
目录
论文基本情况
什么是语义分割?
什么是RefineNet?
问题引入
贡献是什么?
Related work
整体架构如何?
(1)残差卷积模块 RCU
(2)多分辨率融合模块 MRF
(3)链式残差池化模块 CRP
输出卷积层 Output Conv
RefineNet网络中的恒等映射 Identity Mapping
实验结果如何?
(1)对象分析任务
(2)语义分割
(3)消融实验 Ablation experiment
Cascade RefineNet网络的变种
总结
论文基本情况- 题目:RefineNet: Multi-Path Refinement Networks for High-Resolution Semantic Segmentation
-
作者:
- Guosheng Lin1∗ Anton Milan2 Chunhua Shen2,3 Ian Reid2,3
- 1Nanyang Technological University 2University of Adelaide 3Australian Centre for Robotic Vision
- 出处:2017-CVPR
-
开源代码:
- https://github.com/guosheng/refinenet
- https://github.com/DrSleep/refinenet-pytorch
- 论文地址:https://arxiv.org/abs/1611.06612
- 引用:Lin, G., Milan, A., Shen, C., & Reid, I. (2017). Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 1925-1934).
按照文献中的介绍,语义分割目的是给图像中每个像素分配唯一的标签(或者类别)。例子如下:
左边图像为真实场景拍摄的图像,右边为逐像素类别标注的结果。行人、车辆、道路和数目等分别采用不同的颜色进行区分,但是并不区分同一类别的不同个体。
什么是RefineNet? 问题引入本方法主要想解决的限制是:多阶段的卷积池化会降低最后预测结果图片的尺寸,从而损失很多精细结构信息。(在RefineNet发表之时,部分语义分割方法由于采用卷积或者池化层,造成了图像分辨率的降低。)
现有方法的解决办法:
-
反卷积作为上采样的操作:
- 反卷积不能恢复低层的特征,毕竟已经丢失了。deeplab使用空洞卷积来解决这一问题。
-
但是空洞卷积有两个问题:
- 对高像素feature map的卷积会消耗算力,同时也需要大的GPU内存,通常对于高像素的图都会resize
- 空洞卷积的特性决定了它会损失一些细节信息。
-
Atrous Convolution (Deeplab提出的):
- 带孔卷积的提出就是为了生成高分辨率的feature map,但是计算代价和存储代价较高
-
利用中间层的特征:
- 最早的FCN-8S就是这样做的,但是始终还是缺少强的空间信息
作者主张所有层的特征都是有用的,高层特征有助于类别识别,低层特征有助于生成精细的边界。
为此,Lin等人提出了RefineNet,一种通用的多路级联精修结构的网络。RefineNet的显式的利用了下采样过程的所有信息,使用远程残差连接来实现高分辨率的预测(与FCN相比,它更充分利用了主干网不同层次分辨率的特征图里面的信息;与Deeplab的Dilated Convolution方法相比,它要求更少的内存)。此时,浅层的完善特征可以直接的用于强化高级的语义特征。
贡献是什么?- 提出了多路径网络,利用多级别的抽象用于高分辨率语义分割;
- 通过使用带残差连接的同态映射构建所有组件,梯度能够在短距离和长距离传播,从而实现端到端的训练;
- 提出了链式残差池化模块,从较大的图像区域俘获背景上下文。使用多个窗口尺寸获得有效的池化特征,并使用残差连接和学习到的权重融合到一起。
- 提到了FCN,segnet,deconvnet, unet, deeplab v2等
- 能够利用低维的feature来精炼高维的semantic feature.
- 使用了短范围和长范围的残余连接,实验表明,网络有效
-
分析ResNet
- 降采样增加了感受野
- 提高了训练效率
- 一般的最终会降采样到1/32,会损失信息,可选的解决方法是使用空洞卷积
-
deeplab v2
- 降采样操作全部被取消,在第1个block之后的卷积层全部使用空洞卷积。优点是在不增加参数的情况下增加了感受野。
- 文章说,空洞卷积很消耗内存,原因在于空洞卷积在较高分辨率上保留大量的feature map,在网络的后层通道数很多。
- 我的理解是因为少了下采样,feature map自然就会很大,
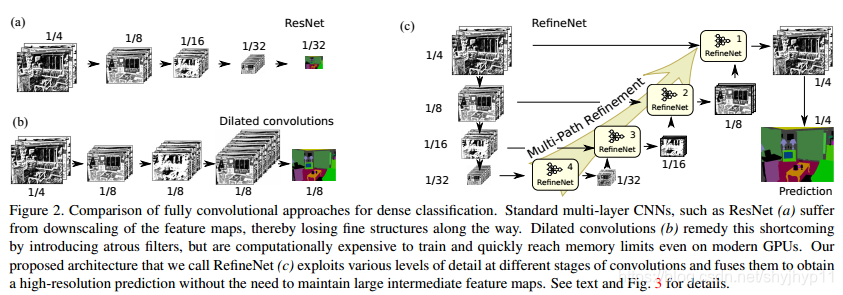
可以看见,整个结构其实是类似于FCN-8S的结构的,只是抽出特征更早,而且经过了RefineNet进行处理。 整个流程就是,1/32的feature map输入RefineNet处理后和1/16的feature map再一起又输入一个RefineNet优化,后面的过程类似。
上图基本上表示了RefineNet的思路起源和它比之前方法的优点。如左上角的a所示是一个基于ResNet的全卷积分割模型,但是它只是利用了最后一层的低分辨率的特征图,很多空间信息都在不断地卷积stride和pooling层中丢失了,很难恢复出高精度的Segmentation map;左下的b模型,是Deeplab利用Dilated Convolution的方法来做特征提取,Dilated Convolution优点在于可以在不增大计算量和参数量的情况下保持比较大的感受野,也可以保证网络中每层特征图的分辨率不至于太小,但是缺点也是很显然的,由于中间结果都是分辨率很大的特征图,那么训练和推理过程中都对内存/显存提出了很大的要求。
而右边表示的是RefineNet的示意图,**主干网络是ResNet**,但是在ResNet的4个不同分辨率阶段都会抽出来给一个RefineNet块做处理,而且也有identity mapping的连接,即丰富了不同分辨率的特征混合(和U-Net类似),也让大网络的训练更加容易。
另外值得注意的是,这个网络的**Cascade Multi-Path Refinement**。从ResNet出来的低分辨率特征,不断的结合上一个Stage的较高分辨率的特征,进行混合;而且这是一个级联(Cascade)的过程,从而不断不断地提升分割精度。

RefineNet结构是输入一个或者多个不同分辨率的特征图,进行混合和提升,输出一个较大特征图的块。它由三个级联的子块组成。 也可以看出,每个RefineNet的输入是可以调整的,所以整个网络的连接也是可以修改的,当然作者做实验说明在他提出的其他变体中这种连接的效果最好。
RefineNet共包含下面三个核心模块:
- 残差卷积模块RCU(Residual Conv Unit);
- 多分辨率融合模块 MRF(Multi-Resolution fusion);
- 链式残差池化模块 CRP(Chained Residual Pooling);
模块中包含激活(ReLU)和卷积(Conv3x3)操作,然后使用加法将前后的特征图融合,这在设计上ResNet思想相同。作用就是**fine-tune主干网ResNet的输出**使他更适应分割这个任务。
(2)多分辨率融合模块 MRF
将前面多种分辨率的特征图输入到融合模块内后,首先采用卷积层获得尺寸不变的特征图;然后使用上采样操作将所有特征图扩展为尺寸相同的新特征图;最后,使用Sum操作融合所有的特征图。
因为在RCU输出的特征图每个path的空间分辨率是不一样的,这个多分辨率融合块的作用就是把输入的各种**不同分辨率的特征提升并对齐**到最大的输入path的分辨率,然后将它们通过Sum操作融合起来。
(3)链式残差池化模块 CRP
此模块的目的是从大的背景区域中俘获上下文信息,多个池化窗口能获得有效的特征,并使用学习到的权重进行融合。
这个层的作用是通过pooling操作让不同的特征图有不同的感受野以便于**提取不同尺度的背景上下文**的信息。用不同的残差连接一个作用是便于训练,第二个作用是混合复用不同分辨率的特征。每个pooling层后面添加的卷积层的作用相当于在sum操作前学习一个**自适应的权重**。
输出卷积层 Output ConvRefineNet块最后的输出层其实就是一个前面介绍的Residual Conv Unit(这样每个RefineNet有三个RCN,两个在最前面,一个在最后,RCU进,RCU出)。这一层的作用就是给前面层输出的特征**增加一些非线性**。
RefineNet网络中的恒等映射 Identity Mapping受到ResNet的启发,在RefineNet的设计中,作者大量使用了Identity Maping这种结构。ResNet的shortcut连接形成一条干净的通道使信息的流通更加顺畅,而在主路上,添加了非线性来学习有效特征。这种结构使很深的网络也可以很好的训练出来。
在RefineNet中,有两种 Identity Mapping,Long-term的和Short-term的。在RefineNet块的RCU和CRP里面的是Short-term的,在各个RefineNet和主干网ResNet各个Stage输出之间的是Long-term的Identity Mapping。
实验结果如何?RefineNet采用了交并比(IoU)、像素准确率和平均准确率在多个数据集上(如【2】【3】等)进行了分割相关的实验。
(1)对象分析任务
标注的位置为头、躯干、上下臂和上下腿,从上图的预测结果中可以看出RefineNet效果非常好,非常准确的预测出了各个部位。
(2)语义分割RefineNet提供了多个标准数据集的结果,定量指标值均非常出色,比如在SUN-RGBD数据集的结果如下:
- 术语“消融研究”通常用于神经网络,尤其是相对复杂的神经网络,如R-CNN。我们的想法是通过删除部分网络并研究网络的性能来了解网络。
- 消融实验类似于“控制变量法”:假设在某目标检测系统中,使用了A,B,C,取得了不错的效果,但是这个时候你并不知道这不错的效果是由于A,B,C中哪一个起的作用,于是你保留A,B,移除C进行实验来看一下C在整个系统中所起的作用。
RefineNet是一种灵活的级联结构,下表展示了几种连接方式下的表现:
RefineNet网络做很少的修改就可以变化到不同的结构(论文主要介绍的是4个Stage的RefineNet),比如如上图,把网络中的RefineNet块的个数修改一下就得到了变种a和b,把输入图片的个数和分辨率修改一下就可以得到变种c。
总结RefineNet采用多路,多分辨率,Cascade Refine和广泛使用残差结构的网络做语义分割任务,取得了很好的效果。其提出的RefineNet块,也可以以一个基础块的方式嵌入到别的网络中去。另外,RefineNet这个网络还可以做很多不同的泛化和拓展。
参考:
语义分割经典——RefineNet详解 https://zhuanlan.zhihu.com/p/113212821?from_voters_page=true
图像分割之RefineNet 论文笔记 https://zhuanlan.zhihu.com/p/69976076
用RefineNet做分割 https://zhuanlan.zhihu.com/p/84584467

