Δx代入: J ( x k + 1 ) − J ( x k ) = H ( x k ) ( x k + 1 − x k ) ( 1 − 1 ) J({\bf x_{k+1}})-J({\bf x_k}) = H({\bf x_{k}}) ({\bf x_{k+1} - x_k}) \quad (1-1) J(xk+1)−J(xk)=H(xk)(xk+1−xk)(1−1) 如果我们要通过迭代 G k + 1 G_{k+1} Gk+1近似 H ( x k ) − 1 H({x_k})^{-1} H(xk)−1,那么 G k G_k Gk也要满足以上方程。这就是拟牛顿条件: G k + 1 ( J k + 1 − J k ) = ( x k + 1 − x k ) s e t J k + 1 − J k = y k , ( x k + 1 − x k ) = s k t h e n G k + 1 y k = s k ( 2 ) a n d y k = G k + 1 − 1 s k ( 3 ) G_{k+1}(J_{k+1}-J_{k})=({\bf x_{k+1} - x_k}) \\ set \quad J_{k+1}-J_{k}=y_k,({\bf x_{k+1} - x_k})=s_k \\ \quad \\ then \quad G_{k+1}y_k=s_k \quad (2) \\ and \quad y_k = G_{k+1}^{-1}s_k \quad (3) \\ Gk+1(Jk+1−Jk)=(xk+1−xk)setJk+1−Jk=yk,(xk+1−xk)=skthenGk+1yk=sk(2)andyk=Gk+1−1sk(3) 注意:用 x k + 1 , J k + 1 {\bf x_{k+1}},J_{k+1} xk+1,Jk+1迭代 G k + 1 G_{k+1} Gk+1似乎只能近似第 k k k次迭代的海森矩阵 H ( x k ) H(\bf x_k) H(xk)。不过实际上,如果把式(1-1)改写为以下形式: J ( x k − 1 ) − J ( x k ) = H ( x k ) ( x k − 1 − x k ) ( 1 − 2 ) → J ( x k ) − J ( x k − 1 ) = H ( x k ) ( x k − x k − 1 ) → J ( x k + 1 ) − J ( x k ) = H ( x k + 1 ) ( x k + 1 − x k ) J({\bf x_{k-1}})-J({\bf x_k}) = H({\bf x_{k}}) ({\bf x_{k-1} - x_k}) \quad (1-2) \\ \to J({\bf x_{k}})-J({\bf x_{k-1}}) = H({\bf x_{k}}) ({\bf x_{k} - x_{k-1}}) \\ \to J({\bf x_{k+1}})-J({\bf x_{k}}) = H({\bf x_{k+1}}) ({\bf x_{k+1} - x_{k}}) \\ J(xk−1)−J(xk)=H(xk)(xk−1−xk)(1−2)→J(xk)−J(xk−1)=H(xk)(xk−xk−1)→J(xk+1)−J(xk)=H(xk+1)(xk+1−xk) 这样, G k + 1 G_{k+1} Gk+1就是 H ( x k + 1 ) H(\bf x_{k+1}) H(xk+1)的近似了。
几何解释用一元函数来理解更简单,如下图,黑色线是优化函数的一阶导,
A
,
B
A,B
A,B点是
x
k
,
x
k
+
1
x_k,x_{k+1}
xk,xk+1,拟牛顿法的思想就是通过红色割线
A
B
AB
AB的斜率来近似
B
B
B点的二阶导(也就是B点的切线,绿线);另一方面,红色切线对于
A
A
A点的切线也能近似,这就是式(1-1),(1-2)的几何意义。 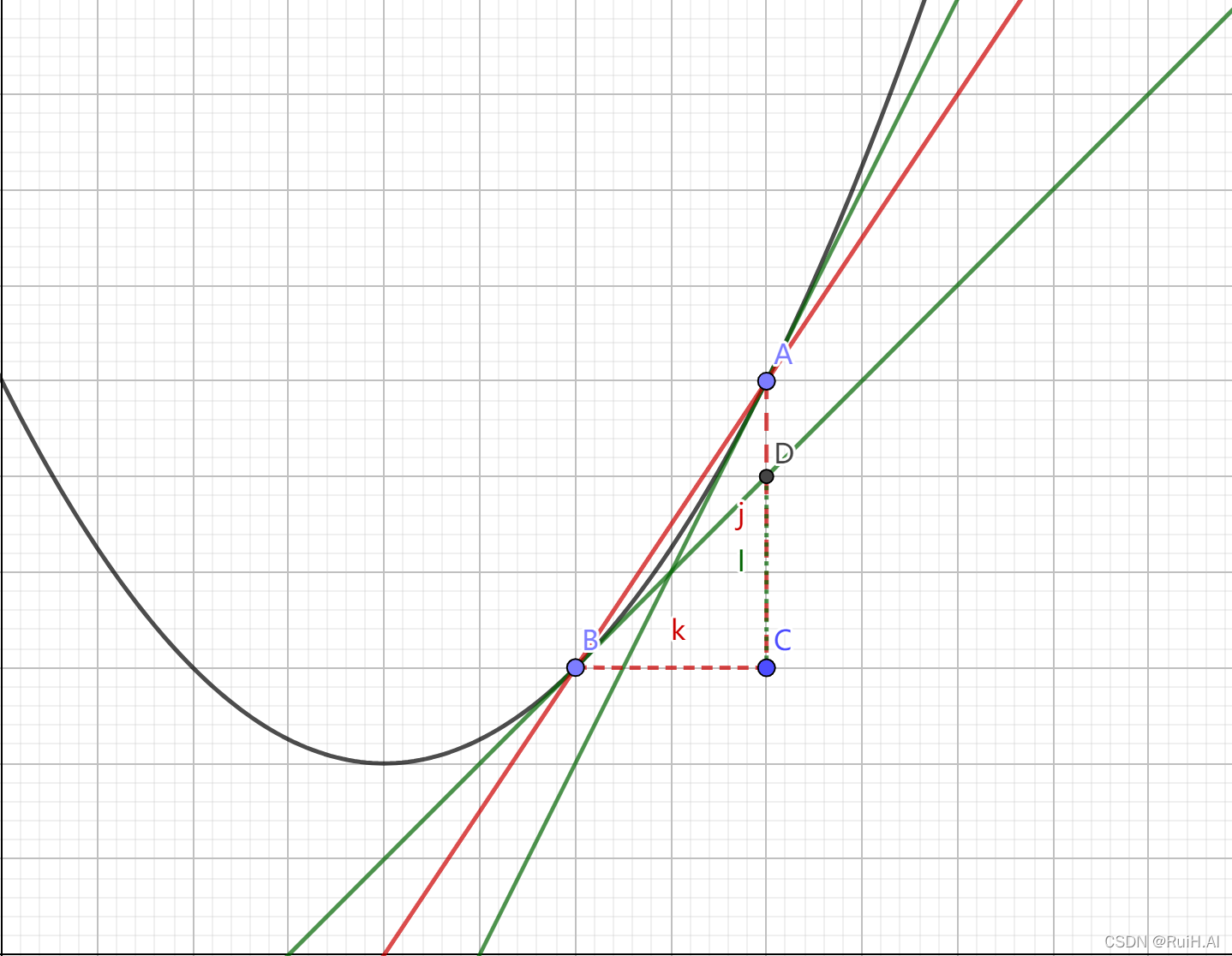
DFP算法(DFP是人名)通过迭代构造 G k G_{k} Gk来近似 H k − 1 H_{k}^{-1} Hk−1。DFP公式推导如下: G k + 1 = G k + P k + Q k G k + 1 y k = s k → G k y k + P k y k + Q k y k = s k s e t P k y k = s k , Q k y k = − G k y k t h e n P k = s k s k T s k T y k , Q k = − G k y k y k T G k y k T G k y k G k + 1 = G k + s k s k T s k T y k − G k y k y k T G k y k T G k y k G_{k+1}=G_k+P_k+Q_k \\ G_{k+1}y_k=s_k \to G_{k}y_k+P_ky_k+Q_ky_k=s_k \\ \quad \\ set \quad P_ky_k=s_k,\quad Q_ky_k=-G_ky_k \\ \quad \\ then \quad P_k= \frac{s_ks_k^T}{s_k^Ty_k},\quad Q_k=-\frac {G_ky_ky_k^TG_k}{y_k^TG_ky_k} \\ \quad \\ G_{k+1} = G_k+ \frac{s_ks_k^T}{s_k^Ty_k} - \frac {G_ky_ky_k^TG_k}{y_k^TG_ky_k} \\ Gk+1=Gk+Pk+QkGk+1yk=sk→Gkyk+Pkyk+Qkyk=sksetPkyk=sk,Qkyk=−GkykthenPk=skTykskskT,Qk=−ykTGkykGkykykTGkGk+1=Gk+skTykskskT−ykTGkykGkykykTGk
DFP算法中,当初始 G G G正定时,迭代中的每个 G G G都是正定的。
BFGS算法BFGS算法(BFGS是四位作者的首字母)通过构造 B k B_k Bk来近似 H k H_k Hk,推导方式与DFP算法相似: B k + 1 = B k + P k + Q k B k + 1 s k = y k → B k s k + P k s k + Q k s k = y k s e t P k s k = y k , Q k s k = − B k s k t h e n P k = y k y k T y k T s k , Q k = − B k s k s k T B k s k T B k s k B k + 1 = B k + y k y k T y k T s k − B k s k s k T B k s k T B k s k B_{k+1}=B_k+P_k+Q_k \\ B_{k+1}s_k=y_k \to B_{k}s_k+P_ks_k+Q_ks_k=y_k \\ \quad \\ set \quad P_ks_k=y_k,\quad Q_ks_k=-B_ks_k \\ \quad \\ then \quad P_k= \frac{ y_k y_k^T}{ y_k^Ts_k},\quad Q_k=-\frac {B_ks_ks_k^TB_k}{s_k^TB_ks_k} \\ \quad \\ B_{k+1} = B_k+ \frac{ y_k y_k^T}{ y_k^Ts_k} - \frac {B_ks_ks_k^TB_k}{s_k^TB_ks_k} \\ Bk+1=Bk+Pk+QkBk+1sk=yk→Bksk+Pksk+Qksk=yksetPksk=yk,Qksk=−BkskthenPk=ykTskykykT,Qk=−skTBkskBkskskTBkBk+1=Bk+ykTskykykT−skTBkskBkskskTBk BFGS算法中,当初始 B B B正定时,迭代中的每个 B B B都是正定的。
注意:由于原BFGS算法没有直接近似海森矩阵的逆,因此可以进一步应用Sherman-Morrison-Woodbury公式直接从 B k − 1 B_k^{-1} Bk−1得到 B k + 1 − 1 B_{k+1}^{-1} Bk+1−1。由于这个公式我还不大熟,因此这里给出结果,以后有时间再记录推导细节: B k + 1 − 1 = ( I − s k y k T y k T s k ) B k − 1 ( I − y k s k T y k T s k ) + s k s k T y k T s k B_{k+1}^{-1} = (I - \frac{s_ky_k^T}{y_k^Ts_k})B_k^{-1}(I-\frac{y_ks_k^T}{y^T_ks_k}) + \frac{s_ks_k^T}{y_k^Ts_k} Bk+1−1=(I−ykTskskykT)Bk−1(I−ykTskykskT)+ykTskskskT
Broyden类算法上面的DFP和BFGS都能得到 H k − 1 H_k^{-1} Hk−1的迭代近似 G k − D F P , G k − B F G S G_{k-DFP},G_{k-BFGS} Gk−DFP,Gk−BFGS,那么DFP和BFGS迭代的线性组合也满足拟牛顿条件,并且迭代保持正定: G k = λ G k − D F P + ( 1 − λ ) G k − B F G S , 0 ≤ λ ≤ 1 G_{k}=\lambda G_{k-DFP}+(1-\lambda)G_{k-BFGS},\quad 0\le\lambda\le 1 Gk=λGk−DFP+(1−λ)Gk−BFGS,0≤λ≤1 这被称为Broyden类算法。
代码示例下面是我写的通过拟牛顿法DFP求二元函数极小值的python代码:
import numpy as np
import scipy.optimize
import time
import math
def partial_derivate_xy(x, y, F):
dx = (F(x + 0.001, y) - F(x, y))/0.001
dy = (F(x, y + 0.001) - F(x, y))/0.001
return dx, dy
def partial_partial_derivate_xy(x, y, F):
dx, dy = partial_derivate_xy(x, y, F)
dxx = (partial_derivate_xy(x + 0.001, y, F)[0] - dx) / 0.001
dyy = (partial_derivate_xy(x, y + 0.001, F)[1] - dy) / 0.001
dxy = (partial_derivate_xy(x, y + 0.001, F)[0] - dx) / 0.001
dyx = (partial_derivate_xy(x + 0.001, y, F)[1] - dy) / 0.001
return dxx, dyy, dxy, dyx
def non_linear_func(x, y):
fxy = 0.5 * (x ** 2 + y ** 2)
return fxy
def non_linear_func_2(x, y):
fxy = x*x + 2*y*y + 2*x*y + 3*x - y - 2
return fxy
def non_linear_func_3(x, y):
fxy = 0.5 * (x ** 2 - y ** 2)
return fxy
def non_linear_func_4(x, y):
fxy = x**4 + 2*y**4 + 3*x**2*y**2 + 4*x*y**2 + x*y + x + 2*y + 0.5
return fxy
def non_linear_func_5(x, y):
fxy = math.pow(math.exp(x) + math.exp(0.5 * y) + x, 2)
return fxy
def quasi_newton_optim(x, y, F, G, lr=0.1):
dx, dy = partial_derivate_xy(x, y, F)
grad = np.array([[dx], [dy]])
vec_delta = - lr * np.matmul(G, grad)
vec_opt = np.array([[x], [y]]) + vec_delta
x_opt = vec_opt[0][0]
y_opt = vec_opt[1][0]
dxx, dyy = partial_derivate_xy(x_opt, y_opt, F)
grad_delta = np.array([[dxx - dx], [dyy - dy]])
G_update = G + np.matmul(vec_delta, vec_delta.T)/np.dot(vec_delta.T, grad_delta) \
- np.matmul(np.matmul(np.matmul(G, grad_delta), grad_delta.T), G) / np.matmul(np.matmul(grad_delta.T, G), grad_delta)
return x_opt, y_opt, grad, G_update
def quasi_newton_optim_correct(x, y, F, G):
dx, dy = partial_derivate_xy(x, y, F)
grad = np.array([[dx], [dy]])
vec_delta = - np.matmul(G, grad)
vec_opt = np.array([[x], [y]]) + vec_delta
x_opt = vec_opt[0][0]
y_opt = vec_opt[1][0]
dxx, dyy = partial_derivate_xy(x_opt, y_opt, F)
grad_delta = np.array([[dxx - dx], [dyy - dy]])
Gy = np.matmul(G, grad_delta)
yG = np.matmul(grad_delta.T, G)
yGy = np.matmul(np.matmul(grad_delta.T, G), grad_delta)
G_update = G + np.matmul(vec_delta, vec_delta.T)/np.dot(vec_delta.T, grad_delta) \
- np.matmul(Gy, yG) / yGy
return x_opt, y_opt, grad, G_update
def optimizer(x0, y0, F, th=0.01):
x = x0
y = y0
G = np.eye(2)
counter = 0
while True:
x_opt, y_opt, grad, G = quasi_newton_optim(x, y, F, G)
if np.linalg.norm(grad)
关注
打赏
最近更新
- 深拷贝和浅拷贝的区别(重点)
- 【Vue】走进Vue框架世界
- 【云服务器】项目部署—搭建网站—vue电商后台管理系统
- 【React介绍】 一文带你深入React
- 【React】React组件实例的三大属性之state,props,refs(你学废了吗)
- 【脚手架VueCLI】从零开始,创建一个VUE项目
- 【React】深入理解React组件生命周期----图文详解(含代码)
- 【React】DOM的Diffing算法是什么?以及DOM中key的作用----经典面试题
- 【React】1_使用React脚手架创建项目步骤--------详解(含项目结构说明)
- 【React】2_如何使用react脚手架写一个简单的页面?

