
点赞再看,养成习惯,您动动手指对原创作者意义非凡🤝 备战秋招面试 微信搜索公众号【TechGuide】关注更多新鲜好文和互联网大厂的笔经面经。 作者@TechGuide
当你的才华还撑不起你的野心时,你应该静下心去学习 。- 前言
- 正文
- 一、高维映射
- 二、什么叫核函数
- 三、只有核函数K的优化问题
- 四、测试样本X流程
- 五、总结
- 1)训练阶段
- 2)测试阶段
之前本系列也有简单提过SVM处理非线性问题,我在这篇文章会用最简单明了的语言讲明白非线性分类问题的解决方法,以及为什么要引入核函数,什么是核技巧,最后会总结一下SVM算法,拎出重点,把脉络梳理清楚。
正文建议在看这篇之前,把通俗讲解支持向量机SVM(二)对偶性的几何解释 看一下,对SVM的对偶性有一个直观的理解,接下来会顺畅很多。好啦!准备好了吗?耐下心来,咱们开始!
一、高维映射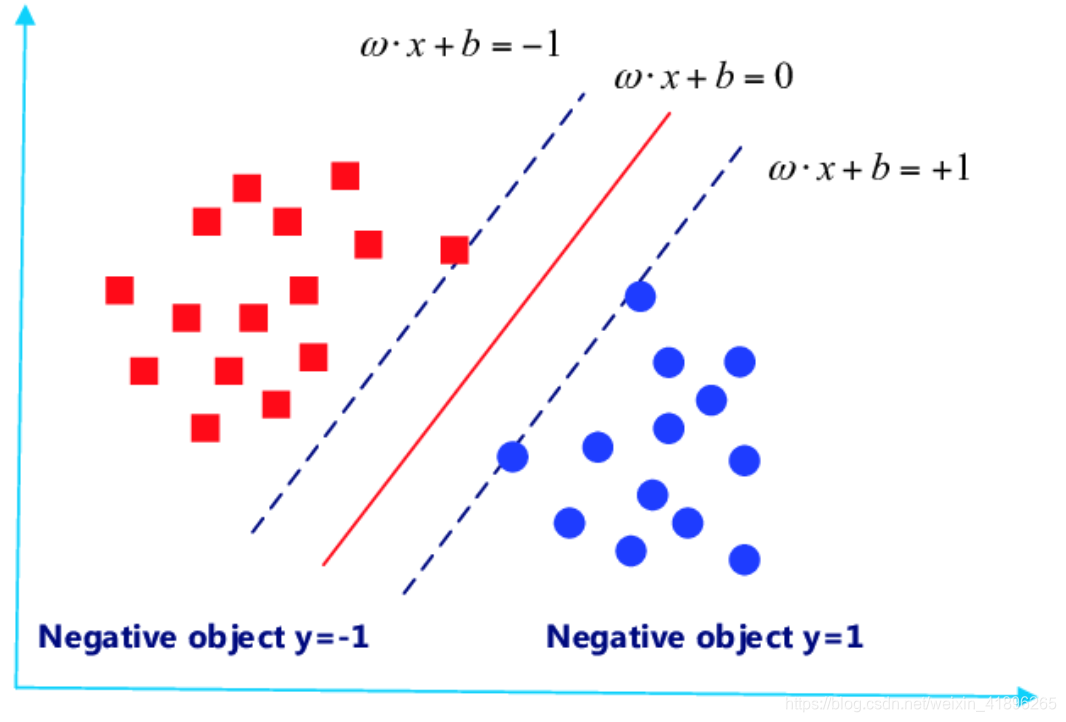 现在我们抛出一个例子,引出问题。先考虑情况一,我们可以很容易的将如上的样本集分类,用一个线性分类器即可。但是如下图的情况二呢?很明显,无法找到一条二维的线性直线将蓝黑两类点分类正确。
现在我们抛出一个例子,引出问题。先考虑情况一,我们可以很容易的将如上的样本集分类,用一个线性分类器即可。但是如下图的情况二呢?很明显,无法找到一条二维的线性直线将蓝黑两类点分类正确。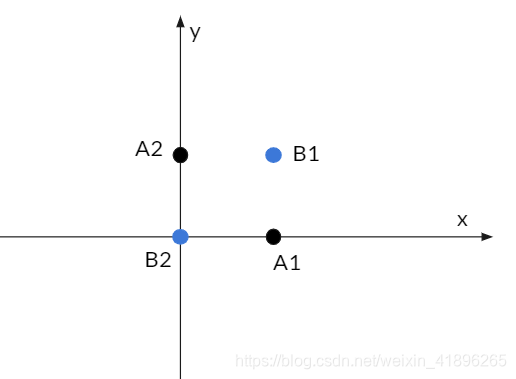 怎么办呢?是的没错!就是用高维映射
φ
(
)
\varphi ()
φ(),我们将二维坐标点A1(1,0),A2(0,1),B1(1,1),B2(0,0)
[
x
y
]
\left[ \begin{matrix} x \\ y \\ \end{matrix} \right]
[xy] 转化到高维空间就可以用直线划分,比如转化为五维坐标点:
φ
(
X
)
=
φ
(
A
or
B
)
=
[
x
2
y
2
x
y
x
y
]
(1)
\varphi(X) =\varphi(A \text{or} B) = \left[ \begin{matrix} x^2 \\ y^2 \\ x \\ y \\ xy \\ \end{matrix} \right] \tag 1
φ(X)=φ(AorB)=⎣⎢⎢⎢⎢⎡x2y2xyxy⎦⎥⎥⎥⎥⎤(1) 这样,我们得到转化到五维的四个坐标点,接着,我们再找到一条在五维的直线(
ω
\omega
ω , b)将这四个点分开,以什么为标准呢?参照二维情况,这里我们用:
{
ω
T
φ
(
X
)
+
b
≥
1
点X
∈
类C1
ω
T
φ
(
X
)
+
b
<
1
点X
∈
类C2
(2)
\begin{cases} \omega^T\varphi(X)+b \geq 1& \text{点X} \in \text{类C1}\\ \omega^T\varphi(X)+b < 1& \text{点X} \in \text{类C2} \end{cases} \tag 2
{ωTφ(X)+b≥1ωTφ(X)+b
ω
=
∑
i
=
1
N
α
i
y
i
φ
(
X
i
)
\frac{\partial \Theta}{\partial \omega} = 0 ------>\omega=\sum_{i=1}^{N}\alpha_iy_i\varphi(X_i)
∂ω∂Θ=0−−−−−−>ω=i=1∑Nαiyiφ(Xi)
∂
Θ
∂
ζ
=
0
−
−
−
−
−
−
>
α
i
+
β
i
=
C
(5)
\frac{\partial \Theta}{\partial \zeta} = 0------>\alpha_i + \beta_i = C \tag 5
∂ζ∂Θ=0−−−−−−>αi+βi=C(5)
∂
Θ
∂
b
=
0
−
−
−
−
−
−
>
∑
i
=
1
N
α
i
y
i
=
0
\frac{\partial \Theta}{\partial b} = 0------>\sum_{i=1}^{N}\alpha_iy_i=0
∂b∂Θ=0−−−−−−>i=1∑Nαiyi=0我觉得大家都明白,求导比较繁琐,但肯定不难,稍耐心,肯定能得出正确结果,大家不妨算一算,看看和给出的结果是否一致。 所以,依照求导的结果代入后获得的应该是下确界的值,在maxmize它,再次改写优化问题,约掉
β
\beta
β,用的是(5)式:
Maxmize
Θ
(
α
i
)
=
∑
i
=
1
N
α
i
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
K
(
X
i
,
X
j
)
\text{Maxmize} \,\Theta(\alpha_i) =\sum_{i=1}^N\alpha_i-\frac{1}{2} \sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_i\alpha_jy_iy_jK(X_i,X_j)
MaxmizeΘ(αi)=i=1∑Nαi−21i=1∑Nj=1∑NαiαjyiyjK(Xi,Xj)
Subject to:
0
≤
α
i
≤
C
\text{Subject to:\,\,\,}0 \leq \alpha_i \leq C
Subject to:0≤αi≤C
∑
i
=
1
N
α
i
y
i
=
0
\sum_{i=1}^{N}\alpha_iy_i=0
i=1∑Nαiyi=0 ,再次分析一波,上式中yi,yj是label,已知的值。核函数K则是一开始用户确定采用的那一种核函数(比如常见的高斯核函数和多项式核函数等),而待求的则是
α
i
,
α
j
\alpha_i,\alpha_j
αi,αj,细心的朋友可能已经发现了,优化问题中的
φ
(
X
)
\varphi(X)
φ(X)都慢慢“消失”,被核函数K(X1,X2)代替,这就是前面我们折腾半天的原因,
避
开
φ
(
X
)
,
用
K
代
替
,
这
也
是
全
篇
的
核
心
所
在
!
!
!
!
!
{\color{red} 避开\varphi(X),用K代替,这也是全篇的核心所在!!!!!}
避开φ(X),用K代替,这也是全篇的核心所在!!!!!
怎么办呢?是的没错!就是用高维映射
φ
(
)
\varphi ()
φ(),我们将二维坐标点A1(1,0),A2(0,1),B1(1,1),B2(0,0)
[
x
y
]
\left[ \begin{matrix} x \\ y \\ \end{matrix} \right]
[xy] 转化到高维空间就可以用直线划分,比如转化为五维坐标点:
φ
(
X
)
=
φ
(
A
or
B
)
=
[
x
2
y
2
x
y
x
y
]
(1)
\varphi(X) =\varphi(A \text{or} B) = \left[ \begin{matrix} x^2 \\ y^2 \\ x \\ y \\ xy \\ \end{matrix} \right] \tag 1
φ(X)=φ(AorB)=⎣⎢⎢⎢⎢⎡x2y2xyxy⎦⎥⎥⎥⎥⎤(1) 这样,我们得到转化到五维的四个坐标点,接着,我们再找到一条在五维的直线(
ω
\omega
ω , b)将这四个点分开,以什么为标准呢?参照二维情况,这里我们用:
{
ω
T
φ
(
X
)
+
b
≥
1
点X
∈
类C1
ω
T
φ
(
X
)
+
b
<
1
点X
∈
类C2
(2)
\begin{cases} \omega^T\varphi(X)+b \geq 1& \text{点X} \in \text{类C1}\\ \omega^T\varphi(X)+b < 1& \text{点X} \in \text{类C2} \end{cases} \tag 2
{ωTφ(X)+b≥1ωTφ(X)+b
ω
=
∑
i
=
1
N
α
i
y
i
φ
(
X
i
)
\frac{\partial \Theta}{\partial \omega} = 0 ------>\omega=\sum_{i=1}^{N}\alpha_iy_i\varphi(X_i)
∂ω∂Θ=0−−−−−−>ω=i=1∑Nαiyiφ(Xi)
∂
Θ
∂
ζ
=
0
−
−
−
−
−
−
>
α
i
+
β
i
=
C
(5)
\frac{\partial \Theta}{\partial \zeta} = 0------>\alpha_i + \beta_i = C \tag 5
∂ζ∂Θ=0−−−−−−>αi+βi=C(5)
∂
Θ
∂
b
=
0
−
−
−
−
−
−
>
∑
i
=
1
N
α
i
y
i
=
0
\frac{\partial \Theta}{\partial b} = 0------>\sum_{i=1}^{N}\alpha_iy_i=0
∂b∂Θ=0−−−−−−>i=1∑Nαiyi=0我觉得大家都明白,求导比较繁琐,但肯定不难,稍耐心,肯定能得出正确结果,大家不妨算一算,看看和给出的结果是否一致。 所以,依照求导的结果代入后获得的应该是下确界的值,在maxmize它,再次改写优化问题,约掉
β
\beta
β,用的是(5)式:
Maxmize
Θ
(
α
i
)
=
∑
i
=
1
N
α
i
−
1
2
∑
i
=
1
N
∑
j
=
1
N
α
i
α
j
y
i
y
j
K
(
X
i
,
X
j
)
\text{Maxmize} \,\Theta(\alpha_i) =\sum_{i=1}^N\alpha_i-\frac{1}{2} \sum_{i=1}^{N}\sum_{j=1}^{N}\alpha_i\alpha_jy_iy_jK(X_i,X_j)
MaxmizeΘ(αi)=i=1∑Nαi−21i=1∑Nj=1∑NαiαjyiyjK(Xi,Xj)
Subject to:
0
≤
α
i
≤
C
\text{Subject to:\,\,\,}0 \leq \alpha_i \leq C
Subject to:0≤αi≤C
∑
i
=
1
N
α
i
y
i
=
0
\sum_{i=1}^{N}\alpha_iy_i=0
i=1∑Nαiyi=0 ,再次分析一波,上式中yi,yj是label,已知的值。核函数K则是一开始用户确定采用的那一种核函数(比如常见的高斯核函数和多项式核函数等),而待求的则是
α
i
,
α
j
\alpha_i,\alpha_j
αi,αj,细心的朋友可能已经发现了,优化问题中的
φ
(
X
)
\varphi(X)
φ(X)都慢慢“消失”,被核函数K(X1,X2)代替,这就是前面我们折腾半天的原因,
避
开
φ
(
X
)
,
用
K
代
替
,
这
也
是
全
篇
的
核
心
所
在
!
!
!
!
!
{\color{red} 避开\varphi(X),用K代替,这也是全篇的核心所在!!!!!}
避开φ(X),用K代替,这也是全篇的核心所在!!!!!
OK,整理清楚思路,这个问题就很好解了,回归文章开头,我们在测试样本属于哪一类时,用的标准是 { ω T φ ( X i ) + b ≥ 1 y i = + 1 ω T φ ( X i ) + b < 1 y i = − 1 (6) \begin{cases} \omega^T\varphi(X_i)+b \geq 1& y_i=+1\\ \omega^T\varphi(X_i)+b < 1& y_i=-1 \end{cases} \tag 6 {ωTφ(Xi)+b≥1ωTφ(Xi)+b 0 \beta_i = C-\alpha_i > 0 βi=C−αi>0,所以根据KKT条件, ζ i = 0 , and D = 0 \zeta_i=0 ,\text{and} D = 0 ζi=0,andD=0,由此可得出 b = 1 − y i ∑ i = 1 N α j y j K ( X i , X j ) y i b=\frac{1-y_i\sum_{i=1}^{N}\alpha_jy_jK(X_i,X_j)}{y_i} b=yi1−yi∑i=1NαjyjK(Xi,Xj)
五、总结感谢你一路看到现在,我们对SVM算法做出最后的总结,帮助加深理解:
1)训练阶段输入样本集(Xi,yi),解优化问题,得到所有的N个 α i \alpha_i αi,并由此得到 β i 和 b \beta_i和b βi和b
2)测试阶段输入你想要测试的样本X,再根据(6)分类器: { ω T φ ( X i ) + b ≥ 1 y i = + 1 ω T φ ( X i ) + b < 1 y i = − 1 \begin{cases} \omega^T\varphi(X_i)+b \geq 1& y_i=+1\\ \omega^T\varphi(X_i)+b < 1& y_i=-1 \end{cases} {ωTφ(Xi)+b≥1ωTφ(Xi)+b
最近更新
- 深拷贝和浅拷贝的区别(重点)
- 【Vue】走进Vue框架世界
- 【云服务器】项目部署—搭建网站—vue电商后台管理系统
- 【React介绍】 一文带你深入React
- 【React】React组件实例的三大属性之state,props,refs(你学废了吗)
- 【脚手架VueCLI】从零开始,创建一个VUE项目
- 【React】深入理解React组件生命周期----图文详解(含代码)
- 【React】DOM的Diffing算法是什么?以及DOM中key的作用----经典面试题
- 【React】1_使用React脚手架创建项目步骤--------详解(含项目结构说明)
- 【React】2_如何使用react脚手架写一个简单的页面?

